Clear Sky Science · it
TigCLaF: un framework multilingue per modelli linguistici di grandi dimensioni per la classificazione del testo sensibile al sentimento in tigrigna a bassa disponibilità di risorse
Perché questo conta oltre l’informatica
Ogni giorno, persone di lingua tigrigna condividono speranze, paure e opinioni sui social media e sui siti di informazione. Eppure la maggior parte dei moderni sistemi di intelligenza artificiale non riesce a interpretare correttamente questi messaggi, perché la lingua dispone di risorse digitali molto più scarse rispetto all’inglese o al cinese. Questo articolo presenta TigCLaF, un nuovo framework che insegna ai grandi modelli linguistici a comprendere in modo efficiente il tono emotivo del testo in tigrigna, utilizzando dati limitati e potenza di calcolo modesta. Il lavoro offre un modello per portare tecnologie linguistiche avanzate a molte altre lingue sottorappresentate.
Trasformare dati scarsi in un vantaggio
La sfida centrale affrontata dagli autori è la classificazione del testo sensibile al sentimento in un contesto a bassa disponibilità di risorse. Ciò significa determinare automaticamente se un testo esprime un sentimento positivo, negativo o neutro preservando i sottili indizi emotivi. Per il tigrigna questo è difficile: ci sono pochi dataset etichettati, la scrittura in Ge’ez ha regole proprie di punteggiatura e spaziatura, e il sentimento viene spesso espresso tramite modi di dire e riferimenti culturali. I modelli convenzionali presuppongono insiemi di addestramento enormi e strumenti ben sviluppati, quindi falliscono su questo materiale. TigCLaF risponde riutilizzando conoscenze da modelli multilingue addestrati su lingue ricche di dati e adattandole con attenzione al tigrigna senza riaddestrare tutto da zero.
Una ricetta in tre fasi per adattare i grandi modelli
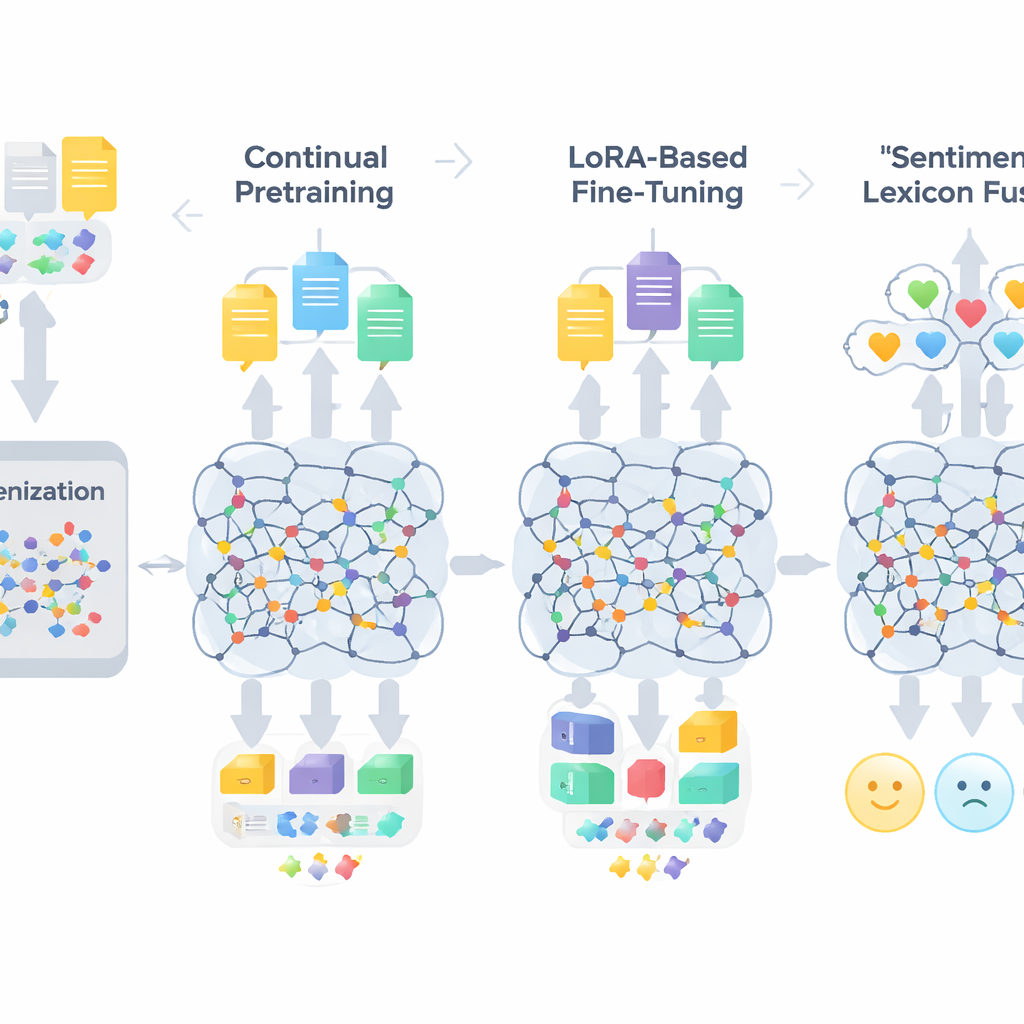
Il flusso di lavoro di TigCLaF consiste di tre fasi strettamente collegate. Prima, gli autori estendono il tokenizer del modello—la componente che suddivide il testo in unità—aggiungendo migliaia di subword tigrigne usate frequentemente. Questo riduce la frammentazione innaturale delle parole in scrittura Ge’ez e migliora la rappresentazione della lingua all’interno della rete. Secondo, proseguono il pretraining del modello multilingue su una miscela composta principalmente da tigrigna, con porzioni di inglese e amarico. In questa fase il sistema riempie parole mascherate e impara ad avvicinare frasi corrispondenti tra le lingue nel suo spazio interno, rafforzando l’allineamento cross-linguale. Terzo, invece di aggiornare tutti i pesi del modello, applicano una tecnica chiamata LoRA, che aggiunge piccoli moduli adapter agli strati di attenzione e feed-forward. Solo questi componenti leggeri vengono addestrati sul dataset di sentimento tigrigna di 30.000 istanze, riducendo drasticamente memoria e richiesta di calcolo.
Insegnare al modello le emozioni in modo esplicito
Oltre all’adattamento generale della lingua, il framework inietta conoscenza esplicita sulle emozioni. Gli autori costruiscono un lessico sentimentale tigrigno compatto di circa 3.200 voci combinando una lista di parole creata manualmente con proiezioni da risorse in inglese e amarico. Ogni voce ha un punteggio di polarità che indica quanto tenda ad essere positiva o negativa. Durante l’addestramento il sistema mappa i token su questi indizi di polarità, gestisce negazioni e intensificatori, e poi fonde queste caratteristiche con gli embedding contestuali del modello. Un meccanismo con gate impara quanto peso dare alle indicazioni lessicali rispetto al contesto circostante in ogni posizione, il che aiuta nei casi difficili come sarcasmo, modi di dire e parole morfologicamente complesse.
Quanto funziona nella pratica
Per valutare TigCLaF, gli autori creano un nuovo corpus di sentimenti in tigrigna raccolto da social media e testate giornalistiche tra il 2023 e il 2025, pulendo i dati con cura e facendo etichettare ogni post da parlanti nativi. Confrontano il loro framework con solidi baseline multilingue, tra cui mBERT, XLM-RoBERTa, AfriBERTa e modelli LLaMA usati sia con prompting in-context sia con il proprio fine-tuning efficiente in termini di parametri. TigCLaF ottiene le migliori prestazioni complessive, incrementando lo score macro F1 fino a circa sette punti percentuali rispetto ai migliori transformer baseline, aggiornando al contempo solo circa il sei percento dei parametri. Gli studi di ablazione mostrano che ogni componente contribuisce: il pretraining continuo fornisce il guadagno maggiore, l’adattamento del tokenizer e l’allineamento cross-linguale migliorano ulteriormente la robustezza, e la fusione con il lessico sentimentale migliora costantemente la gestione dei contenuti emotivi più sfumati. Il framework si trasferisce bene anche ad amarico e inglese in scenari zero-shot e few-shot e degrada gradualmente quando è disponibile solo una frazione dei dati di addestramento tigrigna.
Dall’esperimento di laboratorio all’impatto nel mondo reale
Oltre ai numeri grezzi, l’articolo esplora dove il modello continua ad avere difficoltà—come il forte code-switching, il sarcasmo e gli spostamenti di dominio tra notizie e conversazioni informali—e sostiene che una migliore normalizzazione, la modellazione del linguaggio figurato e l’adattamento di dominio potrebbero ridurre ulteriormente gli errori. In modo cruciale, TigCLaF gira in modo efficiente su hardware comune grazie a LoRA e alla quantizzazione, rendendolo praticabile per istituzioni e comunità nelle regioni di lingua tigrigna. Gli autori concludono che il loro framework è sia un sistema operativo di analisi del sentimento per il tigrigna sia un progetto guida per estendere le tecnologie linguistiche moderne a molte altre lingue africane a bassa risorsa, contribuendo a evitare che vengano lasciate indietro nell’era dell’IA.
Citazione: Gebremeskel, H.G., Feng, C., Abera, A.M. et al. TigCLaF: a cross-lingual large language model framework for sentiment-aware text classification in low-resource tigrigna. Sci Rep 16, 12953 (2026). https://doi.org/10.1038/s41598-026-42786-4
Parole chiave: analisi del sentimento in tigrigna, NLP per lingue a bassa risorsa, apprendimento per trasferimento cross-linguale, modelli linguistici di grandi dimensioni, fine-tuning efficiente in termini di parametri