Clear Sky Science · ar
توليد زائد جديد للتغلب على عدم التوازن في التنبؤ بعيوب البرمجيات
لماذا تهم العيوب البرمجية المخفية
تعتمد كل منتج حديث، من السيارات إلى الأجهزة الطبية، على ملايين الأسطر من الشيفرة. قد يتسبب خطأ واحد غير مكتشف في انقطاعات، ثغرات أمنية، أو سحوبات مكلفة. لذلك تستثمر الشركات كثيراً في الاختبار، ومع ذلك تظل تواجه صعوبة في اكتشاف العدد القليل من قطع الشيفرة الخطرة المدفونة داخل مشاريع ضخمة. تستعرض هذه الدراسة طريقة جديدة لتعليم الحواسيب التركيز على تلك النقاط الخطرة بشكل أكثر موثوقية وبحاجة إلى بيانات أقل.
مشكلة عدم التوازن في المشاريع الحقيقية
في قواعد الشيفرة الحقيقية، تعمل معظم الملفات كما هو مقرر، بينما يحتوي جزء صغير فقط على عيوب. هذا الاختلال يربك العديد من أدوات التنبؤ، التي ترى في الغالب أمثلة "نظيفة" وتتعلم افتراض أن كل شيء سليم. النتيجة نموذج يبدو دقيقاً نظرياً لكنه غالباً ما يفشل في اكتشاف العيوب النادرة والحاسمة. شملت محاولات سابقة لمعالجة ذلك حذف بعض الأمثلة النظيفة أو نسخ وتعديل القليل من الأمثلة الخاطئة، لكن كلا الأسلوبين إما يلقي معلومات بعيداً أو ينتج بيانات متكررة وغير واقعية.
طريقة أخف لإنتاج أمثلة خاطئة واقعية
تقدّم الورقة GeNSDP، نهجاً جديداً يعالج هذا الاختلال عن طريق توليد أمثلة خاطئة إضافية وواقعية قبل تدريب منظّر العيوب. بدلاً من آلات التعلم العميق الثقيلة والمعقدة، يستخدم GeNSDP نموذجاً توليدياً مبسّطاً يعمل على خط رقمي واحد من مقاييس البرمجيات. يتعلّم النمط الإحصائي الأساسي للوحدات المعروفة بأنها بها أخطاء ثم ينشئ نقاطاً صناعية جديدة تتبع نفس النمط، مما يثري مجموعة عينات "العيوب" دون مجرد استنساخ الأمثلة الحالية. تُدمج هذه الأمثلة الصناعية بعد ذلك مع البيانات الأصلية وتُغذى إلى شبكة عصبية عميقة تتعلم التمييز بين الوحدات البرمجية الخطرة والآمنة.
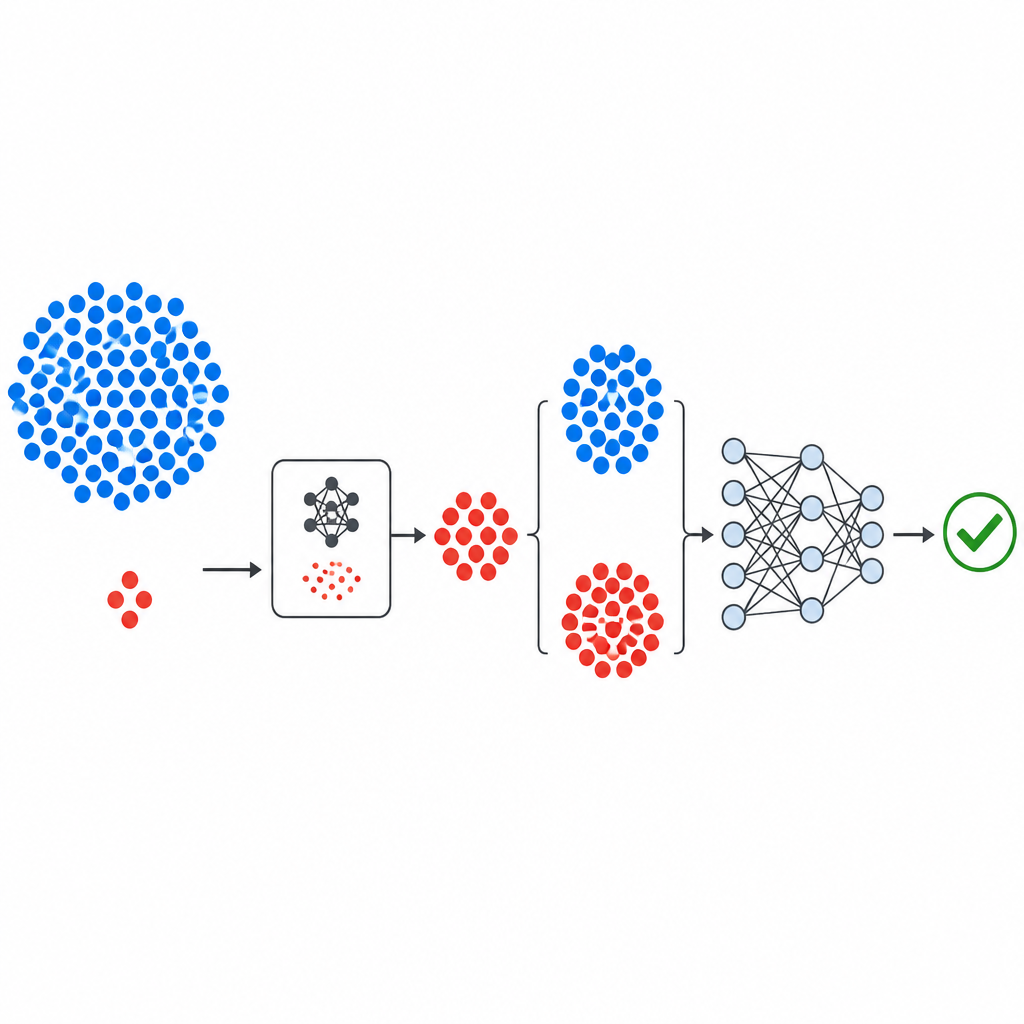
كيف بُنيت السلسلة الجديدة
يبدأ سير العمل بمجموعة بيانات عيوب عامة معروفة من ناسا ومستودع PROMISE، تصف كل منها وحدات برمجية باستخدام مجموعة صغيرة من القياسات الرقمية بالإضافة إلى تسميه تشير ما إذا كانت الوحدة تحتوي عيباً أو نظيفة. تُوحَّد القياسات بحيث لا يهيمن مقياس واحد على الباقي. يركز المكوّن التوليدي في GeNSDP بعد ذلك فقط على الوحدات الخاطئة النادرة، فيتعلم نطاقاتها النموذجية وتباينها. ينتج مراراً نقاطاً صناعية خاطئة جديدة ويخلطها مع البيانات الأصلية حتى تصبح الفئتان أكثر توازناً. تُقسّم مجموعة البيانات الموسعة إلى أجزاء تدريب واختبار بعناية بحيث لا يتسرب أي معلومات صناعية إلى خطوة التقييم.
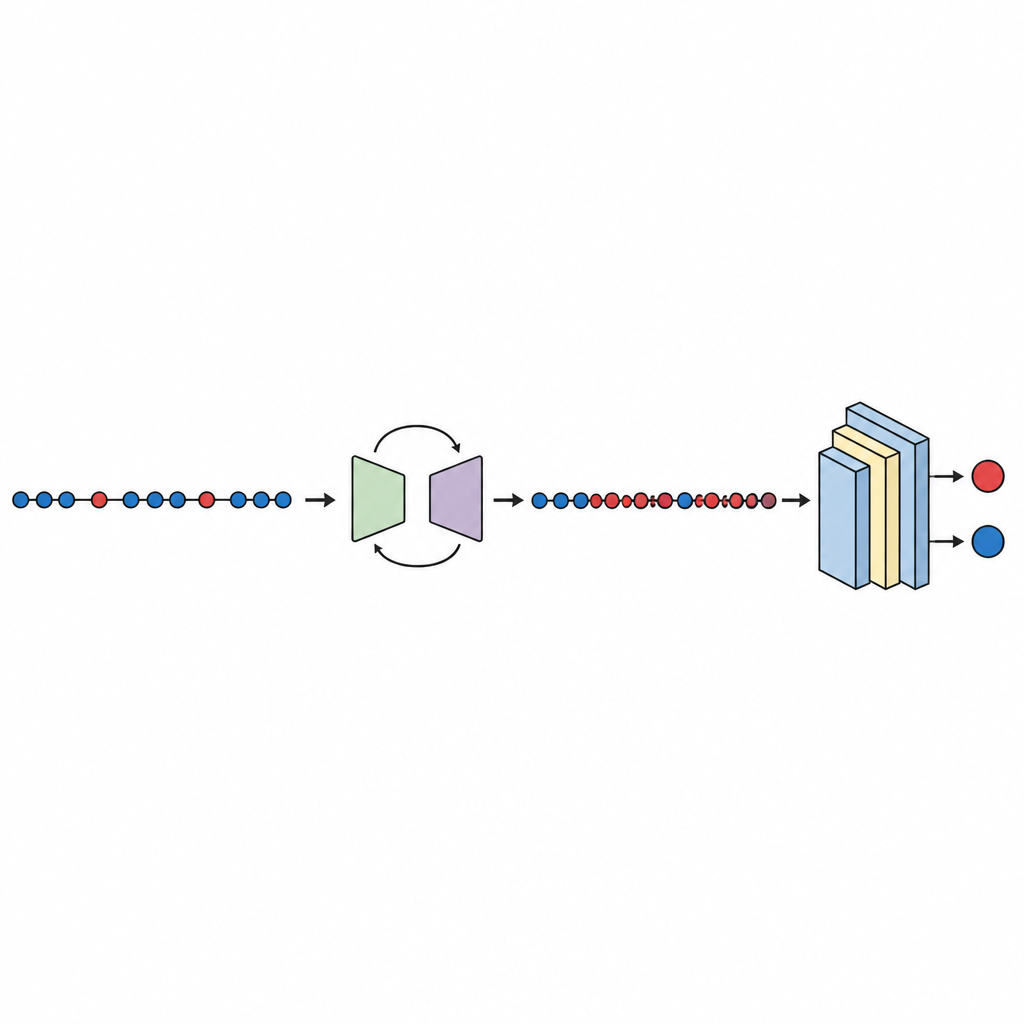
الاختبار والمقارنة ومدى الثقة في النتائج
بعد تحقيق التوازن في البيانات، تُدرّب شبكة عصبية عميقة مدمجة وتُقيّم باستخدام تحقق متقاطع بعشر طيات، الذي يدوّر أي جزء من البيانات يُستخدم للاختبار. تفحص الدراسة عدة مقاييس أداء، مع التركيز على المساحة تحت المنحنى (AUC)، وهو مقياس قياسي لمدى قدرة النموذج على فصل الوحدات الخاطئة عن النظيفة حتى عندما تكون إحدى المجموعات أصغر بكثير. عبر عشر مجموعات بيانات، يصل GeNSDP إلى متوسط AUC يقارب 99 في المئة ودرجة F عالية، ما يشير إلى أنه لا يكتشف معظم العيوب فحسب بل يحافظ أيضاً على إنذارات خاطئة منخفضة. يقارن المؤلفون طريقتهم بأدوات توليد زائد شهيرة مثل النسخ العشوائي، SMOTE، MAHAKIL، وCOSTE، وكذلك مع أنظمة أكثر تعقيداً تمزج نماذج توليدية مع متعلمين كلاسيكيين أو عميقين. يتفوق GeNSDP باستمرار، غالباً بفروق نسبية ذات رقمين. ولتجنب المبالغة، تستخدم الدراسة أيضاً اختبارات إحصائية رسمية لتؤكد أن هذه المكاسب من غير المرجح أن تكون نتيجة مصادفة وتتحقق من أن درجات التدريب والاختبار تبقى متقاربة، علامة على أن النموذج لا يحفظ البيانات فقط.
ما يعنيه هذا لفرق البرمجيات
لغير المتخصصين، المأخوذ الأساسي هو أن GeNSDP يقدم وسيلة عملية لمنح أدوات التنبؤ بالعيوب "خبرة" أكبر بالحالات الشاذة والنادرة لكنها مهمة، دون مطالبة بطاقة حاسوبية ضخمة أو ضبط نماذج معقد. من خلال محاكاة خفيفة لكيفية ظهور وحدات خاطئة إضافية ثم استخدام هذه الأمثلة لتدريب شبكة عميقة، تساعد الطريقة على توجيه الانتباه إلى أجزاء قاعدة الشيفرة الأكثر احتمالاً أن تسبب مشاكل. تشير النتائج إلى أن حتى شكل بسيط من النمذجة التوليدية، إذا استُخدم بعناية، يمكن أن يجعل فحص الأخطاء الآلي أكثر توازناً وأكثر استقراراً وأسهل تطبيقاً عبر مشاريع مختلفة.
الاستشهاد: Goyal, S.R. A novel generative oversampling for software defect prediction. Sci Rep 16, 15957 (2026). https://doi.org/10.1038/s41598-026-41981-7
الكلمات المفتاحية: التنبؤ بعيوب البرمجيات, عدم توازن الفئات, توليد زائد, التعلم العميق, GAN