Clear Sky Science · fr
Une nouvelle suréchantillonnage génératif pour la prédiction de défauts logiciels
Pourquoi les défauts logiciels cachés comptent
Chaque produit moderne, des voitures aux dispositifs médicaux, dépend de millions de lignes de logiciel. Un seul bogue non détecté peut provoquer des pannes, des failles de sécurité ou des rappels coûteux. Les entreprises investissent donc massivement dans les tests, et pourtant elles ont du mal à repérer le petit nombre de segments de code réellement risqués enfouis dans de grands projets. Cette étude explore une nouvelle manière d'apprendre aux ordinateurs à se concentrer sur ces zones à risque de façon plus fiable et avec moins de données.
Le problème du déséquilibre dans les projets réels
Dans les bases de code réelles, la plupart des fichiers fonctionnent comme prévu, tandis qu'une petite fraction contient des défauts. Cette répartition inégale perturbe de nombreux outils de prédiction, qui voient majoritairement des exemples « propres » et en viennent à supposer que tout va bien. Le résultat est un modèle qui paraît précis sur le papier mais qui manque souvent les défauts rares et critiques qui importent le plus. Les tentatives précédentes pour corriger cela ont inclus la suppression de certains exemples propres ou la copie et légère modification des quelques cas bogués, mais ces stratégies suppriment soit de l'information soit produisent des données répétitives et irréalistes.
Une manière plus légère de créer des exemples bogués réalistes
L'article présente GeNSDP, une nouvelle approche qui s'attaque à ce déséquilibre en générant des exemples bogués supplémentaires et crédibles avant d'entraîner un prédicteur. Plutôt que d'utiliser des architectures profondes lourdes et complexes, GeNSDP emploie un modèle génératif épuré qui opère le long d'une seule dimension numérique de métriques logicielles. Il apprend le schéma statistique de base des modules bogués connus puis crée de nouveaux points artificiels qui suivent le même profil, enrichissant le pool d'échantillons « bogués » sans se contenter de cloner les cas existants. Ces exemples synthétiques sont ensuite combinés aux données originales et fournis à un réseau de neurones profond qui apprend à distinguer les modules risqués des modules sûrs.
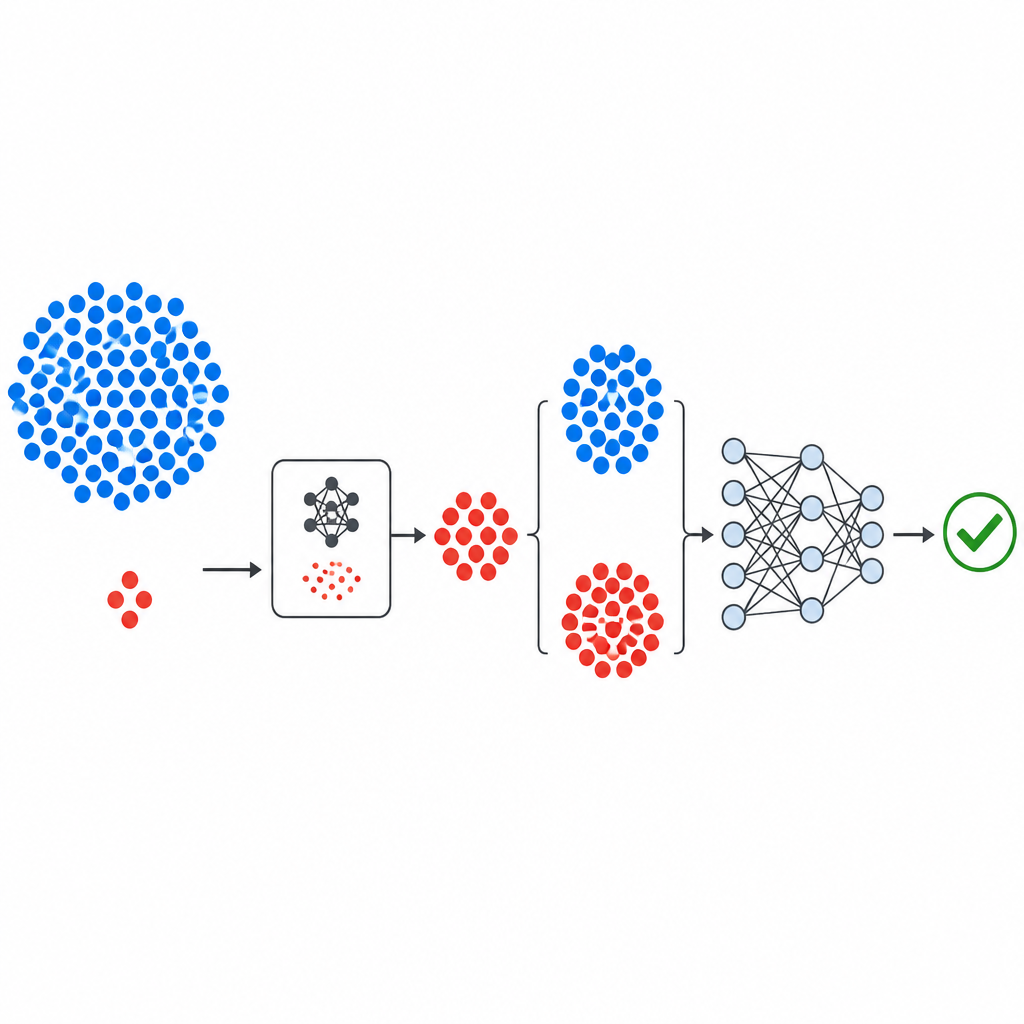
Comment le nouveau pipeline est construit
Le flux de travail commence par des jeux de données publics bien connus sur les défauts, provenant de la NASA et du dépôt PROMISE, chacun décrivant des modules logiciels par un petit ensemble de mesures numériques plus une étiquette indiquant si le module a été jugé bogué ou propre. Les mesures sont standardisées afin qu'aucune métrique unique ne domine. La composante générative de GeNSDP se concentre ensuite uniquement sur les rares modules bogués, apprenant leurs plages typiques et leur variation. Elle produit à plusieurs reprises de nouveaux points bogués synthétiques et les mélange avec les données originales jusqu'à ce que les deux classes soient mieux équilibrées. Cet ensemble de données étendu est divisé en parties d'entraînement et de test de manière soigneuse afin qu'aucune information synthétique ne s'infiltre dans l'étape d'évaluation.
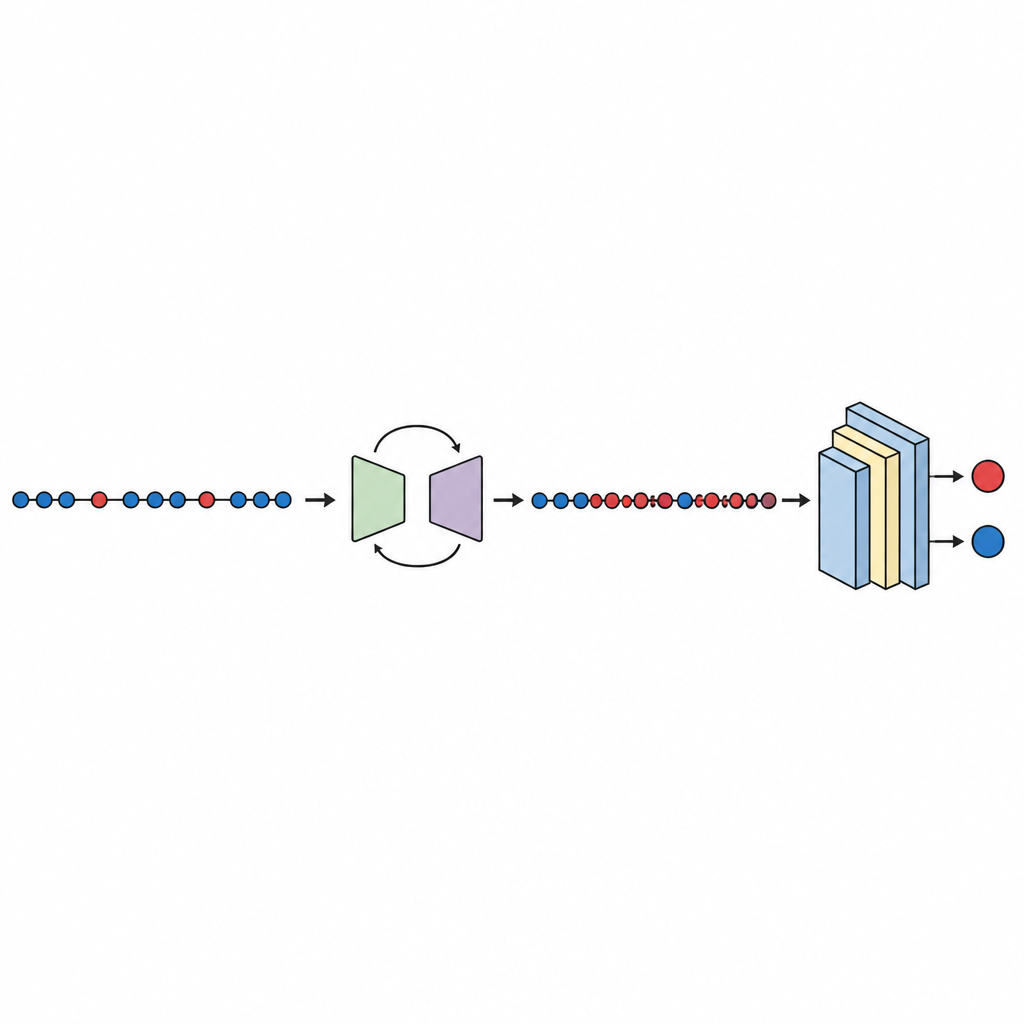
Tests, comparaison et confiance dans les résultats
Avec les données équilibrées en place, un réseau de neurones profond compact est entraîné et évalué en utilisant une validation croisée à dix plis, qui fait tourner la partie des données utilisée pour le test. L'étude vérifie plusieurs scores de performance, en se concentrant sur l'aire sous la courbe (AUC), une mesure standard de la capacité du modèle à séparer les modules bogués des modules propres même lorsqu'un groupe est beaucoup plus petit. Sur dix jeux de données, GeNSDP atteint une AUC moyenne d'environ 99 % et une mesure F élevée, ce qui indique qu'il trouve non seulement la plupart des défauts mais maintient aussi un faible taux de fausses alertes. Les auteurs comparent leur méthode à des outils d'oversampling populaires tels que la copie aléatoire, SMOTE, MAHAKIL et COSTE, ainsi qu'à des systèmes plus élaborés qui combinent des modèles génératifs avec des apprenants classiques ou profonds. GeNSDP performe systématiquement mieux, souvent de plusieurs points de pourcentage. Pour éviter toute exagération, l'étude utilise également des tests statistiques formels pour confirmer que ces gains sont peu susceptibles d'être dus au hasard et vérifie que les scores d'entraînement et de test restent proches, signe que le modèle ne se contente pas de mémoriser.
Ce que cela signifie pour les équipes logicielles
Pour les non-spécialistes, la principale conclusion est que GeNSDP offre un moyen pratique de donner aux outils de prédiction de défauts plus « d'expérience » avec les cas bogués rares mais importants, sans exiger de forte puissance de calcul ni un réglage complexe des modèles. En simulant légèrement à quoi pourraient ressembler des modules bogués supplémentaires puis en utilisant ces exemples pour entraîner un réseau profond, la méthode aide à concentrer l'attention sur les parties d'une base de code les plus susceptibles de poser problème. Les résultats suggèrent que même une forme simple de modélisation générative, utilisée avec précaution, peut rendre le criblage automatique des bogues plus équilibré, plus stable et plus facile à appliquer à différents projets.
Citation: Goyal, S.R. A novel generative oversampling for software defect prediction. Sci Rep 16, 15957 (2026). https://doi.org/10.1038/s41598-026-41981-7
Mots-clés: prédiction des défauts logiciels, déséquilibre de classes, suréchantillonnage génératif, apprentissage profond, GAN