Clear Sky Science · zh
一种用于软件缺陷预测的新型生成式过采样方法
为何隐藏的软件缺陷重要
从汽车到医疗设备,每一种现代产品都依赖数百万行软件。一个未被发现的缺陷就可能导致停机、安全漏洞或昂贵的召回。因此企业在测试上投入巨大,但仍难以在庞大项目中发现那少数真正高风险的代码片段。本文研究了一种新方法,旨在用更可靠且所需数据更少的方式教计算机锁定这些风险点。
真实项目中的不平衡问题
在真实的代码库中,大多数文件按预期工作,只有很小一部分包含缺陷。这种严重偏斜会混淆许多预测工具,因为它们主要看到“干净”的示例并学会假设一切正常。结果是模型在纸面上看起来准确,但经常错过那些稀有且关键的缺陷。早期为解决这一问题的尝试包括删除部分干净样本或复制并轻微调整少数有缺陷样本,但这两种策略要么丢失信息,要么产生重复且不现实的数据。
一种更轻量且更真实的有缺陷示例生成方式
论文提出了 GeNSDP,一种通过在训练前生成额外、逼真的有缺陷示例来应对不平衡的新方法。与复杂深度学习机制不同,GeNSDP 使用一个简化的生成模型,沿着单一数值化的软件度量维度工作。它学习已知有缺陷模块的基本统计模式,然后创建遵循相同分布的新人工样本,在不简单克隆已有样本的前提下丰富“有缺陷”样本池。随后将这些合成示例与原始数据合并,送入深度神经网络,训练其区分高风险与安全的代码模块。
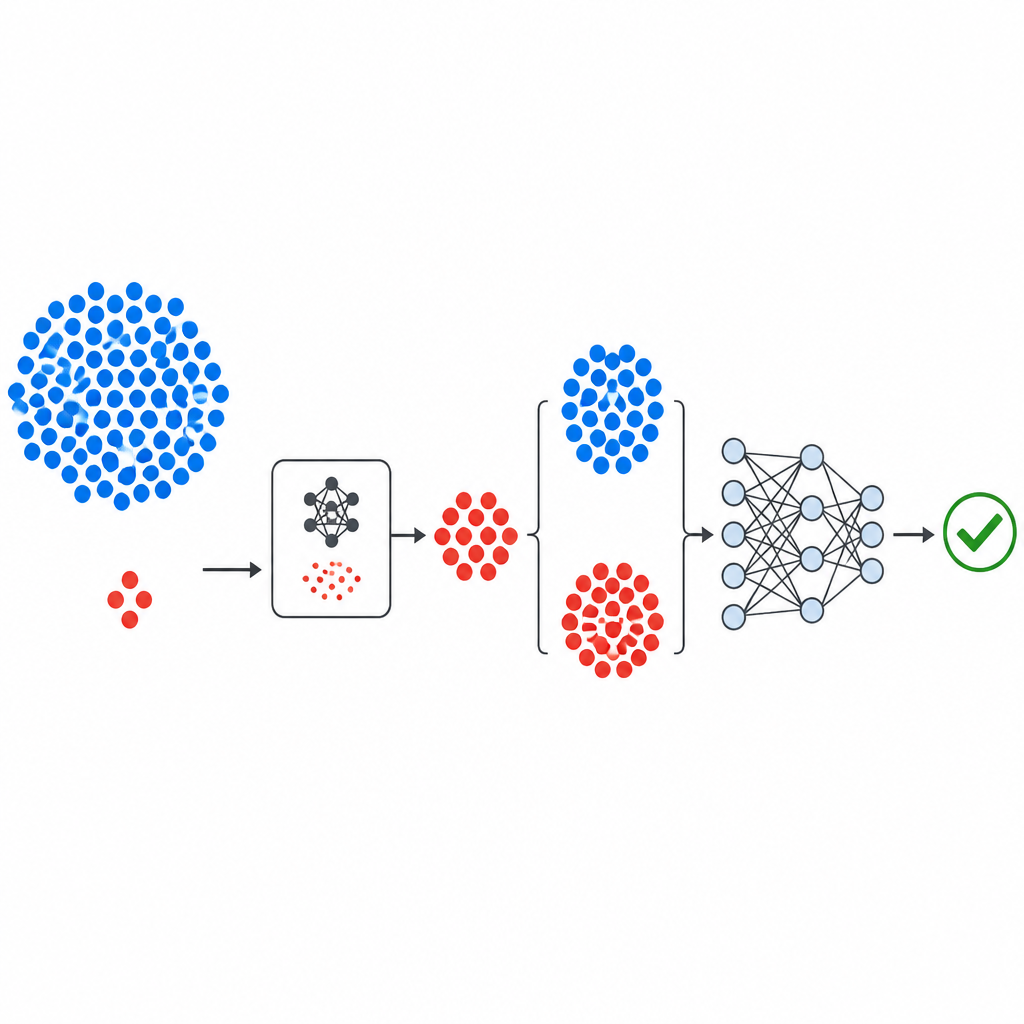
新流程如何构建
工作流始于来自 NASA 和 PROMISE 库的知名公共缺陷数据集,每个数据集都用一小组数值测量描述软件模块,并用标签指示模块是否被发现有缺陷或干净。测量值先标准化以避免单一度量主导。GeNSDP 的生成组件随后仅关注稀少的有缺陷模块,学习它们的典型范围与变异。它反复生成新的合成有缺陷点,并将它们与原始数据混合,直到两类更为平衡。扩展后的数据集以谨慎的方式划分为训练集和测试集,确保没有合成信息泄露到评估步骤中。
测试、比较与结果的可信性
在获得平衡数据后,训练并评估了一个紧凑的深度神经网络,采用十折交叉验证以轮换用于测试的数据部分。研究检查了多个性能指标,重点是曲线下面积(AUC),这是在一类样本远少于另一类时衡量模型区分能力的标准指标。在十个数据集上,GeNSDP 的平均 AUC 约为 99%,并取得较高的 F 值,表明它不仅能发现大部分缺陷,还能将误报率保持在较低水平。作者将其方法与常见的过采样工具(如随机复制、SMOTE、MAHAKIL 和 COSTE)以及将生成式模型与传统或深度学习器结合的更复杂系统进行了比较。GeNSDP 持续表现更好,常常领先数十个百分点。为避免夸大结论,研究还使用了正式的统计检验确认这些提升不太可能由偶然造成,并检查训练与测试分数保持接近,这表明模型并非仅仅在记忆数据。
这对软件团队意味着什么
对非专业人士来说,关键结论是 GeNSDP 为缺陷预测工具提供了一种务实的方式,使其在稀有但重要的有缺陷案例上获得更多“经验”,而无需大量计算资源或复杂的模型调优。通过轻度模拟可能的额外有缺陷模块并用这些示例训练深度网络,该方法有助于将注意力集中在代码库中最可能出问题的部分。研究结果表明,即便是简单的生成式建模,在谨慎使用时也能使自动化缺陷筛查更平衡、更稳定,并更易在不同项目间推广应用。
引用: Goyal, S.R. A novel generative oversampling for software defect prediction. Sci Rep 16, 15957 (2026). https://doi.org/10.1038/s41598-026-41981-7
关键词: 软件缺陷预测, 类别不平衡, 生成式过采样, 深度学习, GAN