Clear Sky Science · he
TigCLaF: מסגרת מודל שפה גדול חוצה-שפות למיון טקסטים לפי סנטימנט בשפה טיגרינית במשאבים מועטים
מדוע זה חשוב מעבר למחשוב
כל יום דוברי טיגרינית משתפים תקוות, פחדים ודעות ברשתות חברתיות ובאתרי חדשות. עם זאת, רוב מערכות הבינה המלאכותית המודרניות אינן מסוגלות לקרוא מסרים אלה כראוי, כי לשפה יש משאבים דיגיטליים הרבה פחותים מאשר לאנגלית או לסינית. מאמר זה מציג את TigCLaF, מסגרת חדשה שמלמדת מודלים שפתיים גדולים להבין את הטון הרגשי של טקסט טיגריני ביעילות, באמצעות נתונים מצומצמים וכוח מחשוב צנוע. העבודה מציעה תבנית להבאת טכנולוגיות שפה עוצמתיות לרבות שפות שאינן מיוצגות כראוי.
להפוך נתונים מועטים לחוזקה
האתגר המרכזי שהמחברים מתמודדים איתו הוא מיון טקסט לפי סנטימנט בסביבה של משאבים מועטים. כלומר, להחליט באופן אוטומטי האם טקסט מביע רגש חיובי, שלילי או ניטרלי תוך שמירה על רמזים רגשיים עדינים. עבור טיגרינית זה קשה: יש מעט מערכי תיוג, כתב גֵאֶז (Ge’ez) מציב כללי פיסוק וריווח משלו, וסנטימנט מופיע לעיתים דרך ביטויים אידיומטיים והתייחסויות תרבותיות. מודלים קונבנציונליים מניחים מערכי אימון עצומים וכלים מפותחים, ולכן מתקשים בחומר כזה. TigCLaF מגיב על ידי שימוש חוזר בידע ממודלים רב-לשוניים שאומנו על שפות עשירות בנתונים והתאמתו בזהירות לטיגרינית מבלי לאמן מחדש את כל המודל.
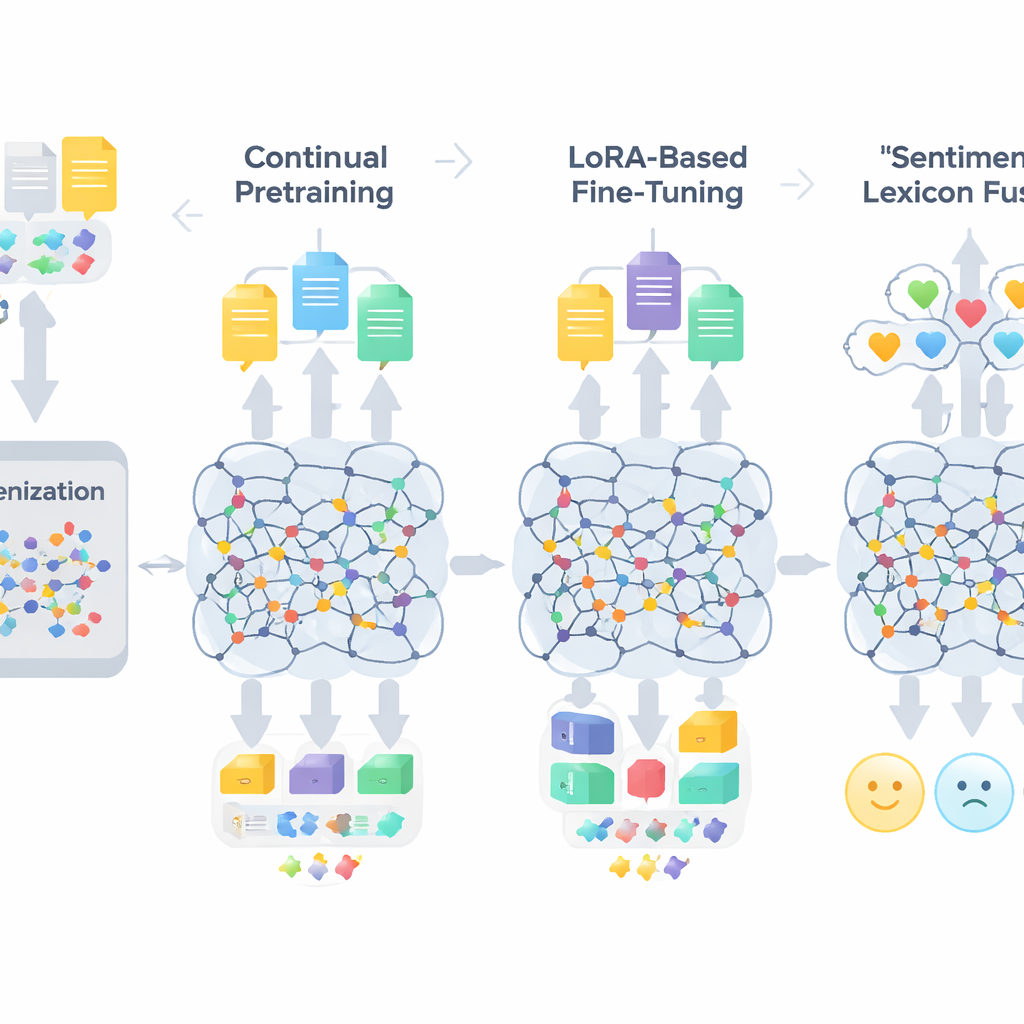
מתכון בשלושה שלבים להתאמת מודלים גדולים
זרימת העבודה של TigCLaF מורכבת משלושה שלבים מקושרים זה לזה. ראשית, המחברים מרחיבים את המקטעור (tokenizer) של המודל — החלק שמפרק טקסט ליחידות — על ידי הוספת אלפי תתי-מילים טיגריניות נפוצות. זה מצמצם פירוק לא-נעים של מילים בכתב גֵאֶז ומשפר את הייצוג של השפה בתוך הרשת. שנית, הם ממשיכים באימון המשך (continual pretraining) של המודל הרב-לשוני על תערובת שמורכבת בעיקר מטיגרינית, ובמידה פחותה מאנגלית ואמהרית. בשלב זה המערכת גם משחזרת מילים מוסתרות וגם לומדת לקרב משפטים מתאימים משפות שונות במרחב הפנימי שלה, מה שמחזק יישור חוצה-שפות. שלישית, במקום לעדכן את כל משקלי המודל, הם מיישמים טכניקת LoRA, שמוסיפה מודולי מתאם קטנים לשכבות תשומת-לב ולשכבות ההזנה קדימה. רק חתיכות קלות משקל אלה מאומנות על מערך הנתונים הטיגריני של 30,000 הדוגמאות, מה שמצמצם משמעותית את דרישות הזכרון והחישוב.
להדריך את המודל לגבי רגשות במפורש
מעבר להתאמת השפה הכללית, המסגרת מזריקה ידע מפורש על רגשות. המחברים בונים לקסיקון סנטימנט טיגריני קומפקטי של כ-3,200 פריטים על ידי שילוב רשימת מילים בעבודת יד עם השערות משאבים באנגלית ובאמהרית. כל פריט נושא ציון פולאריות שמצביע על נטייתו החיובית או השלילית. במהלך האימון המערכת ממפה טוקנים לרמזי פולאריות אלה, מטפלת בשלילה ומחזקנים, ואחר כך ממזגת תכונות אלה עם ההטמעות הקונטקסטואליות של המודל. מנגנון ממוקד (gated) לומד כמה משקל לתת לרמזי הלקסיקון לעומת ההקשר הסובב בכל מיקום, מה שעוזר במקרים מורכבים כמו סרקזם, אידיומות ומילים בעלות מורפולוגיה מורכבת.
כמה טוב זה עובד בפועל
כדי לבדוק את TigCLaF, המחברים אוספים קורפוס סנטימנט טיגריני חדש מרשתות חברתיות ומקורות חדשות בין 2023 ל-2025, מנקים את הנתונים בקפידה ומבקשים דוברים ילידים לתייג כל פוסט. הם משווים את המסגרת שלהם מול בסיסים רב-לשוניים חזקים, כולל mBERT, XLM-RoBERTa, AfriBERTa, ודגמי LLaMA שנבדקו הן בעידוד בתוך-הקשר והן בכיול פרמטר-יעיל משלהם. TigCLaF משיג את הביצועים הטובים ביותר בכלל המדדים, ומשפר את ציון ה-macro F1 בעד כ-7 נקודות אחוז לעומת מיטב הבסיסים הטרנספורמריים, בעוד מעדכן רק כ-6% מהפרמטרים בסביבות אלה. מחקרי חיסול (ablation) מראים שכל רכיב תורם: האימון ההמשכי נותן את הדחיפה הגדולה ביותר, התאמת המקטעור ויישור חוצה-שפות מחזקים את העמידות, ומיזוג לקסיקון הסנטימנט משפר בהתמדה את הטיפול בתוכן רגשי מעודן. המסגרת גם עוברת היטב לאמהרית ולאנגלית במצבי zero-shot ו-few-shot ומידרדרת בעדינות כאשר זמין רק חלק ממאגר האימון הטיגריני.
מניסוי במעבדה להשפעה במציאות
מעבר למספרים גולמיים, המאמר בוחן היכן המודל עדיין מתקשה — כגון ערבוב כבד של שפות (code-switching), סרקזם ושינוי תחום בין חדשות לשיחות בלתי פורמליות — וטוען כי נירמול טוב יותר, מודלינג של שפה דמיונית והסתגלות לתחום יכולים להפחית שגיאות נוספות. חשוב לציין, TigCLaF רץ ביעילות על חומרה צרכנית הודות ל-LoRA ולקוואנטיזציה, מה שהופך אותו מעשי למוסדות ולקהילות באזורים דוברי טיגרינית. המחברים מסכמים שהמסגרת שלהם מהווה גם מערכת מיון סנטימנט עובדת לטיגרינית וגם תבנית להרחבת טכנולוגיות שפה מודרניות לרבות שפות אפריקאיות במשאבים מועטים, ובכך מסייעת להבטיח שלא יושארו מאחור בעידן הבינה המלאכותית.
ציטוט: Gebremeskel, H.G., Feng, C., Abera, A.M. et al. TigCLaF: a cross-lingual large language model framework for sentiment-aware text classification in low-resource tigrigna. Sci Rep 16, 12953 (2026). https://doi.org/10.1038/s41598-026-42786-4
מילות מפתח: ניתוח סנטימנט בטיגרינית, עיבוד שפה טבעית לשפות במשאבים מועטים, למידה העברתית חוצה-שפות, מודלים שפתיים גדולים, כיול פרמטר-יעיל