Clear Sky Science · pt
Uma nova sobremostragem generativa para previsão de defeitos de software
Por que falhas ocultas de software importam
Todo produto moderno, de carros a dispositivos médicos, depende de milhões de linhas de software. Um único bug não detectado pode causar interrupções, brechas de segurança ou recalls dispendiosos. Por isso, empresas investem pesado em testes, mas ainda têm dificuldade para localizar o pequeno número de trechos de código realmente arriscados enterrados em projetos gigantescos. Este estudo explora uma nova forma de ensinar computadores a focalizar esses pontos de risco de maneira mais confiável e com menos dados.
O problema do desbalanceamento em projetos reais
Em bases de código reais, a maioria dos arquivos funciona conforme o esperado, enquanto apenas uma pequena fração contém defeitos. Essa mistura desigual confunde muitas ferramentas de predição, que veem principalmente exemplos “limpos” e aprendem a assumir que tudo está bem. O resultado é um modelo que parece preciso no papel, mas frequentemente perde os defeitos raros e críticos que importam mais. Tentativas anteriores para corrigir isso incluíram excluir alguns exemplos limpos ou copiar e ajustar levemente os poucos exemplos com bugs, mas ambas as estratégias ou descartam informação ou geram dados repetitivos e pouco realistas.
Uma forma mais leve de criar exemplos realistas com bugs
O artigo apresenta o GeNSDP, uma abordagem nova que enfrenta esse desbalanceamento gerando exemplos adicionais e realistas com bugs antes de treinar um preditor. Em vez de máquinas pesadas e complexas de aprendizado profundo, o GeNSDP usa um modelo generativo enxuto que opera ao longo de uma única dimensão numérica de métricas de software. Ele aprende o padrão estatístico básico de módulos com bugs conhecidos e então cria novos pontos artificiais que seguem o mesmo padrão, enriquecendo o conjunto de amostras “com bug” sem simplesmente clonar os existentes. Esses exemplos sintéticos são então combinados com os dados originais e alimentam uma rede neural profunda que aprende a distinguir módulos de código arriscados dos seguros.
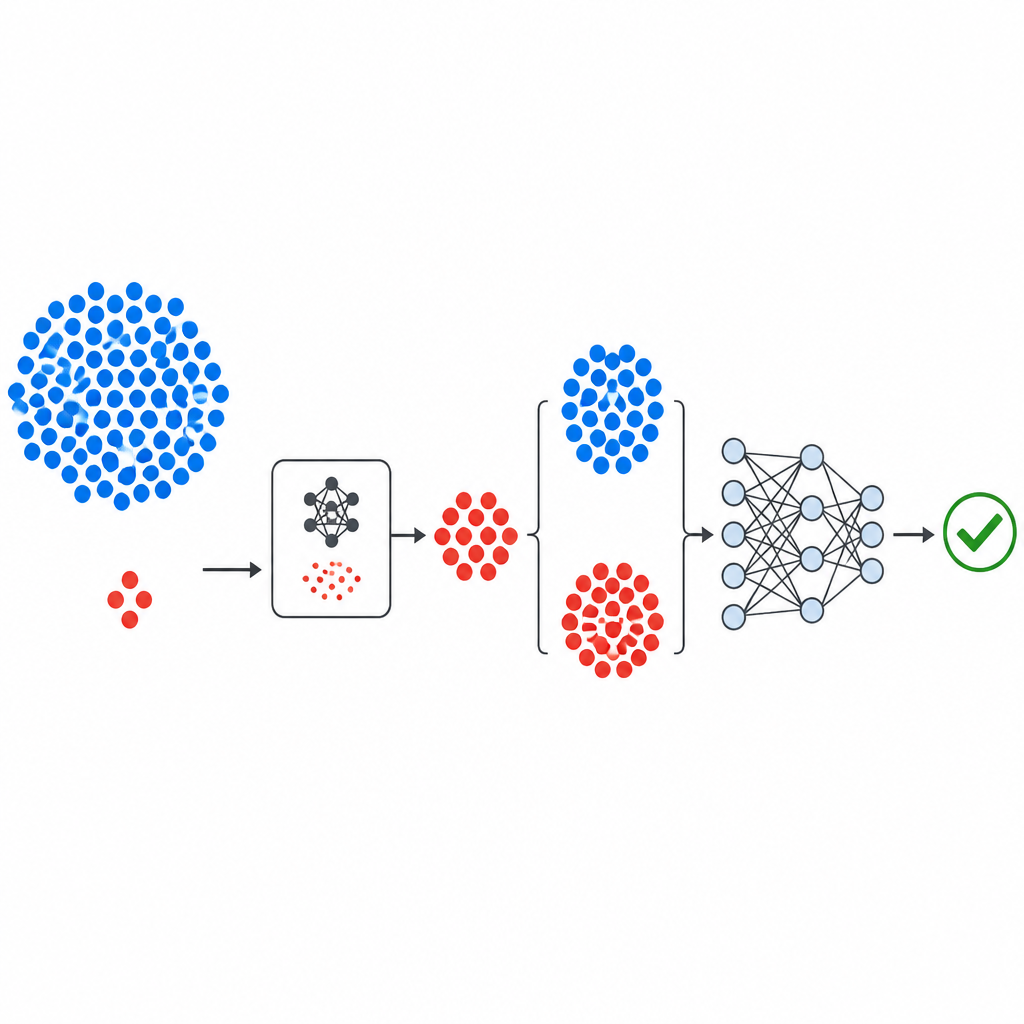
Como o novo pipeline é construído
O fluxo de trabalho começa com conjuntos de dados públicos de defeitos bem conhecidos da NASA e do repositório PROMISE, cada um descrevendo módulos de software usando um pequeno conjunto de medidas numéricas mais um rótulo indicando se o módulo foi encontrado como buggy ou limpo. As medições são padronizadas para que nenhuma métrica domine. O componente generativo do GeNSDP então se concentra apenas nos escassos módulos com bugs, aprendendo suas faixas típicas e variação. Ele produz repetidamente novos pontos sintéticos com bugs e os mistura com os dados originais até que as duas classes fiquem mais equilibradas. Esse conjunto ampliado é dividido em partes de treinamento e teste de forma cuidadosa para que nenhuma informação sintética vaze para a etapa de avaliação.
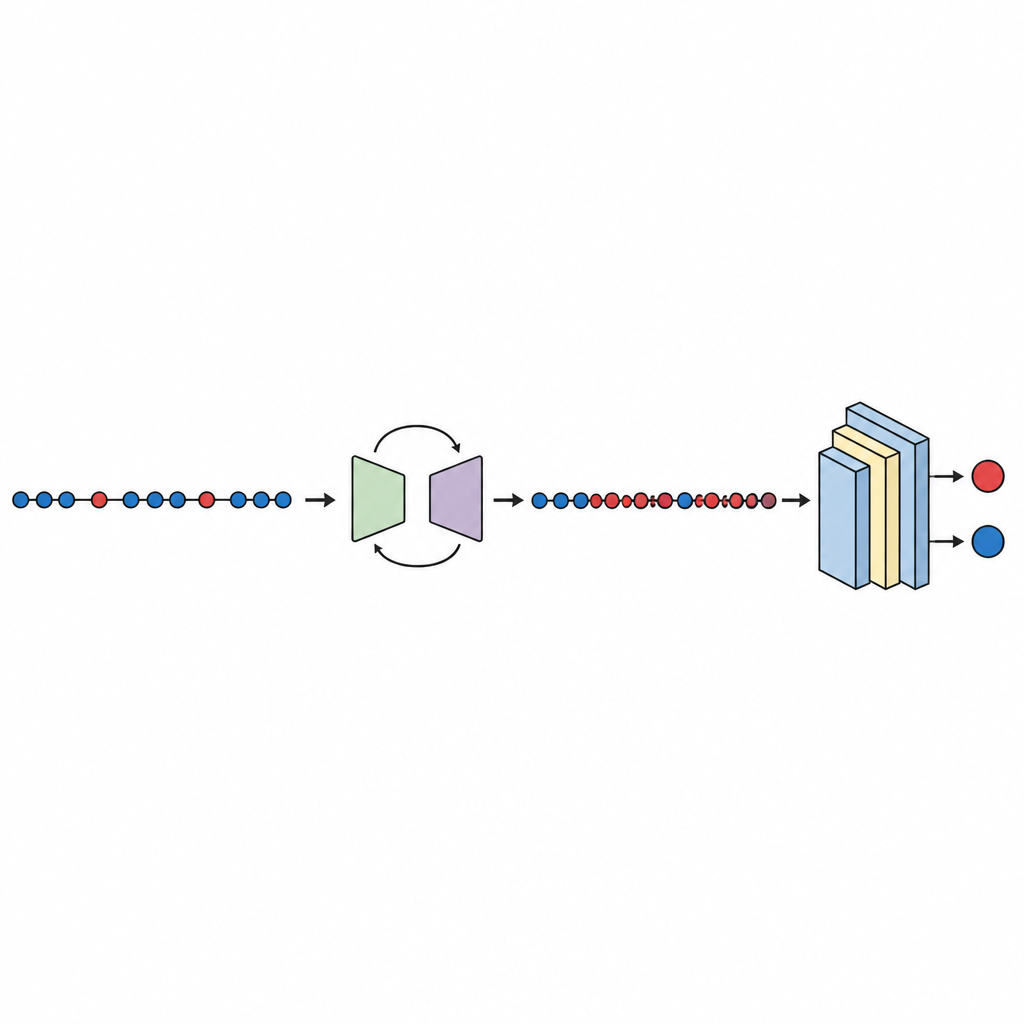
Testes, comparação e confiança nos resultados
Com os dados balanceados em mãos, uma rede neural profunda compacta é treinada e avaliada usando validação cruzada de dez vezes, que rotaciona qual parte dos dados é usada para teste. O estudo verifica várias métricas de desempenho, concentrando-se na área sob a curva (AUC), uma medida padrão de quão bem o modelo separa módulos com bugs dos limpos mesmo quando um grupo é muito menor. Em dez conjuntos de dados, o GeNSDP alcança uma AUC média de cerca de 99 por cento e uma alta medida F, indicando que ele não só encontra a maioria dos defeitos como também mantém baixos os falsos positivos. Os autores comparam seu método com ferramentas populares de sobremostragem, como cópia aleatória, SMOTE, MAHAKIL e COSTE, assim como com sistemas mais elaborados que combinam modelos generativos com aprendizes clássicos ou profundos. O GeNSDP apresenta desempenho consistentemente melhor, frequentemente por pontos percentuais de dois dígitos. Para evitar exageros, o estudo também usa testes estatísticos formais para confirmar que esses ganhos são improváveis de se dever ao acaso e verifica que as pontuações de treinamento e teste permanecem próximas, um sinal de que o modelo não está simplesmente decorando os dados.
O que isso significa para equipes de software
Para não especialistas, a principal conclusão é que o GeNSDP oferece uma forma prática de dar às ferramentas de previsão de defeitos mais “experiência” com os casos raros, mas importantes, de módulos com bugs, sem exigir grande poder de computação ou ajuste intricado de modelos. Ao simular levemente como módulos adicionais com bugs poderiam ser e em seguida usar esses exemplos para treinar uma rede profunda, o método ajuda a concentrar atenção nas partes de um código que têm maior probabilidade de causar problemas. Os achados sugerem que mesmo uma forma simples de modelagem generativa, usada com cuidado, pode tornar a triagem automática de bugs mais equilibrada, mais estável e mais fácil de aplicar em diferentes projetos.
Citação: Goyal, S.R. A novel generative oversampling for software defect prediction. Sci Rep 16, 15957 (2026). https://doi.org/10.1038/s41598-026-41981-7
Palavras-chave: previsão de defeitos de software, desbalanceamento de classes, sobreamostragem generativa, aprendizado profundo, GAN