Clear Sky Science · sv
TigCLaF: ett tvärspråkigt ramverk för stora språkmodeller för sentimentsmedveten textklassificering på resursfattigt tigrinska
Varför detta är viktigt bortom datavetenskap
Varje dag delar personer som talar tigrinska sina förhoppningar, rädslor och åsikter på sociala medier och nyhetssajter. Ändå kan de flesta moderna artificiella intelligenssystem inte läsa dessa meddelanden ordentligt, eftersom språket har avsevärt färre digitala resurser än engelska eller kinesiska. Denna artikel presenterar TigCLaF, ett nytt ramverk som lär stora språkmodeller att effektivt förstå den känslomässiga tonen i tigrinsk text, med begränsade data och måttlig datorkraft. Arbetet erbjuder en modell för att föra kraftfull språkteknik till många andra underrepresenterade språk.
Att göra knapp data till en styrka
Kärnutmaningen för författarna är sentimentsmedveten textklassificering i en resursfattig miljö. Det innebär att automatiskt avgöra om en text uttrycker en positiv, negativ eller neutral känsla samtidigt som subtila emotionella nyanser bevaras. För tigrinska är detta svårt: det finns få annoterade dataset, Ge’ez-skriften har egna skiljetecken- och mellanrumskonventioner, och känslor uttrycks ofta genom idiom och kulturella referenser. Konventionella modeller bygger på antaganden om enorma träningsmängder och välutvecklade verktyg, och misslyckas därför på sådant material. TigCLaF svarar genom att återanvända kunskap från flerspråkiga modeller tränade på datarika språk och noggrant anpassa den till tigrinska utan att träna om allt från grunden.
Ett tredelat recept för att anpassa stora modeller
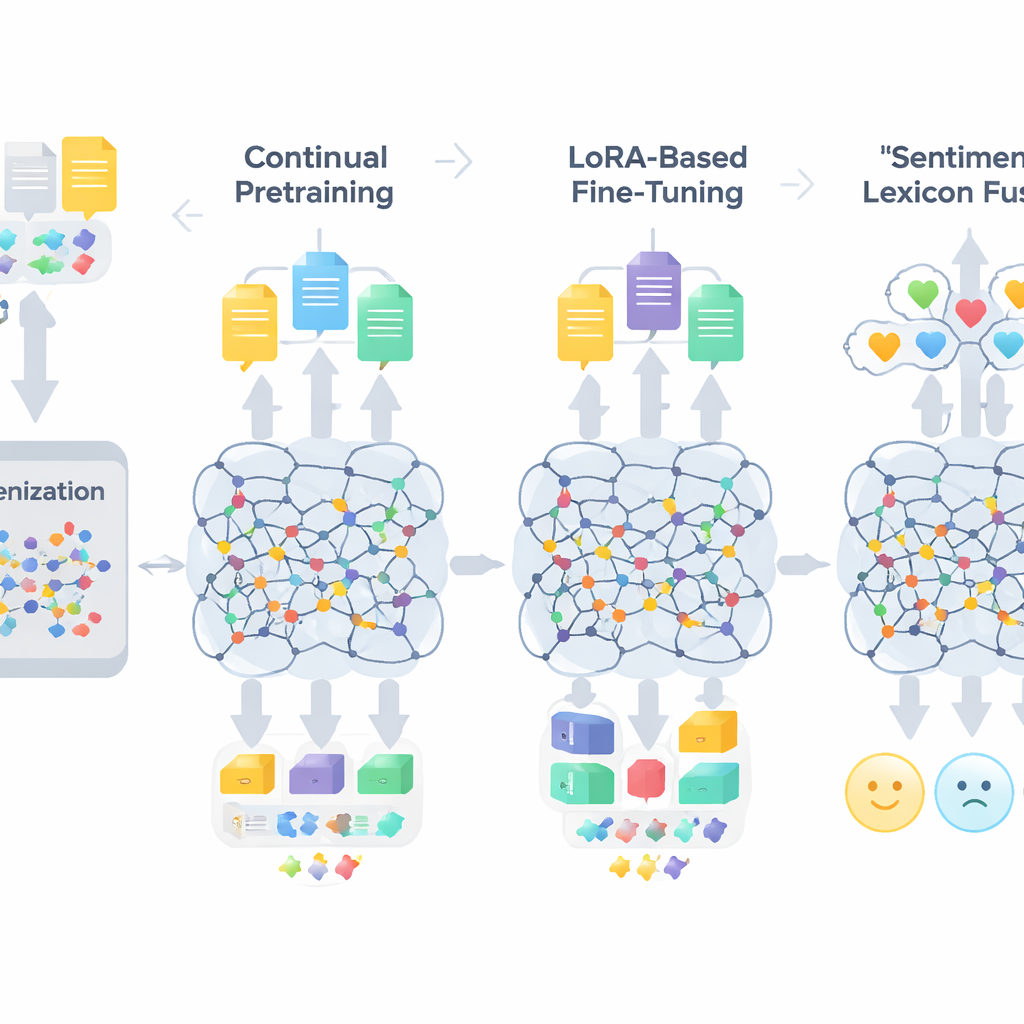
TigCLaF:s arbetsflöde består av tre tätt sammankopplade steg. Först utökar författarna modellens tokeniserare—the delen som delar upp text i enheter—genom att lägga till tusentals ofta förekommande tigrinska subord. Detta minskar konstiga uppdelningar av ord i Ge’ez-skriften och förbättrar hur språket representeras i nätverket. För det andra fortsätter de förträningen av den flerspråkiga modellen på en blandning som mestadels innehåller tigrinska, med en del engelska och amhariska. Under denna fas fyller systemet både i maskerade ord och lär sig att föra matchande meningar över språk närmare varandra i sina interna representationer, vilket stärker tvärspråkig inriktning. Tredje steget är att istället för att uppdatera alla modellvikter tillämpar de en teknik kallad LoRA, som lägger till små adaptermoduler i attention- och feed-forward-lager. Endast dessa lätta komponenter tränas på det 30 000-exemplars stora tigrinska sentimentsdatasetet, vilket drastiskt minskar minnes- och beräkningsbehov.
Att explicit lära modellen om känslor
Utöver generell språkanpassning injicerar ramverket explicit kunskap om känslor. Författarna bygger ett kompakt tigrinskt sentimentslexikon med cirka 3 200 poster genom att kombinera en handgjord ordlista med projectioner från engelska och amhariska resurser. Varje post har en polaritetspoäng som anger hur positivt eller negativt ordet tenderar att vara. Under träningen mappar systemet tokens till dessa polaritetssignaler, hanterar negation och förstärkare och sammanfogar sedan dessa egenskaper med modellens kontextuella inbäddningar. En grindad mekanism lär sig hur mycket vikt som ska ges lexikala sentimentledtrådar kontra omgivande kontext på varje position, vilket hjälper i besvärliga fall som sarkasm, idiom och morfologiskt komplexa ord.
Hur väl det fungerar i praktiken
För att testa TigCLaF sammanställer författarna ett nytt tigrinskt sentimentskorpus från sociala medier och nyhetskällor mellan 2023 och 2025, där de noggrant rengör data och låter modersmålstalare annotera varje inlägg. De jämför sitt ramverk mot starka flerspråkiga baslinjer, inklusive mBERT, XLM-RoBERTa, AfriBERTa och LLaMA-modeller som används antingen med in-context prompting eller med egen parametereffektiv finjustering. TigCLaF uppnår bäst total prestanda, höjer macro F1-poäng med upp till ungefär sju procentenheter över de bästa transformerbaslinjerna, samtidigt som endast så lite som cirka sex procent av parametrarna uppdateras. Ablationsstudier visar att varje komponent bidrar: kontinuerlig förträning ger störst förbättring, tokeniseraranpassning och tvärspråkig inriktning ökar robustheten ytterligare, och fusion med sentimentslexikon förbättrar konsekvent hanteringen av nyanserat emotionellt innehåll. Ramverket överförs också väl till amhariska och engelska i zero-shot- och few-shot-inställningar och försämras gradvis när endast en bråkdel av det tigrinska träningsmaterialet finns tillgängligt.
Från laboratorieexperiment till verklig påverkan
Bortom råa siffror utforskar artikeln var modellen fortfarande har svårigheter—såsom kraftig kodväxling, sarkasm och domändrift mellan nyheter och informella samtal—och argumenterar för att bättre normalisering, modellering av bildligt språk och domänanpassning kan minska felen ytterligare. Avgörande är att TigCLaF körs effektivt på vanlig hårdvara tack vare LoRA och kvantisering, vilket gör det praktiskt för institutioner och samhällen i tigrinsktalande regioner. Författarna drar slutsatsen att deras ramverk både är ett fungerande sentimentsanalysystem för tigrinska och en ritning för att utöka moderna språkteknologier till många andra resursfattiga afrikanska språk, vilket hjälper till att säkerställa att de inte lämnas efter i AI-eran.
Citering: Gebremeskel, H.G., Feng, C., Abera, A.M. et al. TigCLaF: a cross-lingual large language model framework for sentiment-aware text classification in low-resource tigrigna. Sci Rep 16, 12953 (2026). https://doi.org/10.1038/s41598-026-42786-4
Nyckelord: Tigrinska sentimentsanalys, språkteknologi för resursfattiga språk, tvärspråkig transferinlärning, stora språkmodeller, parametereffektiv finjustering