Clear Sky Science · pt
TigCLaF: uma estrutura de modelo grande multilíngue para classificação de texto sensível ao sentimento em tigrínia com poucos recursos
Por que isso importa além da ciência da computação
Cotidianamente, pessoas que falam tigrínia compartilham suas esperanças, medos e opiniões em redes sociais e sites de notícias. Ainda assim, a maioria dos sistemas modernos de inteligência artificial não consegue ler corretamente essas mensagens, porque a língua tem muito menos recursos digitais do que o inglês ou o chinês. Este artigo apresenta o TigCLaF, uma nova estrutura que ensina modelos de linguagem grandes a entender o tom emocional do texto em tigrínia de forma eficiente, usando dados limitados e potência computacional modesta. O trabalho oferece um modelo para levar tecnologia linguística poderosa a muitas outras línguas sub-representadas.
Transformando dados escassos em vantagem
O desafio central que os autores enfrentam é a classificação de texto sensível ao sentimento em um cenário de poucos recursos. Isso significa identificar automaticamente se um trecho de texto expressa um sentimento positivo, negativo ou neutro, preservando sinais emocionais sutis. Para o tigrínia, isso é difícil: há poucos conjuntos de dados rotulados, a escrita ge’ez tem regras próprias de pontuação e espaçamento, e o sentimento frequentemente aparece em forma de expressões idiomáticas e referências culturais. Modelos convencionais presumem conjuntos de treinamento enormes e ferramentas bem desenvolvidas, por isso falham nesses materiais. O TigCLaF responde reaproveitando conhecimento de modelos multilingues treinados em línguas com muitos dados e adaptando-o cuidadosamente ao tigrínia sem re-treinar tudo do zero.
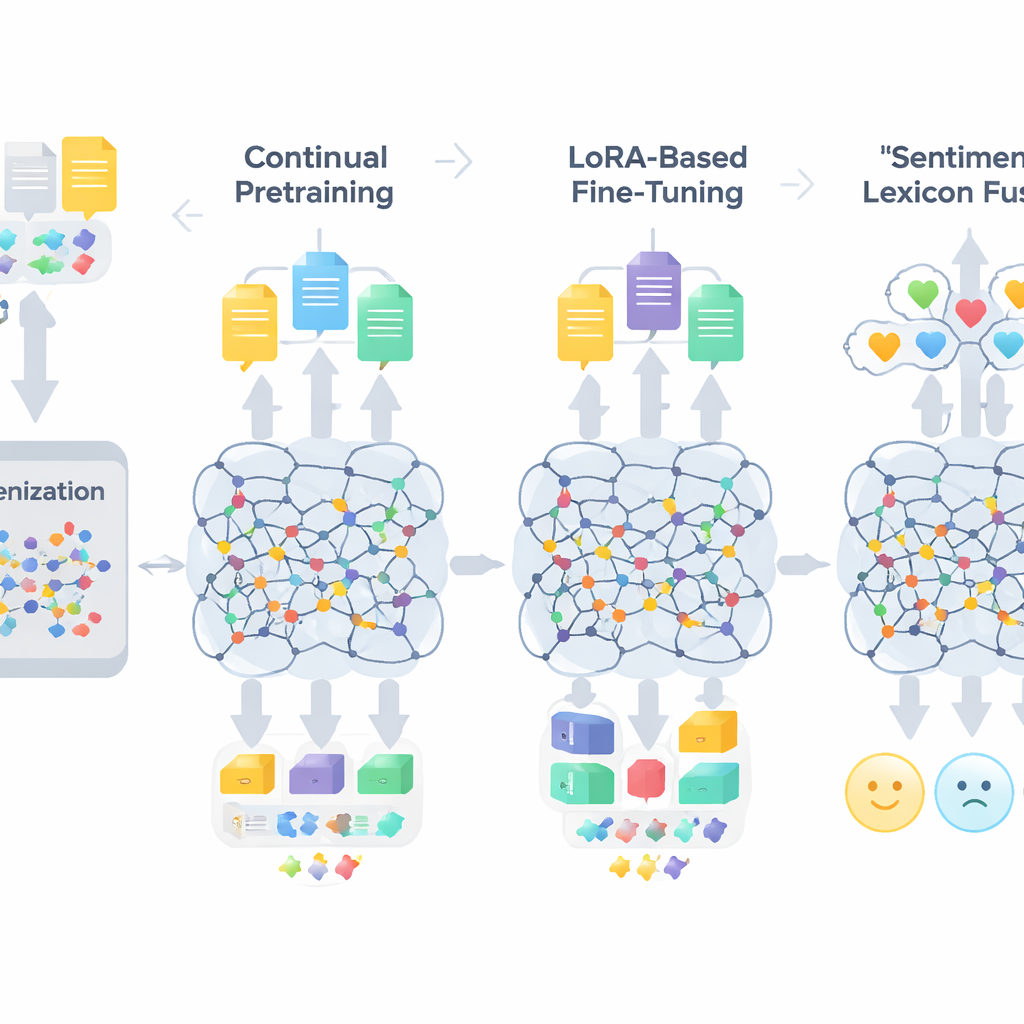
Uma receita em três etapas para adaptar grandes modelos
O fluxo de trabalho do TigCLaF consiste em três fases estreitamente conectadas. Primeiro, os autores estendem o tokenizer do modelo — a parte que divide o texto em unidades — adicionando milhares de subwords tigrínia de uso frequente. Isso reduz divisões estranhas de palavras escritas em ge’ez e melhora como a língua é representada na rede. Segundo, eles continuam o pré-treinamento do modelo multilingue em uma mistura composta majoritariamente por tigrínia, com alguma presença de inglês e amárico. Nessa etapa, o sistema tanto prevê palavras mascaradas quanto aprende a aproximar sentenças correspondentes entre línguas em seu espaço interno, fortalecendo o alinhamento cross-lingual. Terceiro, em vez de atualizar todos os pesos do modelo, aplicam uma técnica chamada LoRA, que adiciona pequenos módulos adaptadores às camadas de atenção e feed-forward. Apenas essas peças leves são treinadas no conjunto de dados de sentimento tigrínia com 30.000 instâncias, reduzindo dramaticamente a necessidade de memória e computação.
Ensinando explicitamente o modelo sobre emoções
Além da adaptação linguística geral, a estrutura injeta conhecimento explícito sobre emoções. Os autores constroem um léxico de sentimento compacto em tigrínia com cerca de 3.200 entradas, combinando uma lista de palavras criada manualmente com projeções a partir de recursos em inglês e amárico. Cada entrada carrega uma pontuação de polaridade indicando quão positiva ou negativa tende a ser. Durante o treinamento, o sistema mapeia tokens a essas pistas de polaridade, trata negações e intensificadores e então funde essas características com as embeddings contextuais do modelo. Um mecanismo com portas aprende quanto peso dar aos indícios lexicais de sentimento em comparação ao contexto ao redor em cada posição, o que ajuda em casos complexos como sarcasmo, expressões idiomáticas e palavras morfologicamente complexas.
Como isso funciona na prática
Para testar o TigCLaF, os autores curaram um novo corpus de sentimento em tigrínia a partir de redes sociais e veículos de notícias entre 2023 e 2025, limpando cuidadosamente os dados e fazendo com que falantes nativos rotulassem cada publicação. Eles comparam sua estrutura com fortes baselines multilíngues, incluindo mBERT, XLM-RoBERTa, AfriBERTa e modelos LLaMA usados tanto com prompting em contexto quanto com seu próprio ajuste eficiente em parâmetros. O TigCLaF alcança o melhor desempenho geral, elevando a pontuação macro F1 em até cerca de sete pontos percentuais em relação aos melhores baselines baseados em transformers, enquanto atualiza apenas cerca de seis por cento dos parâmetros. Estudos de ablação mostram que cada componente contribui: o pré-treinamento contínuo fornece o maior ganho, a adaptação do tokenizer e o alinhamento cross-lingual aumentam ainda mais a robustez, e a fusão com o léxico de sentimento melhora consistentemente o tratamento de conteúdo emocional nuançado. A estrutura também transfere bem para amárico e inglês em cenários zero-shot e few-shot e degrada de forma suave quando apenas uma fração dos dados de treinamento em tigrínia está disponível.
Do experimento de laboratório ao impacto no mundo real
Além dos números brutos, o artigo explora onde o modelo ainda tem dificuldades — como forte alternância de código, sarcasmo e mudanças de domínio entre notícias e conversas informais — e argumenta que melhor normalização, modelagem de linguagem figurativa e adaptação de domínio poderiam reduzir ainda mais os erros. Crucialmente, o TigCLaF roda de forma eficiente em hardware comum graças ao LoRA e à quantização, tornando-o prático para instituições e comunidades em regiões de fala tigrínia. Os autores concluem que sua estrutura é tanto um sistema funcional de análise de sentimento para tigrínia quanto um roteiro para estender tecnologias linguísticas modernas a muitas outras línguas africanas com poucos recursos, ajudando a garantir que não sejam deixadas para trás na era da IA.
Citação: Gebremeskel, H.G., Feng, C., Abera, A.M. et al. TigCLaF: a cross-lingual large language model framework for sentiment-aware text classification in low-resource tigrigna. Sci Rep 16, 12953 (2026). https://doi.org/10.1038/s41598-026-42786-4
Palavras-chave: Análise de sentimento em Tigrínia, PNL para línguas com poucos recursos, aprendizado por transferência cross-lingual, modelos de linguagem grandes, ajuste fino eficiente em parâmetros