Clear Sky Science · es
TigCLaF: un marco de modelos de lenguaje multilingüe para la clasificación de texto sensible al sentimiento en tigrigna de recursos escasos
Por qué esto importa más allá de la informática
Cada día, personas que hablan tigrigna comparten sus esperanzas, miedos y opiniones en redes sociales y sitios de noticias. Sin embargo, la mayoría de los sistemas modernos de inteligencia artificial no pueden leer correctamente esos mensajes, porque el idioma dispone de muchos menos recursos digitales que el inglés o el chino. Este artículo presenta TigCLaF, un nuevo marco que enseña a los modelos de lenguaje a gran escala a comprender el tono emocional del texto en tigrigna de forma eficiente, usando datos limitados y potencia informática modesta. El trabajo ofrece un modelo para llevar tecnología lingüística potente a muchas otras lenguas poco representadas.
Convertir datos escasos en una fortaleza
El desafío central que abordan los autores es la clasificación de texto sensible al sentimiento en un entorno de pocos recursos. Esto significa determinar automáticamente si un texto expresa un sentimiento positivo, negativo o neutral, preservando matices emocionales sutiles. Para el tigrigna, esto es difícil: hay pocos conjuntos de datos etiquetados, la escritura Ge’ez tiene sus propias reglas de puntuación y separación, y el sentimiento a menudo se expresa mediante modismos y referencias culturales. Los modelos convencionales asumen conjuntos de entrenamiento enormes y herramientas bien desarrolladas, por lo que flaquean con este tipo de material. TigCLaF responde reutilizando conocimiento de modelos multilingües entrenados en idiomas ricos en datos y adaptándolo cuidadosamente al tigrigna sin volver a entrenar todo desde cero.
Una receta en tres pasos para adaptar grandes modelos
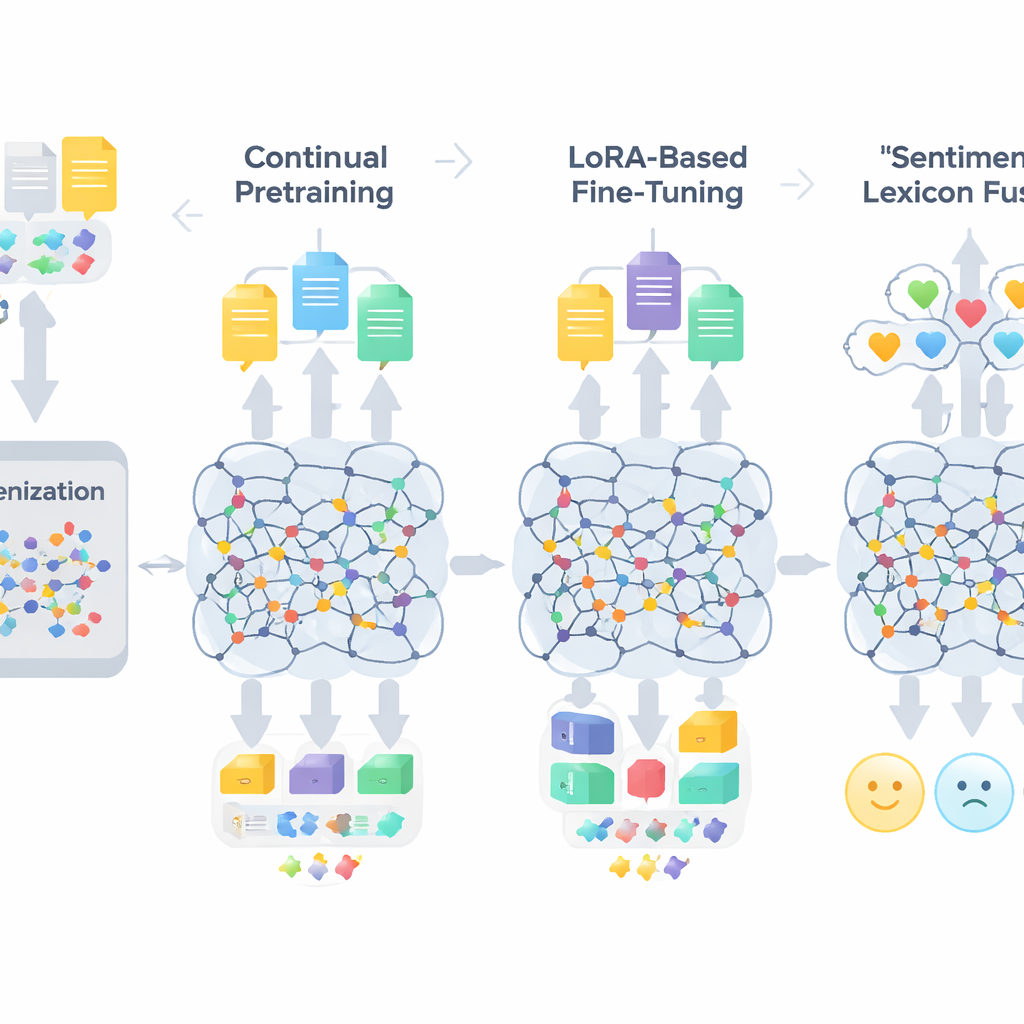
El flujo de trabajo de TigCLaF consta de tres etapas estrechamente conectadas. Primero, los autores amplían el tokenizador del modelo—la parte que segmenta el texto en unidades—añadiendo miles de subpalabras tigrignas de uso frecuente. Esto reduce divisiones incómodas de palabras en escritura Ge’ez y mejora cómo se representa el idioma dentro de la red. Segundo, continúan el preentrenamiento del modelo multilingüe con una mezcla dominada por tigrigna, con algo de inglés y amhárico. Durante esta fase, el sistema rellena palabras enmascaradas y aprende a acercar en su espacio interno oraciones coincidentes entre idiomas, reforzando la alineación cross-lingual. Tercero, en lugar de actualizar todos los pesos del modelo, aplican una técnica llamada LoRA, que añade pequeños módulos adaptadores a las capas de atención y feed-forward. Solo estas piezas ligeras se entrenan con el conjunto de datos de sentimiento en tigrigna de 30.000 instancias, reduciendo drásticamente la memoria y las necesidades de cómputo.
Enseñar al modelo sobre los sentimientos de forma explícita
Más allá de la adaptación lingüística general, el marco inyecta conocimiento explícito sobre las emociones. Los autores construyen un léxico compacto de sentimiento en tigrigna de unas 3.200 entradas combinando una lista de palabras elaborada manualmente con proyecciones desde recursos en inglés y amhárico. Cada entrada lleva una puntuación de polaridad que indica cuán positiva o negativa suele ser. Durante el entrenamiento, el sistema mapea tokens a estas pistas de polaridad, maneja la negación y los intensificadores, y luego fusiona estas características con las incrustaciones contextuales del modelo. Un mecanismo con compuertas aprende cuánto peso dar a las señales léxicas de sentimiento frente al contexto circundante en cada posición, lo que ayuda en casos complejos como sarcasmo, modismos y palabras morfológicamente complejas.
Qué tan bien funciona en la práctica
Para evaluar TigCLaF, los autores curaron un nuevo corpus de sentimiento en tigrigna a partir de redes sociales y medios de comunicación entre 2023 y 2025, limpiando cuidadosamente los datos y haciendo que hablantes nativos etiquetaran cada publicación. Comparan su marco con fuertes baselines multilingües, incluidos mBERT, XLM-RoBERTa, AfriBERTa y modelos LLaMA usados con prompting en contexto o con su propio ajuste eficiente en parámetros. TigCLaF logra el mejor rendimiento global, elevando la puntuación F1 macro hasta en alrededor de siete puntos porcentuales sobre los mejores transformers de referencia, mientras actualiza tan solo aproximadamente el seis por ciento de los parámetros. Estudios de ablación muestran que cada componente aporta: el preentrenamiento continuo ofrece el mayor impulso, la adaptación del tokenizador y la alineación cross-lingual mejoran aún más la robustez, y la fusión con el léxico de sentimiento mejora de forma consistente el manejo de contenido emocional matizado. El marco también se transfiere bien al amhárico y al inglés en configuraciones zero-shot y few-shot y se degrada de forma gradual cuando solo está disponible una fracción de los datos de entrenamiento en tigrigna.
Del experimento de laboratorio al impacto en el mundo real
Más allá de los números brutos, el artículo explora dónde el modelo todavía tiene dificultades—como la conmutación intensiva de códigos, el sarcasmo y los cambios de dominio entre noticias y conversaciones informales—y argumenta que una mejor normalización, modelado del lenguaje figurado y adaptación de dominio podrían reducir aún más los errores. De forma crucial, TigCLaF funciona de manera eficiente en hardware común gracias a LoRA y la cuantización, lo que lo hace práctico para instituciones y comunidades en regiones de habla tigrigna. Los autores concluyen que su marco es tanto un sistema operativo de análisis de sentimiento para tigrigna como un plano para extender las tecnologías lingüísticas modernas a muchas otras lenguas africanas con pocos recursos, ayudando a garantizar que no se queden atrás en la era de la IA.
Cita: Gebremeskel, H.G., Feng, C., Abera, A.M. et al. TigCLaF: a cross-lingual large language model framework for sentiment-aware text classification in low-resource tigrigna. Sci Rep 16, 12953 (2026). https://doi.org/10.1038/s41598-026-42786-4
Palabras clave: Análisis de sentimiento en tigrigna, PLN para lenguas con pocos recursos, aprendizaje por transferencia cross-lingual, modelos de lenguaje a gran escala, ajuste fino eficiente en parámetros