Clear Sky Science · pl
Nowatorskie generatywne oversampling w prognozowaniu defektów oprogramowania
Dlaczego ukryte usterki oprogramowania mają znaczenie
Każdy współczesny produkt — od samochodów po urządzenia medyczne — opiera się na milionach linii kodu. Pojedynczy niezauważony błąd może spowodować awarie, luki bezpieczeństwa lub kosztowne wycofania. Firmy intensywnie inwestują w testowanie, a mimo to wciąż mają trudności z wykryciem niewielkiej liczby naprawdę ryzykownych fragmentów kodu ukrytych w ogromnych projektach. To badanie analizuje nowy sposób uczenia komputerów, by precyzyjniej i przy mniejszej ilości danych koncentrowały się na tych krytycznych miejscach.
Problem nierównowagi w rzeczywistych projektach
W rzeczywistych repozytoriach większość plików działa zgodnie z założeniami, podczas gdy tylko niewielka część zawiera defekty. Taka nierównowaga myli wiele narzędzi predykcyjnych, które widzą głównie „czyste” przykłady i uczą się zakładać, że wszystko jest w porządku. W efekcie powstaje model, który na papierze wygląda dobrze, lecz często pomija rzadkie, krytyczne defekty. Wcześniejsze próby naprawy sytuacji obejmowały usuwanie części czystych przykładów lub kopiowanie i lekkie modyfikowanie nielicznych przypadków z błędami, ale obie strategie albo pozbywają się informacji, albo tworzą powtarzalne, nierealistyczne dane.
Lżejszy sposób tworzenia realistycznych przykładów z błędami
Artykuł wprowadza GeNSDP — podejście, które przeciwdziała tej nierównowadze, generując dodatkowe, wiarygodne przykłady z błędami przed trenowaniem predyktora. Zamiast ciężkiej i złożonej machiny głębokiego uczenia, GeNSDP wykorzystuje usprawniony model generatywny działający wzdłuż jednej numerycznej linii metryk oprogramowania. Uczy się on podstawowego rozkładu statystycznego znanych modułów z błędami, a następnie tworzy nowe sztuczne punkty podążające za tym samym wzorem, wzbogacając pulę próbek „wadliwych” bez prostego klonowania istniejących. Takie syntetyczne przykłady są następnie łączone z oryginalnymi danymi i podawane do głębokiej sieci neuronowej, która uczy się rozróżniać moduły ryzykowne od bezpiecznych.
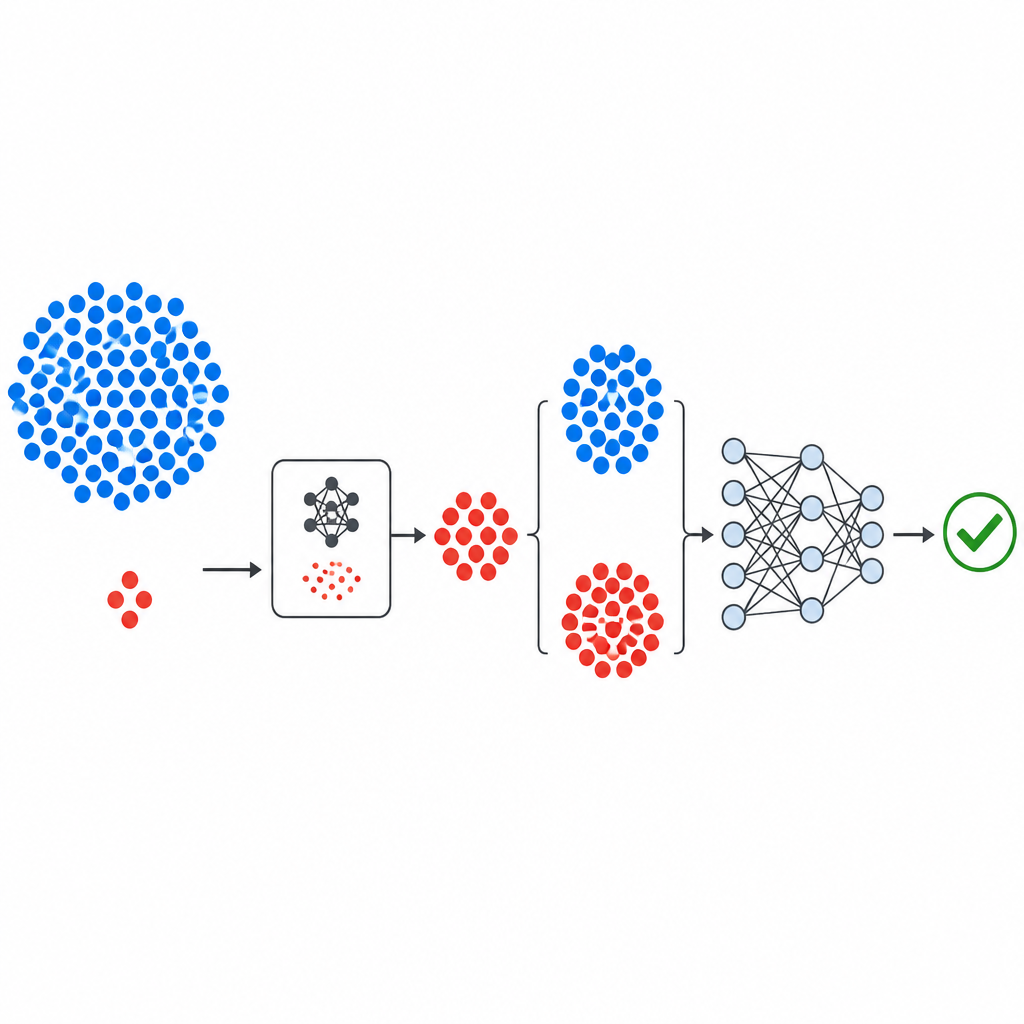
Jak zbudowano nowy pipeline
Przebieg pracy zaczyna się od dobrze znanych publicznych zbiorów defektów pochodzących z NASA i repozytorium PROMISE, z których każdy opisuje moduły oprogramowania przy użyciu niewielkiego zestawu pomiarów numerycznych oraz etykiety wskazującej, czy moduł jest wadliwy czy czysty. Pomiary są standaryzowane, aby żadna metryka nie dominowała. Komponent generatywny GeNSDP koncentruje się wyłącznie na rzadkich modułach z błędami, ucząc się ich typowych zakresów i zmienności. Wielokrotnie generuje nowe syntetyczne punkty z błędami i miesza je z oryginalnymi danymi, aż obie klasy staną się bardziej zbalansowane. Rozszerzony zbiór danych jest następnie dzielony na części treningową i testową w staranny sposób, tak aby żadna syntetyczna informacja nie przedostała się do etapu oceny.
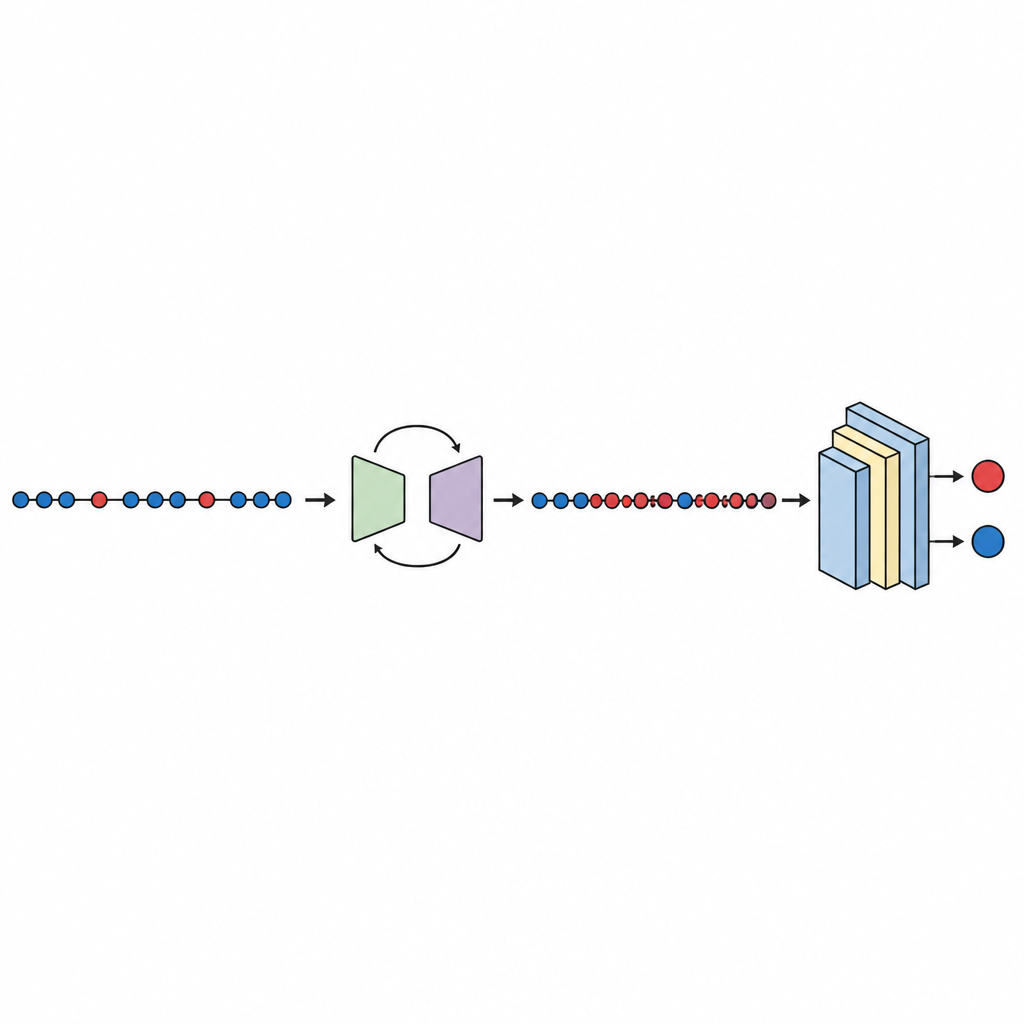
Testy, porównania i wiarygodność wyników
Po uzyskaniu zbalansowanych danych trenuje się kompaktową sieć neuronową i ocenia przy użyciu walidacji krzyżowej dziesięciokrotnej, która rotuje część danych wykorzystywaną do testów. Badanie sprawdza kilka miar wydajności, ze szczególnym uwzględnieniem pola pod krzywą (AUC) — standardowej miary zdolności modelu do rozdzielania modułów wadliwych od czystych, nawet gdy jedna klasa jest znacznie mniejsza. W dziesięciu zbiorach danych GeNSDP osiąga średnie AUC na poziomie około 99 procent oraz wysoką miarę F, co wskazuje, że nie tylko wykrywa większość defektów, lecz także utrzymuje niską liczbę fałszywych alarmów. Autorzy porównują swoją metodę z popularnymi narzędziami oversamplingu, takimi jak losowe kopiowanie, SMOTE, MAHAKIL i COSTE, a także z bardziej rozbudowanymi systemami łączącymi modele generatywne z klasycznymi lub głębokimi uczniami. GeNSDP konsekwentnie wypada lepiej, często o kilkadziesiąt punktów procentowych. Aby uniknąć przesadnych twierdzeń, badanie stosuje także formalne testy statystyczne, potwierdzające, że te zyski są mało prawdopodobne do wystąpienia przypadkowo, oraz sprawdza, że wyniki treningu i testów są zbliżone — co jest oznaką, że model nie po prostu zapamiętuje dane.
Co to oznacza dla zespołów programistycznych
Dla osób niebędących specjalistami kluczowy wniosek jest taki, że GeNSDP oferuje praktyczny sposób na zapewnienie narzędziom predykcji defektów większego „doświadczenia” w rzadkich, lecz istotnych przypadkach z błędami, bez konieczności dużych mocy obliczeniowych czy skomplikowanego strojenia modeli. Dzięki lekkiej symulacji tego, jak mogłyby wyglądać dodatkowe wadliwe moduły, a następnie wykorzystaniu tych przykładów do trenowania sieci głębokiej, metoda pomaga skierować uwagę na części bazy kodu najbardziej narażone na problemy. Wyniki sugerują, że nawet prosta forma modelowania generatywnego, zastosowana ostrożnie, może uczynić automatyczne przesiewanie błędów bardziej zrównoważonym, stabilnym i łatwiejszym do zastosowania w różnych projektach.
Cytowanie: Goyal, S.R. A novel generative oversampling for software defect prediction. Sci Rep 16, 15957 (2026). https://doi.org/10.1038/s41598-026-41981-7
Słowa kluczowe: prognozowanie defektów oprogramowania, nierównowaga klas, generatywny oversampling, uczenie głębokie, GAN