Clear Sky Science · nl
Een nieuwe generatieve oversampling voor voorspelling van softwarefouten
Waarom verborgen softwarefouten belangrijk zijn
Elk modern product, van auto's tot medische apparaten, is afhankelijk van miljoenen regels code. Een enkele niet-ontdekte bug kan storingen, beveiligingslekken of kostbare terugroepacties veroorzaken. Bedrijven investeren daarom veel in testen, maar hebben nog steeds moeite om die kleine hoeveelheid echt risicovolle code te vinden die in grote projecten verstopt zit. Deze studie onderzoekt een nieuwe manier om computers betrouwbaarder en met minder data te leren focussen op die risicovolle plekken.
Het onbalansprobleem in echte projecten
In echte codebases werken de meeste bestanden zoals bedoeld, terwijl slechts een klein deel defecten bevat. Die scheve verhouding verwart veel voorspellingsmethoden, die vooral “schone” voorbeelden zien en daardoor leren aan te nemen dat alles in orde is. Het resultaat is een model dat op papier accuraat lijkt maar vaak de zeldzame, kritieke defecten mist die het meest belangrijk zijn. Eerdere pogingen om dit te verhelpen omvatten het verwijderen van sommige schone voorbeelden of het kopiëren en licht aanpassen van de weinige buggy voorbeelden, maar beide strategieën gooien ofwel informatie weg of creëren repetitieve, onrealistische data.
Een lichtere manier om realistische buggy-voorbeelden te maken
Het artikel introduceert GeNSDP, een nieuwe benadering die deze onbalans aanpakt door extra, levensechte buggy-voorbeelden te genereren vóór het trainen van een voorspeller. In plaats van zware en complexe deep-learningmachinerie gebruikt GeNSDP een gestroomlijnd generatief model dat werkt langs één numerieke as van softwaremetingen. Het leert het basale statistische patroon van bekende buggy-modules en creëert vervolgens nieuwe kunstmatige punten die hetzelfde patroon volgen, waardoor de pool van “buggy” monsters wordt verrijkt zonder bestaande exemplaren simpelweg te klonen. Deze synthetische voorbeelden worden vervolgens gecombineerd met de originele data en gevoed aan een diep neuraal netwerk dat leert te onderscheiden tussen risicovolle en veilige codemodules.
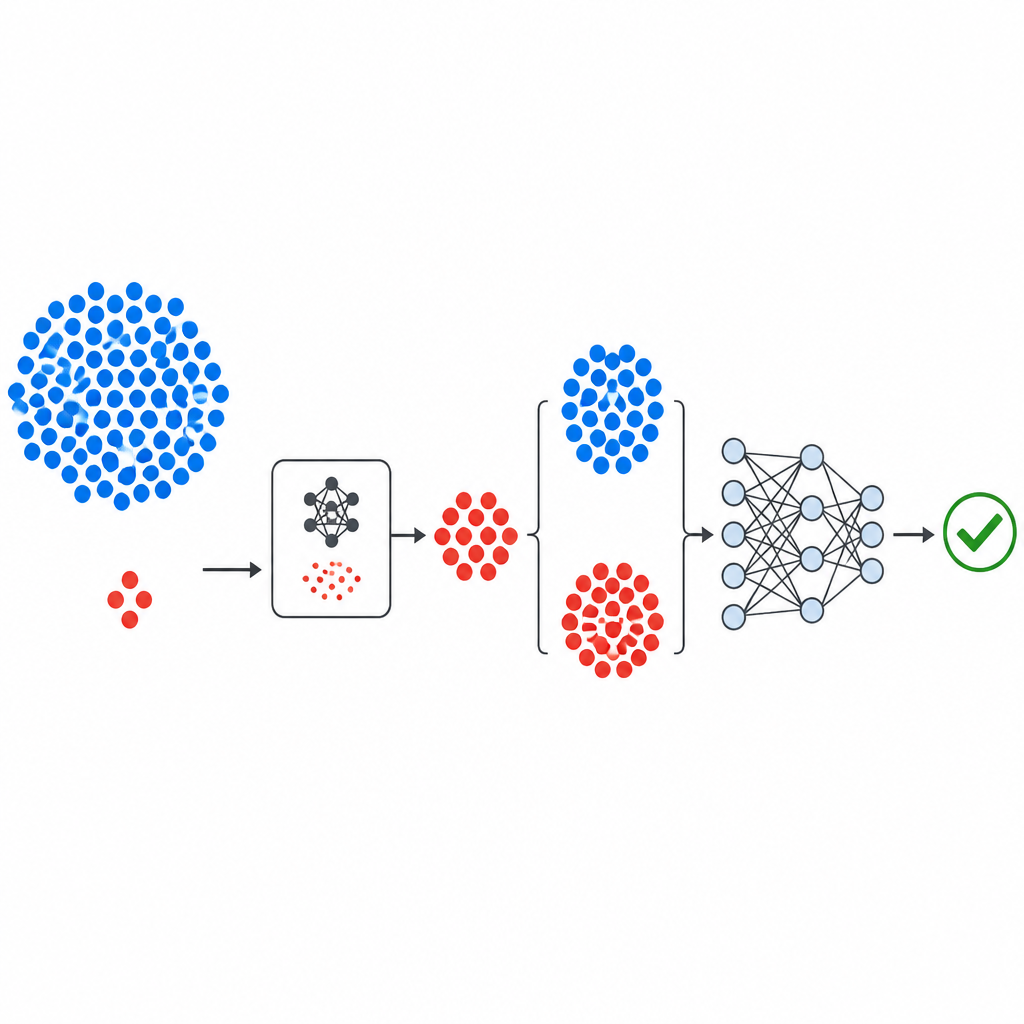
Hoe de nieuwe pijplijn is opgebouwd
De workflow begint met bekende openbare defectdatasets van NASA en de PROMISE-repository, die elk softwaremodules beschrijven met een kleine set numerieke metingen plus een label dat aangeeft of de module buggy of schoon bleek te zijn. De metingen worden gestandaardiseerd zodat geen enkele metriek domineert. De generatieve component van GeNSDP richt zich vervolgens alleen op de schaarse buggy-modules en leert hun typische bereiken en variatie. Het produceert herhaaldelijk nieuwe synthetische buggy-punten en mengt die met de originele data totdat de twee klassen meer in balans zijn. Deze uitgebreide dataset wordt op een zorgvuldige manier in trainings- en testdelen verdeeld zodat er geen synthetische informatie lekt naar de evaluatiefase.
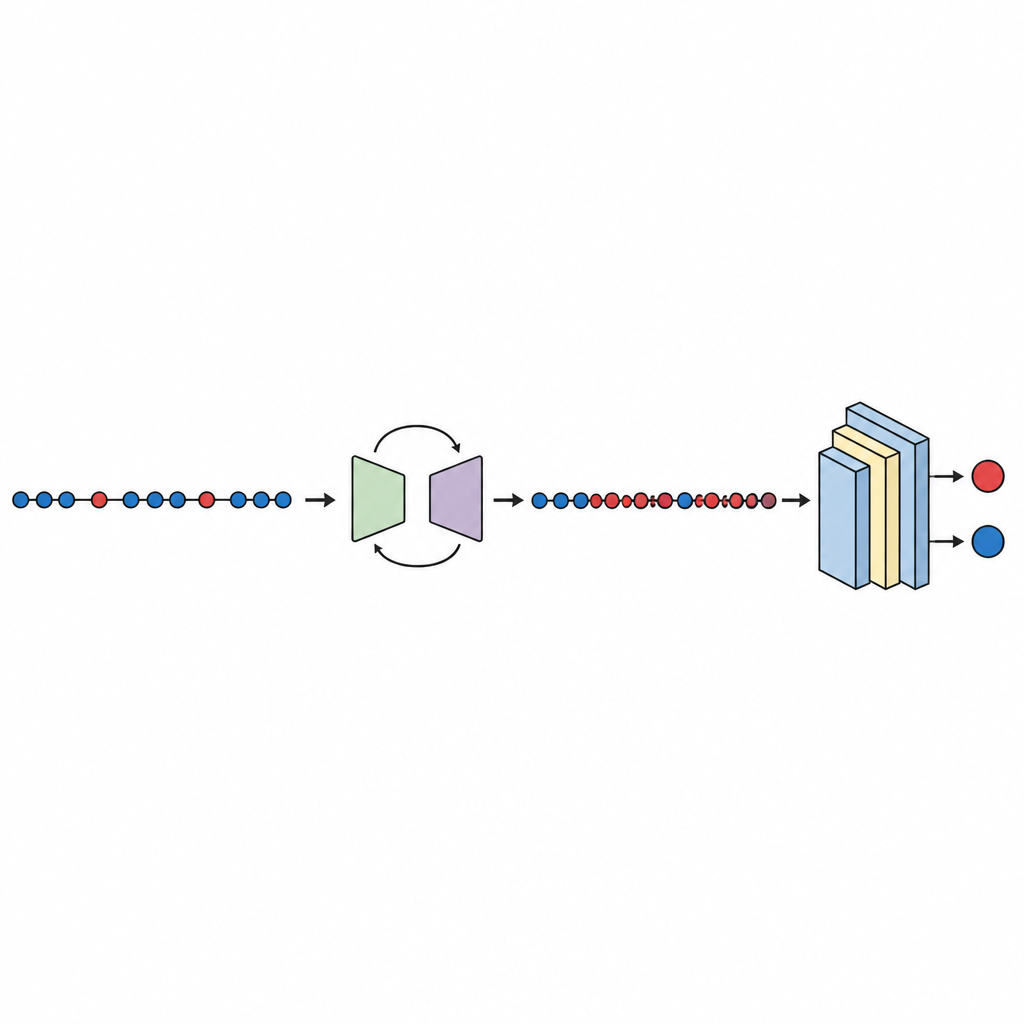
Testen, vergelijking en vertrouwen in de resultaten
Met de gebalanceerde data wordt een compact diep neuraal netwerk getraind en geëvalueerd met tienvoudige cross-validatie, waarbij wordt geroteerd welk deel van de data voor testen wordt gebruikt. De studie controleert verschillende prestatiemaatstaven, met nadruk op de area under the curve (AUC), een standaardmaat voor hoe goed het model buggy van schone modules scheidt, zelfs wanneer de ene groep veel kleiner is. Over tien datasets bereikt GeNSDP een gemiddelde AUC van ongeveer 99 procent en een hoge F-score, wat aangeeft dat het niet alleen de meeste defecten vindt maar ook het aantal valse alarmen laag houdt. De auteurs vergelijken hun methode met populaire oversampling-tools zoals random copying, SMOTE, MAHAKIL en COSTE, evenals met meer uitgebreide systemen die generatieve modellen combineren met klassieke of diepe leerders. GeNSDP presteert consequent beter, vaak met tientallen procentpunten verschil. Om overclaims te vermijden gebruikt de studie ook formele statistische toetsen om te bevestigen dat deze winst waarschijnlijk niet door toeval komt en controleert ze dat trainings- en testscores dicht bij elkaar blijven, een teken dat het model niet simpelweg memoriseert.
Wat dit betekent voor ontwikkelingsteams
Voor niet-specialisten is de belangrijkste conclusie dat GeNSDP een praktische manier biedt om voorspellingshulpmiddelen meer “ervaring” te geven met de zeldzame maar belangrijke buggy-gevallen, zonder enorme rekenkracht of ingewikkelde modellering te vereisen. Door licht te simuleren hoe extra buggy-modules eruit zouden kunnen zien en deze voorbeelden te gebruiken voor het trainen van een diep netwerk, helpt de methode de aandacht te richten op de delen van een codebase die het meest waarschijnlijk problemen veroorzaken. De bevindingen suggereren dat zelfs een eenvoudige vorm van generatieve modellering, mits zorgvuldig toegepast, geautomatiseerde bugdetectie evenwichtiger, stabieler en makkelijker toepasbaar over verschillende projecten kan maken.
Bronvermelding: Goyal, S.R. A novel generative oversampling for software defect prediction. Sci Rep 16, 15957 (2026). https://doi.org/10.1038/s41598-026-41981-7
Trefwoorden: voorspelling van softwarefouten, klasse-onbalans, generatieve oversampling, deep learning, GAN