Clear Sky Science · ja
TigCLaF: 低リソースなティグリニャ語における感情認識テキスト分類のための多言語大規模言語モデルフレームワーク
計算機科学を超えて重要な理由
日々、ティグリニャ語話者はソーシャルメディアやニュースサイト上で希望や不安、意見を共有しています。しかし、多くの現代的な人工知能システムはこれらのメッセージを適切に読み取れません。英語や中国語に比べてデジタル資源が著しく不足しているためです。本稿はTigCLaFを紹介します。これは、大規模言語モデルに対し、限られたデータと控えめな計算資源でティグリニャ語の感情的なトーンを効率的に理解させる新しいフレームワークです。本研究は、他の多くの十分に扱われていない言語にも強力な言語技術をもたらすためのモデルケースを提供します。
限られたデータを強みに変える
著者たちが取り組む中心的課題は、低リソース環境での感情認識テキスト分類です。これは、テキストが肯定的、否定的、あるいは中立的な感情を表しているかを自動的に判定しつつ、微妙な感情的手がかりを保持することを意味します。ティグリニャ語では困難が多く、ラベル付きデータセットは少なく、ゲエズ文字には独自の句読点やスペーシング規則があり、感情はしばしば慣用句や文化的参照を通じて表現されます。従来のモデルは大量の訓練データや成熟したツールを前提とするため、このような素材では性能が落ちます。TigCLaFは、データが豊富な言語で学習された多言語モデルの知識を再利用し、ゼロから全体を再学習することなく慎重にティグリニャ語へ適応させることでこの問題に応えます。
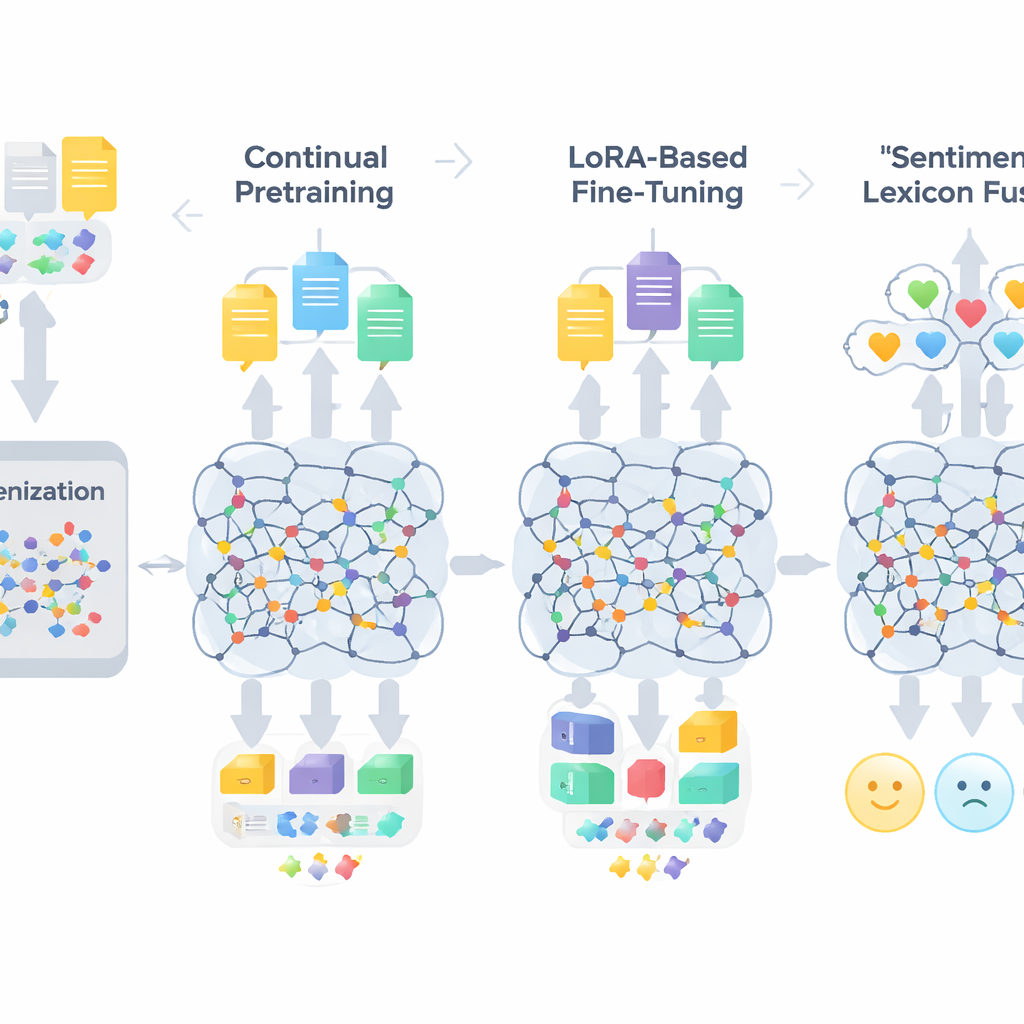
大規模モデルを適応させるための三段階の手順
TigCLaFのワークフローは三つの密接に連携した段階で構成されます。まず、トークナイザー(テキストを単位に分割する部分)を拡張し、頻出のティグリニャ部分語を数千個追加します。これによりゲエズ文字の単語が不自然に分割されることが減り、ネットワーク内部での言語表現が改善されます。次に、多くはティグリニャ語、少量の英語とアムハラ語を混ぜたコーパスで多言語モデルの継続事前学習を行います。この段階では、マスクされた語を予測すると同時に、複数言語にまたがる対応文を内部表現空間で近づけることを学び、クロスリンガルな整合性を強化します。第三に、全てのモデル重みを更新する代わりにLoRAと呼ばれる手法を適用し、アテンション層やフィードフォワード層に小さなアダプタモジュールを追加します。これらの軽量な部分のみを3万件のティグリニャ感情データで訓練することで、メモリと計算コストを劇的に削減します。
感情を明示的に教え込む
一般的な言語適応に加え、フレームワークは感情に関する明示的な知識を注入します。著者らは手作業の単語リストと英語・アムハラ語資源からの投影を組み合わせて、約3,200語のコンパクトなティグリニャ感情辞書を構築しました。各エントリは、その語が持つ傾向を示す極性スコアを備えています。訓練中、システムはトークンをこれらの極性ヒントにマッピングし、否定や強調表現を扱ったうえで、これらの特徴をモデルの文脈埋め込みと融合します。ゲート機構が語彙的な感情手がかりと周囲の文脈のどちらにどれだけ重みを置くかを学習し、皮肉や慣用表現、形態的に複雑な語の扱いなど難しいケースでの性能向上に寄与します。
実際の性能
TigCLaFを評価するために、著者らは2023年から2025年のソーシャルメディアとニュースから新たなティグリニャ感情コーパスを作成し、データを丁寧にクレンジングした上でネイティブ話者が各投稿にラベルを付けました。彼らはmBERT、XLM-RoBERTa、AfriBERTa、LLaMAなどの強力な多言語ベースライン(インコンテキストプロンプティングやパラメータ効率の良い調整を用いたものを含む)と比較しました。TigCLaFは全体で最高の性能を示し、マクロF1スコアを最高でトランスフォーマーベースラインより約7ポイント上げ、かつ更新するパラメータは約6%程度に抑えられました。アブレーション研究では各構成要素が寄与していることが示され、継続事前学習が最大の向上をもたらし、トークナイザー適応とクロスリンガル整合化が堅牢性をさらに高め、感情辞書の融合が微妙な感情表現の扱いを一貫して改善しました。フレームワークはゼロショットや数ショットの設定でもアムハラ語や英語へもうまく転移し、ティグリニャの訓練データが一部しか使えない場合でも性能はゆっくりと劣化しました。
研究室の実験から現場での影響へ
単なる数値以上に、論文はモデルが依然として苦戦する領域も検討しています。たとえば大幅なコードスイッチング、皮肉、ニュースと日常会話間のドメインシフトなどで、より良い正規化、比喩的表現のモデリング、ドメイン適応がさらなる誤り低減に役立つと論じています。重要なのは、LoRAや量子化のおかげでTigCLaFは汎用品のハードウェア上で効率的に動作し、ティグリニャ語話者の地域にある機関やコミュニティにとって実用的だという点です。著者らは、このフレームワークがティグリニャ語の実用的な感情分析システムであると同時に、現代の言語技術を多くの他の低リソースなアフリカ言語へ拡張するための設計図でもあり、AI時代に取り残されない手助けになると結論づけています。
引用: Gebremeskel, H.G., Feng, C., Abera, A.M. et al. TigCLaF: a cross-lingual large language model framework for sentiment-aware text classification in low-resource tigrigna. Sci Rep 16, 12953 (2026). https://doi.org/10.1038/s41598-026-42786-4
キーワード: ティグリニャ感情分析, 低リソース言語のNLP, クロスリンガル転移学習, 大規模言語モデル, パラメータ効率の良いファインチューニング