Clear Sky Science · tr
TigCLaF: düşük kaynaklı Tigrinya’da duygu farkındalıklı metin sınıflandırması için çapraz-dillere uygun büyük dil modeli çerçevesi
Bilgisayar biliminin ötesinde neden önemli
Günlük olarak Tigrinya konuşan insanlar sosyal medyada ve haber sitelerinde umutlarını, korkularını ve görüşlerini paylaşıyor. Ancak modern yapay zekâ sistemlerinin çoğu bu mesajları doğru okumakta zorlanıyor; çünkü Tigrinya dijital kaynaklar bakımından İngilizce veya Çince kadar zengin değil. Bu makale, sınırlı veri ve makul düzeyde hesaplama gücüyle büyük dil modellerine Tigrinya metninin duygusal tonunu verimli biçimde öğretmeyi sağlayan yeni bir çerçeve olan TigCLaF’ı sunuyor. Bu çalışma, güçlü dil teknolojilerini diğer pek çok az temsil edilen dile taşımak için bir şablon sunuyor.
Kıt veriyi bir avantaja dönüştürmek
Yazarların ele aldığı temel zorluk, düşük-kaynaklı bir ortamda duygu farkındalıklı metin sınıflandırması yapmak. Bu, bir metnin olumlu, olumsuz veya nötr duygu ifade edip etmediğini otomatik olarak belirlemeyi ve aynı zamanda ince duygusal ipuçlarını korumayı gerektirir. Tigrinya için bu zor: etiketlenmiş veri kümeleri sınırlı, Ge’ez yazısının noktalama ve boşluk kuralları kendine özgü ve duygu sık sık deyimler ve kültürel göndermelerle ifade ediliyor. Geleneksel modeller büyük eğitim setleri ve iyi gelişmiş araçlar varsaydığı için bu tür materyallerde başarısız oluyor. TigCLaF, veri açısından zengin dillerde eğitilmiş çokdilli modellerden bilgiyi yeniden kullanarak ve her şeyi baştan eğitmek yerine dikkatli biçimde Tigrinya’ya uyarlayarak buna yanıt veriyor.
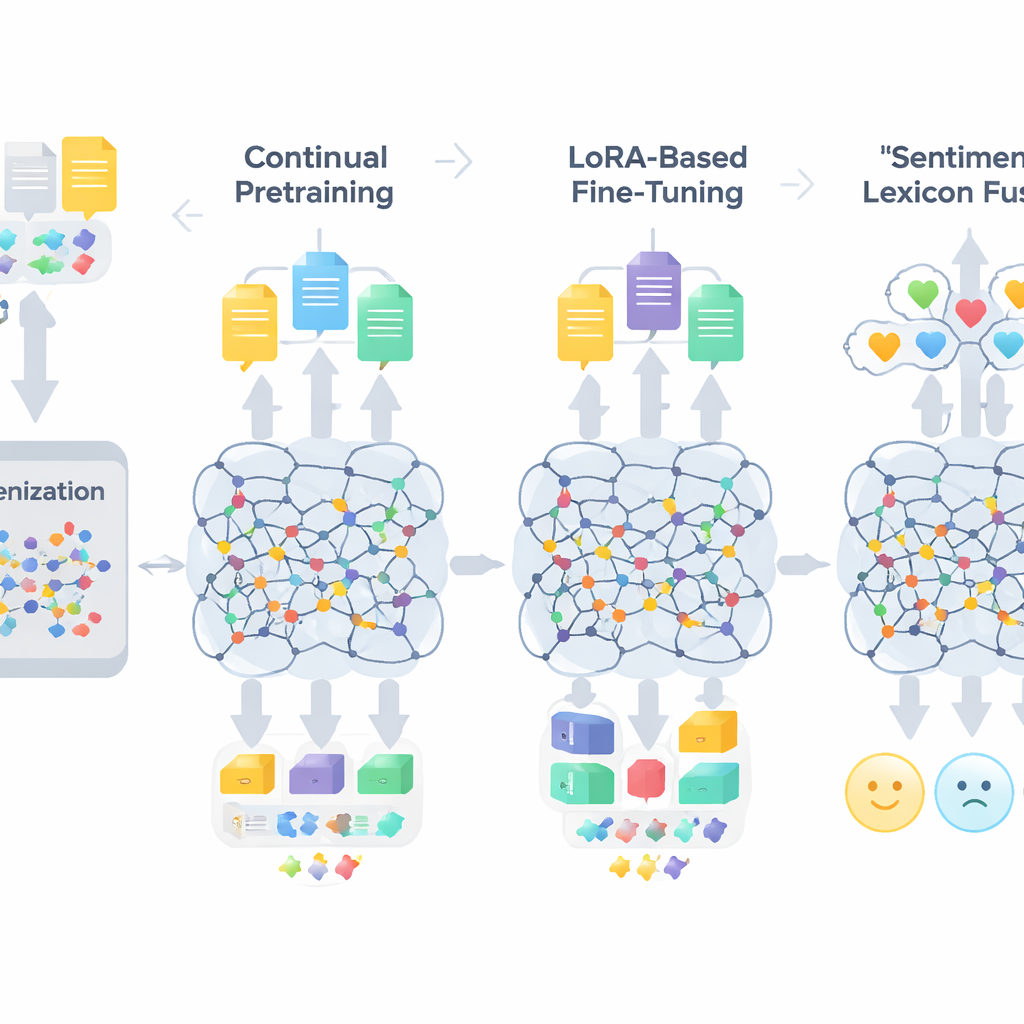
Büyük modelleri uyarlamak için üç aşamalı reçete
TigCLaF’in iş akışı birbirine sıkı bağlı üç aşamadan oluşuyor. Önce, metni birimlere ayıran tokenizer’ı—yani tokenleştiriciyi—binlerce sık kullanılan Tigrinya alt-kelimesi ekleyerek genişletiyorlar. Bu, Ge’ez yazılı kelimelerin uygunsuz bölünmesini azaltıyor ve dilin ağ içindeki temsilini iyileştiriyor. İkinci olarak, çokdilli modeli ağırlıklı olarak Tigrinya, ayrıca biraz İngilizce ve Amharic karışımı bir veri üzerinde sürekli ön-eğitime tabi tutuyorlar. Bu aşamada sistem hem maskelenmiş kelimeleri dolduruyor hem de diller arasındaki eşleşen cümleleri iç mekânda birbirine yaklaştırmayı öğrenerek çapraz-dil hizalanmasını güçlendiriyor. Üçüncü olarak, tüm model ağırlıklarını güncellemek yerine LoRA adlı bir teknik uyguluyorlar; bu, dikkat (attention) ve ileri beslemeli (feed-forward) katmanlara küçük adaptör modülleri ekliyor. Sadece bu hafif parçalar yaklaşık 30.000 örnekten oluşan Tigrinya duygu veri kümesi üzerinde eğitiliyor ve bellek ile hesaplama ihtiyacını büyük ölçüde azaltıyor.
Modele duyguları açıkça öğretmek
Genel dil uyarlamasının ötesinde çerçeve, duygular hakkında açık bilgi enjekte ediyor. Yazarlar, el işi bir kelime listesi ile İngilizce ve Amharic kaynaklardan yapılan yansımaları birleştirerek yaklaşık 3.200 maddelik kompakt bir Tigrinya duygu sözlüğü oluşturuyor. Her madde, genellikle ne kadar olumlu ya da olumsuz olduğunu gösteren bir kutupsallık (polarity) puanı taşıyor. Eğitim sırasında sistem tokenleri bu kutupsallık ipuçlarına eşliyor, olumsuzlama ve şiddetlendiricileri (intensifier) ele alıyor ve ardından bu özellikleri modelin bağlamsal gömme (embedding) vektörleriyle kaynaştırıyor. Bir kapılı (gated) mekanizma, her pozisyonda sözcüksel duygu işaretlerine kıyasla çevresel bağlama ne kadar ağırlık verileceğini öğreniyor; bu, ironi, deyimler ve morfolojik olarak karmaşık kelimeler gibi zorlayıcı durumlarda yardımcı oluyor.
Uygulamada ne kadar iyi çalışıyor
TigCLaF’ı test etmek için yazarlar 2023–2025 arasında sosyal medya ve haber kaynaklarından yeni bir Tigrinya duygu korpusu derliyor, veriyi dikkatle temizliyor ve ana dili Tigrinya olan konuşurlardan her gönderiyi etiketlemelerini istiyorlar. Çerçevelerini mBERT, XLM-RoBERTa, AfriBERTa ve hem bağlam içi (in-context) yönlendirme hem de parametre-verimli ince ayar kullanan LLaMA modelleri dahil güçlü çokdilli dayanaklarla karşılaştırıyorlar. TigCLaF en iyi genel performansı elde ediyor; en iyi transformer dayanaklara göre makro F1 puanlarında yaklaşık yedi yüzde puana kadar artış sağlıyor ve yalnızca yaklaşık yüzde altı gibi küçük bir parametre dilimini güncelleyerek çalışıyor. Ablasyon çalışmaları her bileşenin katkıda bulunduğunu gösteriyor: sürekli ön-eğitim en büyük artışı sağlıyor, tokenizer uyarlaması ve çapraz-dil hizalanması sağlamlığı artırıyor ve duygu-sözlüğü kaynaştırması nüanslı duygusal içeriği tutarlı şekilde daha iyi işlemeyi sağlıyor. Çerçeve ayrıca sıfır-atış (zero-shot) ve birkaç-atış (few-shot) ayarlarında Amharic ve İngilizce’ye iyi aktarım gösteriyor ve yalnızca bir kısmı mevcut olduğunda Tigrinya eğitim verisi azaldığında bile performansı kademeli olarak bozuluyor.
Laboratuvar deneyinden gerçek dünya etkisine
Ham sayılardan öte, makale modelin hâlâ zorlandığı alanları—yoğun kod geçişleri (code-switching), ironi ve haberler ile gayri resmi konuşmalar arasındaki alan değişimleri gibi—inceliyor ve daha iyi normalizasyon, mecazi dil modelleme ve alan uyarlamasının hataları daha da azaltabileceğini savunuyor. Kritik olarak, TigCLaF LoRA ve kuantizasyon sayesinde sıradan donanımda verimli çalışıyor; bu da Tigrinya konuşulan bölgelerdeki kurumlar ve topluluklar için pratik olmasını sağlıyor. Yazarlar, çerçevenin hem Tigrinya için işler durumda bir duygu analizi sistemi hem de modern dil teknolojilerini diğer birçok düşük-kaynaklı Afrika diline genişletmek için bir yol haritası olduğunu; böylece bu dillerin yapay zekâ çağında geride kalmamasına yardımcı olacağını sonucuna bağlıyorlar.
Atıf: Gebremeskel, H.G., Feng, C., Abera, A.M. et al. TigCLaF: a cross-lingual large language model framework for sentiment-aware text classification in low-resource tigrigna. Sci Rep 16, 12953 (2026). https://doi.org/10.1038/s41598-026-42786-4
Anahtar kelimeler: Tigrinya duygu analizi, düşük-kaynaklı dil NLP’si, çapraz-dil aktarım öğrenimi, büyük dil modelleri, parametre-verimli ince ayar