Clear Sky Science · en
A novel generative oversampling for software defect prediction
Why hidden software flaws matter
Every modern product, from cars to medical devices, depends on millions of lines of software. A single undetected bug can cause outages, security gaps, or costly recalls. So companies invest heavily in testing, yet they still struggle to spot the small number of truly risky pieces of code buried inside huge projects. This study explores a new way to teach computers to home in on those risky spots more reliably and with less data.
The imbalance problem in real projects
In real codebases, most files work as intended, while only a small fraction contain defects. That lopsided mix confuses many prediction tools, which mostly see “clean” examples and learn to assume everything is fine. The result is a model that looks accurate on paper but often misses the rare, critical defects that matter most. Earlier attempts to fix this have included deleting some clean examples or copying and lightly tweaking the few buggy ones, but both strategies either throw away information or create repetitive, unrealistic data.
A lighter way to create realistic buggy examples
The paper introduces GeNSDP, a new approach that tackles this imbalance by generating additional, lifelike buggy examples before training a predictor. Instead of heavy and complex deep learning machinery, GeNSDP uses a streamlined generative model that works along a single numeric line of software metrics. It learns the basic statistical pattern of known buggy modules and then creates new artificial points that follow the same pattern, enriching the pool of “buggy” samples without simply cloning existing ones. These synthetic examples are then combined with the original data and fed into a deep neural network that learns to distinguish between risky and safe code modules.
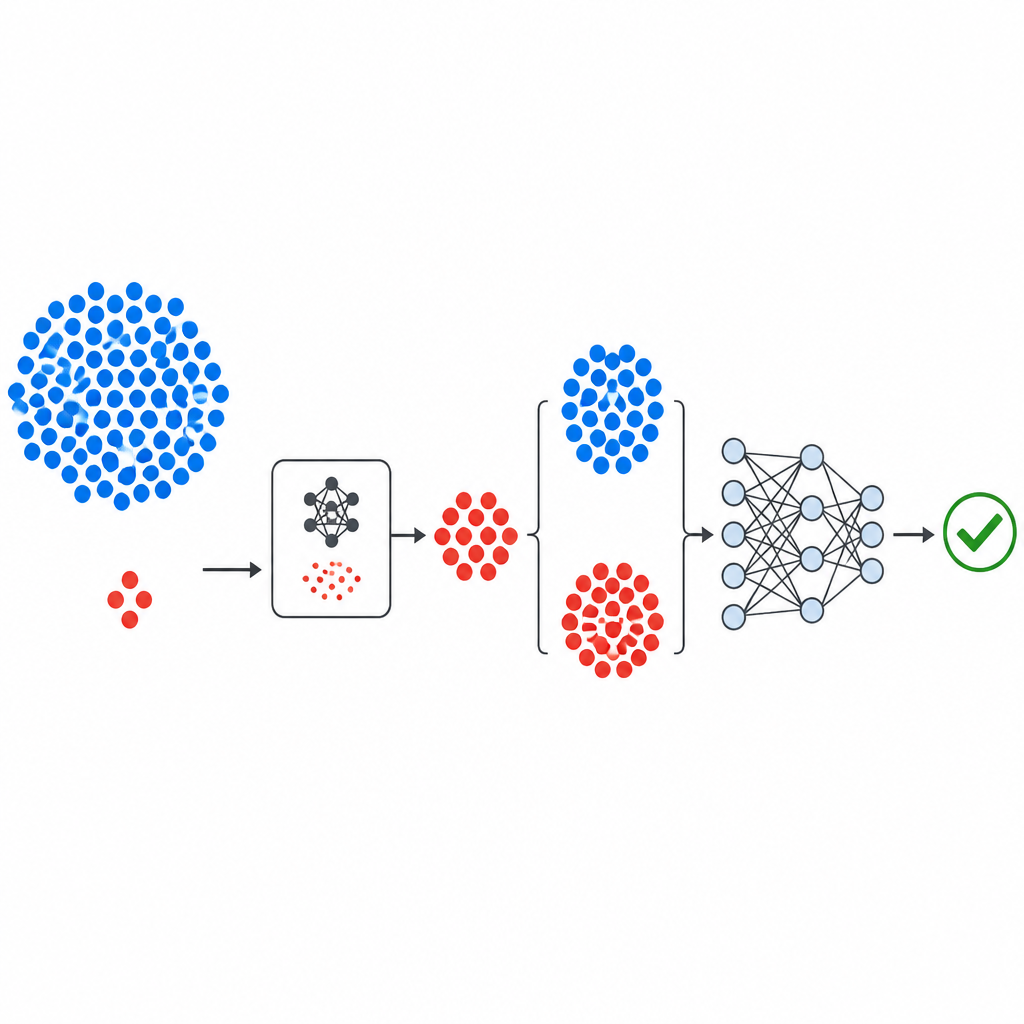
How the new pipeline is built
The workflow begins with well-known public defect datasets from NASA and the PROMISE repository, each describing software modules using a small set of numeric measurements plus a label indicating whether the module was found to be buggy or clean. The measurements are standardized so no single metric dominates. GeNSDP’s generative component then focuses only on the scarce buggy modules, learning their typical ranges and variation. It repeatedly produces new synthetic buggy points and blends them with the original data until the two classes are more balanced. This expanded dataset is split into training and test parts in a careful way so that no synthetic information leaks into the evaluation step.
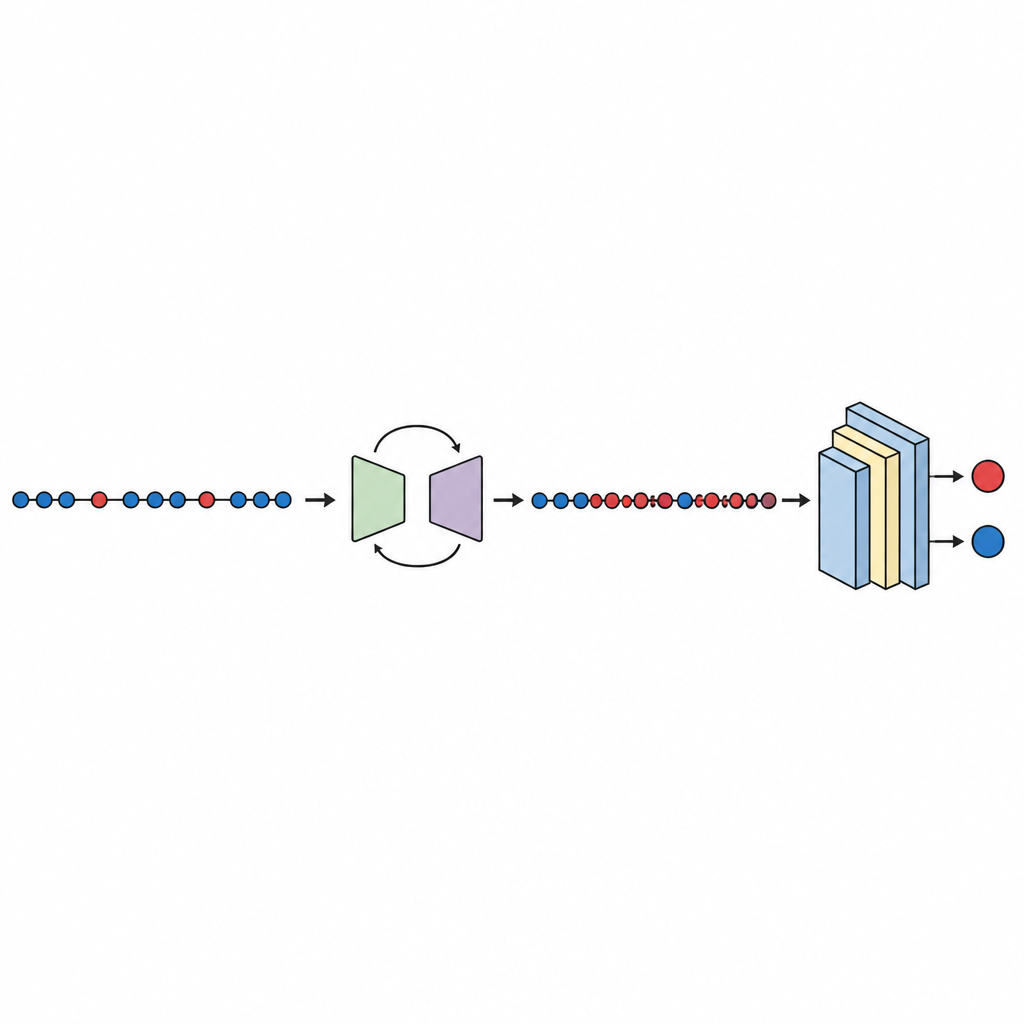
Testing, comparison, and trust in the results
With the balanced data in place, a compact deep neural network is trained and evaluated using ten-fold cross-validation, which rotates which part of the data is used for testing. The study checks several performance scores, focusing on the area under the curve (AUC), a standard measure of how well the model separates buggy from clean modules even when one group is much smaller. Across ten datasets, GeNSDP reaches an average AUC of about 99 percent and a high F-measure, indicating that it not only finds most defects but also keeps false alarms low. The authors compare their method with popular oversampling tools such as random copying, SMOTE, MAHAKIL, and COSTE, as well as with more elaborate systems that blend generative models with classic or deep learners. GeNSDP consistently performs better, often by double-digit percentage points. To avoid overclaiming, the study also uses formal statistical tests to confirm that these gains are unlikely to be due to chance and checks that training and testing scores remain close, a sign that the model is not simply memorizing.
What this means for software teams
For non-specialists, the key takeaway is that GeNSDP offers a practical way to give defect prediction tools more “experience” with the rare but important buggy cases, without demanding huge computing power or intricate model tuning. By lightly simulating what additional buggy modules might look like and then using these examples to train a deep network, the method helps focus attention on the parts of a codebase most likely to cause trouble. The findings suggest that even a simple form of generative modeling, used carefully, can make automated bug screening more balanced, more stable, and easier to apply across different projects.
Citation: Goyal, S.R. A novel generative oversampling for software defect prediction. Sci Rep 16, 15957 (2026). https://doi.org/10.1038/s41598-026-41981-7
Keywords: software defect prediction, class imbalance, generative oversampling, deep learning, GAN