Clear Sky Science · he
שיטת יצירת-נתונים חדשה לאיזון־יתר בניבוי תקלות תוכנה
למה ליקויים נסתרين בתוכנה חשובים
כל מוצר מודרני, מרכבים ועד מכשירים רפואיים, תלוי במיליוני שורות קוד. באג יחיד שלא זוהה יכול לגרום לקריסות, לחורי אבטחה או להחזרים יקרים. לכן חברות משקיעות רבות בבדיקות, אך עדיין מתקשות לזהות את מספר המועט של מקטעי הקוד המסוכנים המוסתרים בתוך פרויקטים עצומים. מחקר זה בוחן דרך חדשה ללמד מחשבים להתמקד בנגיעות המסוכנות האלה באופן אמין יותר ובשימוש בכמות נתונים קטנה יותר.
בעיית האי־איזון בפרויקטים אמיתיים
בעצי־קוד אמיתיים, רוב הקבצים פועלים כמצופה, ורק חלק קטן מכיל תקלות. התמהיל הבלתי־מאוזן הזה מבלבל כלים רבים לניבוי, שרואים בעיקר דוגמאות "נקיות" ולומדים להניח שהכל בסדר. התוצאה היא מודל שנראה מדויק במסמכים אך לעתים קרובות מפספס את התקלות הנדירות והקריטיות. ניסיונות קודמים לתקן זאת כללו מחיקת חלק מהדוגמאות הנקיות או שכפול ושינוי קל של הדוגמאות הפגומות הבודדות, אך שתי האסטרטגיות הללו either זורקות מידע או מייצרות נתונים חוזרים ולא מציאותיים.
דרך קלה יותר ליצור דוגמאות פגומות וריאליסטיות
המאמר מציג את GeNSDP, גישה חדשה שנלחמת באי־האחידות על ידי יצירת דוגמאות פגומות נוספות ואמינות לפני אימון החוזה. במקום מנגנוני למידה עמוקה כבדים ומסובכים, GeNSDP משתמשת במודל מחולל מזורז שעובד לאורך ציר מספרי יחיד של מדדי תוכנה. הוא לומד את התבנית הסטטיסטית הבסיסית של המודולים הפגומים הידועים ואז יוצר נקודות מלאכותיות חדשות העוקבות אחר אותה תבנית, מעשירות את מאגר הדגימות "הפגומות" מבלי לשכפל דוגמאות קיימות. דוגמאות סינתטיות אלו משולבות לאחר מכן עם הנתונים המקוריים ומוזנות לרשת עצבית עמוקה שלומדת להבחין בין מודולים מסוכנים ובין בטוחים.
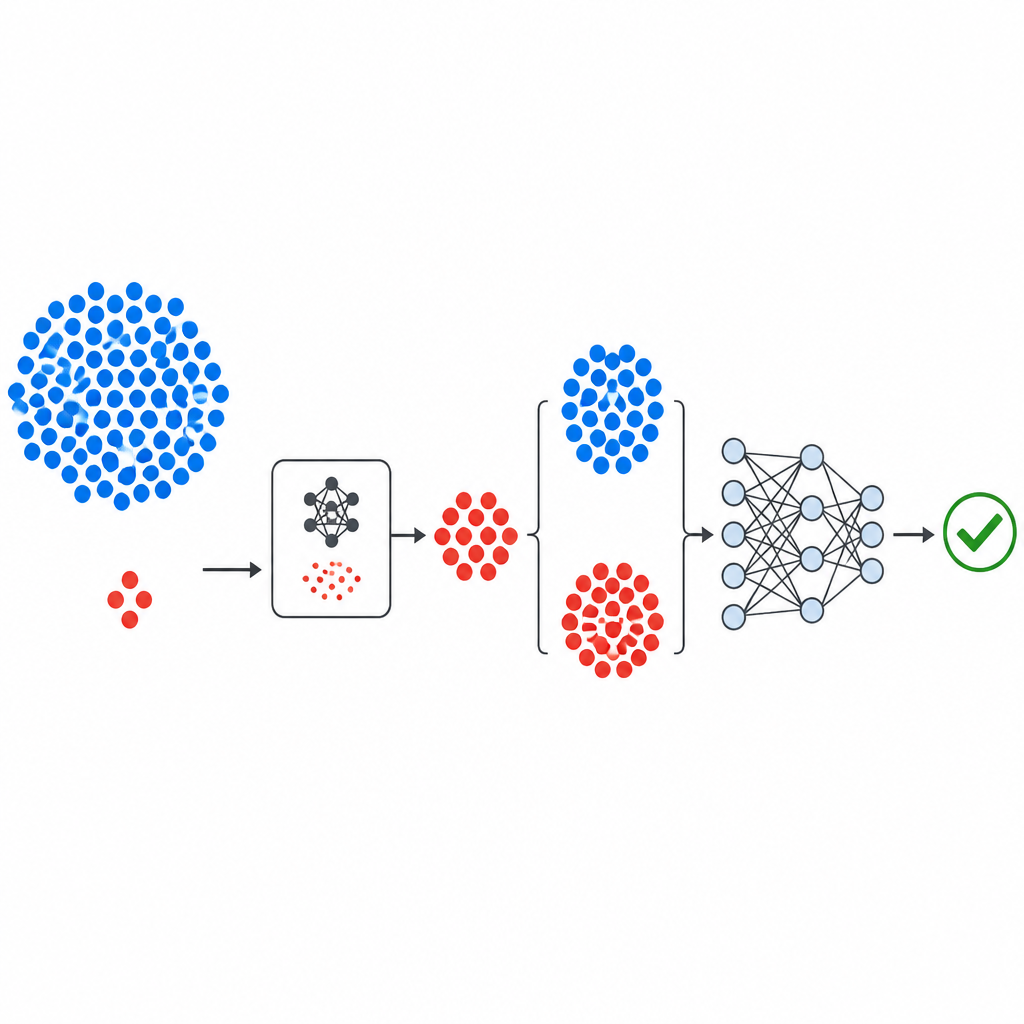
איך הצינור החדש בנוי
זרימת העבודה מתחילה במאגרי נתונים מוכרים של תקלות פתוחים מה־NASA וממאגר PROMISE, שכל אחד מהם מתאר מודולי תוכנה באמצעות קבוצה קטנה של מדידות מספריות ותווית המציינת האם המודול נמצא פגום או נקי. המדידות מוסטנדרטות כך שאף מדד בודד לא ישלוט. רכיב הייצור של GeNSDP מתמקד רק במודולים הפגומים המצומצמים, לומד את טווחי הטיפוס והשונות שלהם. הוא יוצר שוב ושוב נקודות פגומות סינתטיות ומשלב אותן עם הנתונים המקוריים עד שהמחלקות מתאזנות יותר. מאגר הנתונים המורחב נחצה לחלקי אימון ובדיקה באופן זהיר כדי ששום מידע סינתטי לא ינזל לתוך שלב ההערכה.
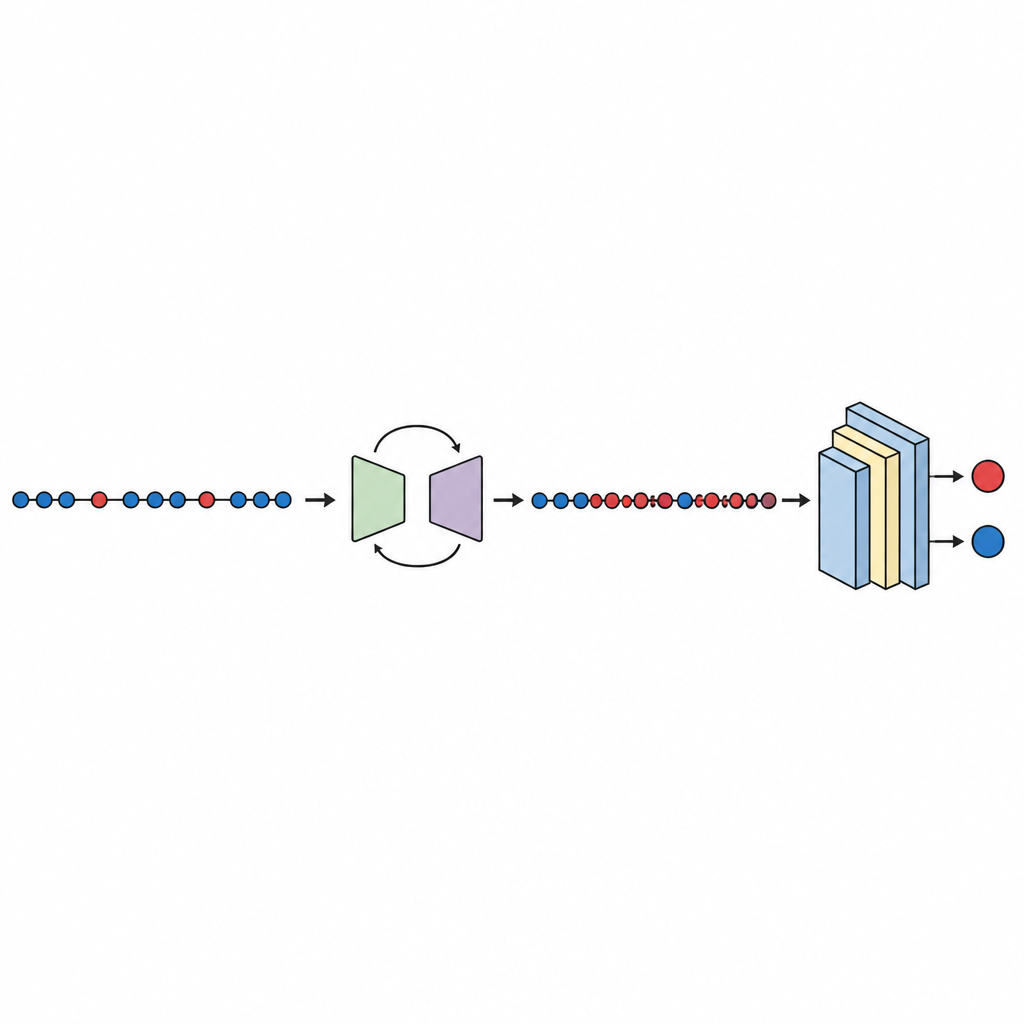
בדיקות, השוואה ואמינות התוצאות
לאחר שהנתונים מאוזנים, מאמנת ומעריכה רשת עצבית עמוקה קומפקטית באמצעות תיקוף צולב בעשר קפיצות, שמחליף איזו חלקת נתונים משמשת לבדיקות. המחקר בודק מספר מדדי ביצוע, עם דגש על שטח מתחת לעקומה (AUC), מדד סטנדרטי לאופן בו המודל מפריד בין פגום לנקי גם כאשר קבוצה אחת קטנה בהרבה. בעשר מערכי נתונים, GeNSDP מגיע לממוצע AUC של כ־99 אחוז ולמדד F גבוה, מה שמצביע שלא רק שהוא מוצא את רוב התקלות אלא גם שומר על רמת אזעקות שקר נמוכה. המחברים משווים את שיטתם לכלי איזון־יתר נפוצים כגון שכפול אקראי, SMOTE, MAHAKIL ו־COSTE, וכן למערכות מורכבות יותר המשלבות מודלים גנרטיביים עם לומדים קלאסיים או עמוקים. GeNSDP משיג ביצועים טובים יותר בעקביות, לעיתים בפערים דו־ספרתיים. כדי לא לטעון יתר על המידה, המחקר משתמש גם במבחנים סטטיסטיים פורמליים כדי לאשר שהשיפורים הללו אינם כנראה תוצאה של מקרה ובודק שהציונים של אימון ובדיקה נשארים קרובים — סימן לכך שהמודל לא סתם שינן.
מה משמעות הדבר לצוותי תוכנה
לעיני קוראים שאינם מומחים, המסקנה המרכזית היא ש־GeNSDP מציע דרך מעשית להעניק לכלי ניבוי תקלות "ניסיון" רב יותר עם מקרים נדירים אך חשובים של קוד פגום, בלי לדרוש כוח מחשוב עצום או כוונון מודל מורכב. על ידי הדמיה קלה של איך מודולים פגומים נוספים עשויים להיראות ושימוש בדוגמאות אלה לאימון רשת עמוקה, השיטה מסייעת למקד תשומת לב בחלקי בסיס הקוד שסביר להניח שיובילו לבעיות. הממצאים מצביעים שגם צורת יצירת־הנתונים הפשוטה, בשימוש זהיר, יכולה להכין סינון שגיאות אוטומטי להיות מאוזן יותר, יציב יותר וקל יותר ליישום בפרויקטים שונים.
ציטוט: Goyal, S.R. A novel generative oversampling for software defect prediction. Sci Rep 16, 15957 (2026). https://doi.org/10.1038/s41598-026-41981-7
מילות מפתח: ניבוי תקלות תוכנה, אי־איזון מחלקות, יצירת-נתונים בריבוי, למידה עמוקה, GAN