Clear Sky Science · tr
Yazılım hata tahmini için yeni bir üretken aşırı örnekleme yöntemi
Neden gizli yazılım kusurları önemlidir
Arabalarından tıbbi cihazlara kadar her modern ürün, milyonlarca satır yazılıma dayanır. Tek bir tespit edilmemiş hata kesintilere, güvenlik açıklarına veya maliyetli geri çağırmalara neden olabilir. Bu yüzden şirketler teste büyük yatırımlar yapar, ancak yine de devasa projelerde gömülü az sayıdaki gerçekten riskli kod parçalarını tespit etmekte zorlanırlar. Bu çalışma, bilgisayarları bu riskli noktaları daha güvenilir ve daha az veriyle hedeflemeyi öğrenmeye yönlendirmenin yeni bir yolunu araştırır.
Gerçek projelerdeki dengesizlik sorunu
Gerçek kod tabanlarında çoğu dosya amaçlandığı gibi çalışırken yalnızca küçük bir kısmı hatalıdır. Bu dengesiz karışım, çoğu zaman “temiz” örnekleri gören ve her şeyin yolunda olduğunu varsaymayı öğrenen tahmin araçlarını yanıltır. Sonuç, kağıt üzerinde doğru görünen ancak en çok önem taşıyan nadir, kritik hataları sıklıkla kaçıran bir modeldir. Bunu düzeltmeye yönelik önceki girişimler bazı temiz örnekleri silmeyi veya birkaç hatalı örneği kopyalayıp hafifçe değiştirmeyi içeriyordu; ancak her iki strateji de ya bilgi kaybına yol açar ya da tekrarlı, gerçekçi olmayan veriler üretir.
Gerçekçi hatalı örnekler üretmenin daha hafif bir yolu
Makale, bu dengesizliği, bir tahminciyi eğitmeden önce ek, gerçekçi hatalı örnekler üreterek ele alan yeni bir yaklaşım olan GeNSDP'yi tanımlıyor. Ağır ve karmaşık derin öğrenme makineleri yerine GeNSDP, yazılım metriklerinin tek boyutlu sayısal çizgisi boyunca çalışan sadeleştirilmiş bir üretken model kullanır. Bilinen hatalı modüllerin temel istatistiksel desenini öğrenir ve sonra aynı desene uyan yeni yapay noktalar oluşturarak mevcut örnekleri basitçe kopyalamadan “hatalı” örnek havuzunu zenginleştirir. Bu sentetik örnekler daha sonra orijinal verilerle birleştirilir ve riskli ile güvenli kod modüllerini ayırt etmeyi öğrenen bir derin sinir ağına verilerek eğitilir.
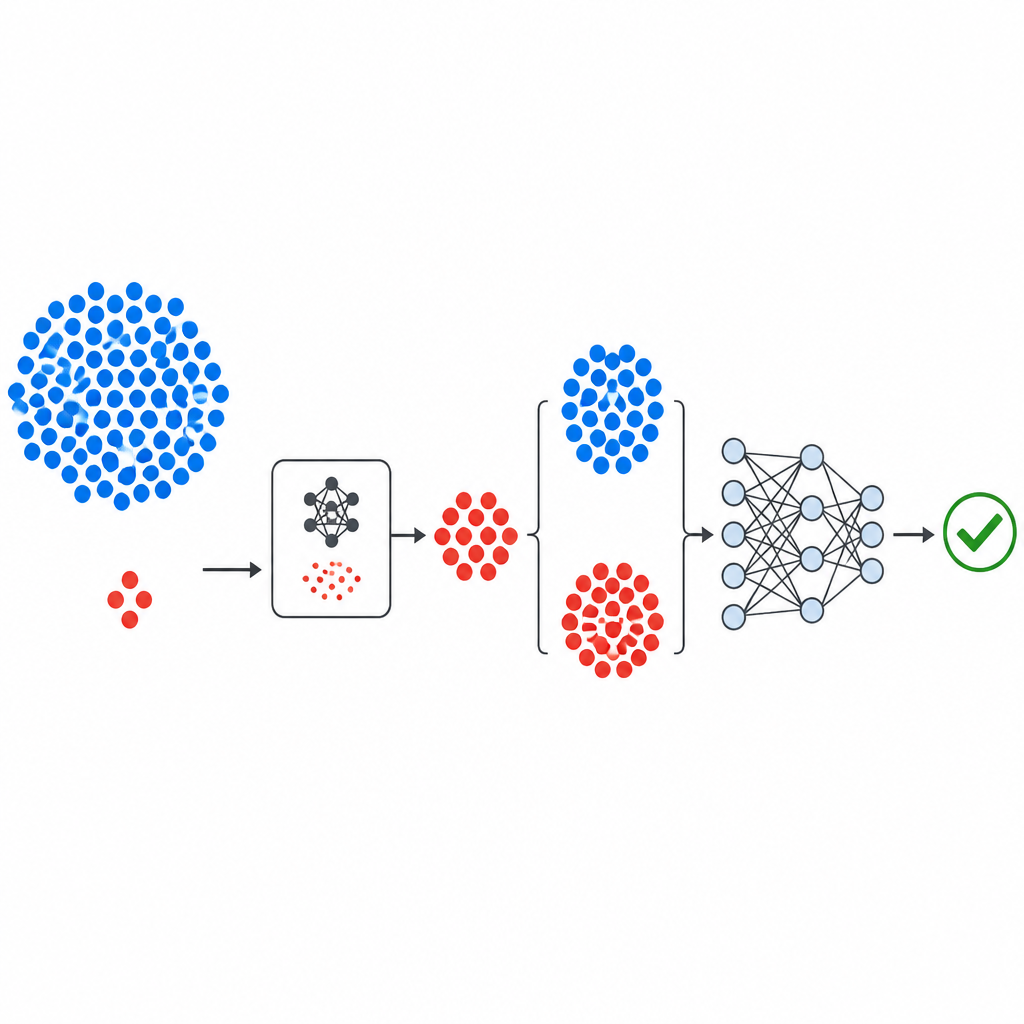
Yeni hattın nasıl kurulduğu
İş akışı, NASA ve PROMISE deposundan alınan iyi bilinen kamu hata veri kümeleriyle başlar; her biri yazılım modüllerini küçük bir sayısal ölçüm setiyle ve modülün hatalı mı yoksa temiz mi bulunduğunu gösteren bir etiketle tanımlar. Ölçümler, hiçbir tek metrik baskın olmasın diye standartlaştırılır. GeNSDP’nin üretken bileşeni daha sonra sadece az bulunan hatalı modüllere odaklanır, bunların tipik aralıklarını ve değişimini öğrenir. Tekrarlı şekilde yeni sentetik hatalı noktalar üretir ve iki sınıf daha dengeli olana kadar bunları orijinal verilerle harmanlar. Bu genişletilmiş veri kümesi, sentetik bilgilerin değerlendirme adımına sızmamasını sağlayacak şekilde dikkatli bir biçimde eğitim ve test parçalarına ayrılır.
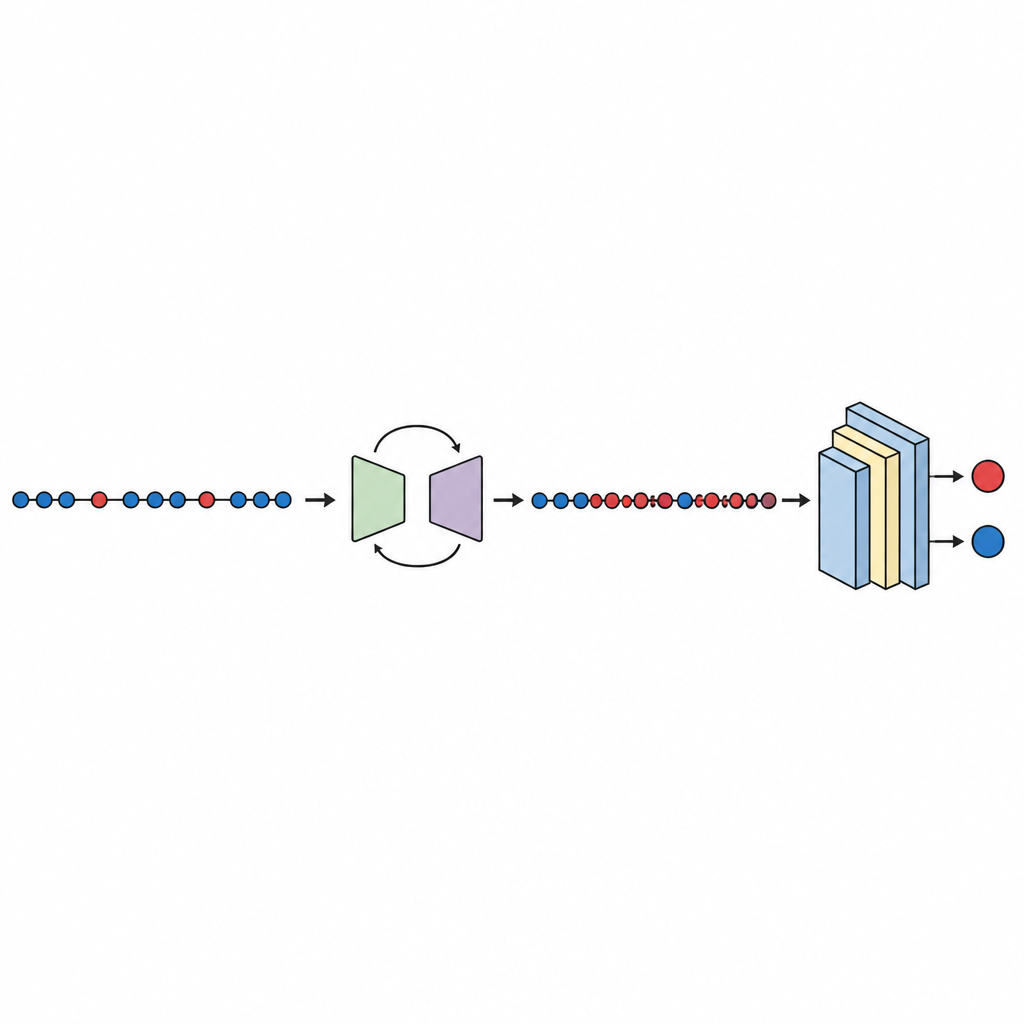
Test, karşılaştırma ve sonuçlara güven
Dengelenmiş veriler hazır olduğunda kompakt bir derin sinir ağı on katlı çapraz doğrulama kullanılarak eğitilir ve değerlendirilir; bu yöntem test için hangi veri parçasının kullanılacağını döndürür. Çalışma, modelin hatalıları temizlerden ne kadar iyi ayırdığını ölçen standart bir gösterge olan eğri altındaki alan (AUC) dahil olmak üzere birkaç performans skorunu kontrol eder. On veri kümesi genelinde GeNSDP yaklaşık %99 ortalama AUC ve yüksek bir F-ölçüsü elde eder; bu, yalnızca çoğu hatayı bulmakla kalmayıp aynı zamanda yanlış alarmları düşük tuttuğu anlamına gelir. Yazarlar yöntemlerini rastgele kopyalamaya, SMOTE, MAHAKIL ve COSTE gibi popüler aşırı örnekleme araçlarına ve üretken modelleri klasik veya derin öğrenicilerle harmanlayan daha ayrıntılı sistemlere karşı karşılaştırır. GeNSDP tutarlı biçimde genellikle çift haneli yüzde puanları aşan daha iyi performans gösterir. Aşırı iddialı olmamak için çalışma, bu kazanımların şans eseri olma olasılığını azaltan resmi istatistiksel testler de kullanır ve eğitim ile test skorlarının yakın kalıp kalmadığını kontrol ederek modelin sadece ezberlemediğine dair kanıt sunar.
Yazılım ekipleri için anlamı
Uzman olmayanlar için temel çıkarım şudur: GeNSDP, nadir ama önemli hatalı vakalarla ilgili tahmin araçlarına pratik bir “deneyim” kazandırmanın; bunun için büyük hesaplama gücü veya karmaşık model ayarı gerektirmemenin bir yolunu sunar. Ek hatalı modüllerin nasıl görünebileceğini hafifçe simüle edip bu örnekleri bir derin ağ eğitmek için kullanarak yöntem, kod tabanının sorun çıkarma olasılığı en yüksek kısımlarına dikkat çekmeyi kolaylaştırır. Bulgular, dikkatli kullanıldığında basit bir üretken modellemenin bile otomatik hata taramasını daha dengeli, daha stabil ve farklı projelere daha uygulanabilir kılabileceğini öne sürüyor.
Atıf: Goyal, S.R. A novel generative oversampling for software defect prediction. Sci Rep 16, 15957 (2026). https://doi.org/10.1038/s41598-026-41981-7
Anahtar kelimeler: yazılım hata tahmini, sınıf dengesi sorunu, üretken aşırı örnekleme, derin öğrenme, GAN