Clear Sky Science · sv
En ny generativ oversampling för prediktion av programvarufel
Varför dolda programvarufel spelar roll
Varje modern produkt, från bilar till medicintekniska apparater, är beroende av miljontals kodrader. En enda oupptäckt bugg kan orsaka driftstopp, säkerhetshål eller kostsamma återkallelser. Företag satsar därför tungt på testning, men har ändå svårt att hitta det lilla antalet verkligt riskfyllda kodstycken gömda i stora projekt. Denna studie undersöker ett nytt sätt att lära datorer att fokusera på dessa riskzoner mer tillförlitligt och med mindre data.
Obalansproblemet i verkliga projekt
I verkliga kodbaser fungerar de flesta filer som avsett, medan endast en liten andel innehåller fel. Denna snedfördelning förvirrar många prediktionsverktyg, som mest ser "rena" exempel och lär sig anta att allt är okej. Resultatet blir en modell som ser korrekt ut på papper men ofta missar de sällsynta, kritiska felen som spelar störst roll. Tidigare försök att åtgärda detta har innefattat att ta bort vissa rena exempel eller kopiera och lätt modifiera de få buggade exemplen, men båda strategierna antingen kastar bort information eller skapar repetitiva, orealistiska data.
Ett lättare sätt att skapa realistiska buggade exempel
Artikeln introducerar GeNSDP, en ny metod som tar itu med denna obalans genom att generera ytterligare, trovärdiga buggade exempel innan man tränar en prediktor. Istället för tung och komplex djupinlärningsmaskineri använder GeNSDP en strömlinjeformad generativ modell som arbetar längs en enkel numerisk axel av programvarumått. Den lär sig de grundläggande statistiska mönstren hos kända buggade moduler och skapar sedan nya artificiella punkter som följer samma mönster, vilket berikar mängden "buggade" prov utan att bara klona befintliga. Dessa syntetiska exempel kombineras sedan med originaldata och matas in i ett djupt neuralt nätverk som lär sig skilja mellan riskfyllda och säkra kodmoduler.
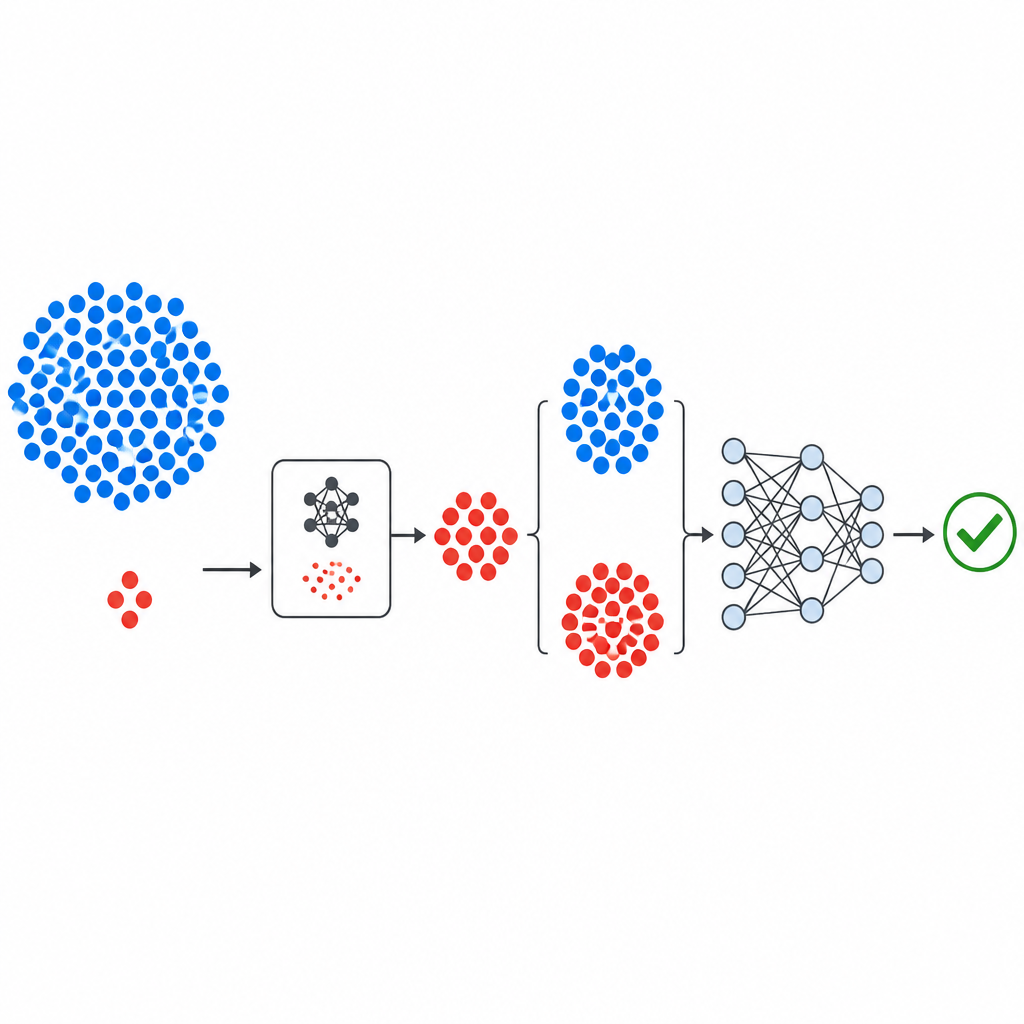
Hur den nya pipeline:n är uppbyggd
Arbetsflödet börjar med välkända publika fel-dataset från NASA och PROMISE-förrådet, där varje dataset beskriver programvarumoduler med ett litet antal numeriska mått plus en etikett som anger om modulen hittades vara buggad eller ren. Måtten standardiseras så att inget enskilt mått dominerar. GeNSDP:s generativa komponent fokuserar sedan endast på de sällsynta buggade modulerna och lär sig deras typiska intervall och variation. Den producerar upprepade gånger nya syntetiska buggade punkter och blandar dem med originaldata tills de två klasserna blir mer balanserade. Detta utökade dataset delas noggrant upp i tränings- och testdelar så att ingen syntetisk information läcker in i utvärderingssteget.
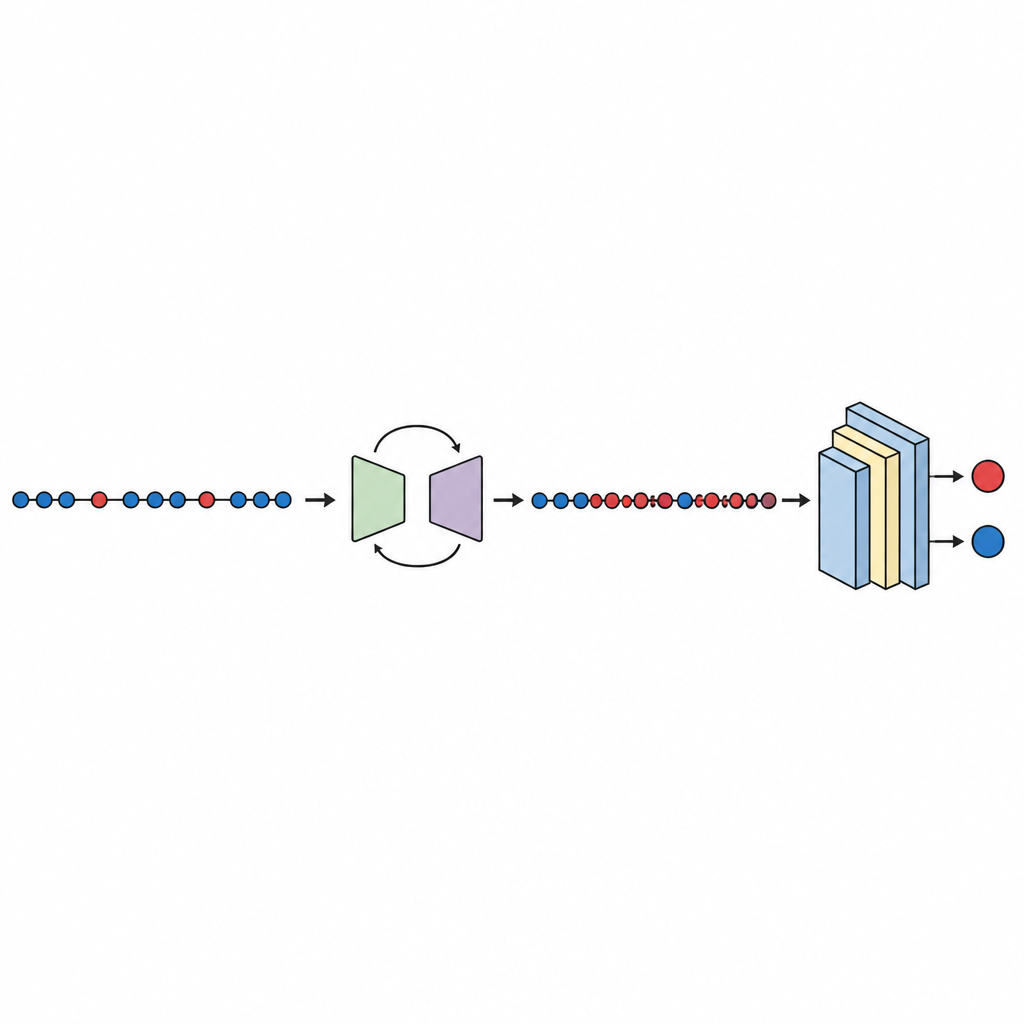
Testning, jämförelse och förtroende för resultaten
Med de balanserade data på plats tränas och utvärderas ett kompakt djupt neuralt nätverk med hjälp av tiofaldig korsvalidering, där vilken del av data som används för test roteras. Studien kontrollerar flera prestandamått, med fokus på area under kurvan (AUC), ett standardmått för hur väl modellen separerar buggade från rena moduler även när ena gruppen är mycket mindre. Över tio dataset når GeNSDP en genomsnittlig AUC på cirka 99 procent och en hög F-mått, vilket indikerar att metoden inte bara hittar de flesta felen utan också håller falsklarmen låga. Författarna jämför sin metod med populära oversampling-verktyg såsom slumpmässig kopiering, SMOTE, MAHAKIL och COSTE, samt med mer omfattande system som kombinerar generativa modeller med klassiska eller djupa inlärningsmetoder. GeNSDP presterar konsekvent bättre, ofta med tvåsiffriga procentenheter. För att undvika överdrivna påståenden använder studien även formella statistiska tester för att bekräfta att dessa vinster sannolikt inte beror på slumpen och kontrollerar att tränings- och testpoäng förblir nära varandra, ett tecken på att modellen inte bara memorerar.
Vad detta betyder för programvaruteam
För icke-specialister är huvudpoängen att GeNSDP erbjuder ett praktiskt sätt att ge prediktionsverktyg mer "erfarenhet" av de sällsynta men viktiga buggfynden, utan att kräva enorm beräkningskraft eller invecklad modellinställning. Genom att lätt simulera hur ytterligare buggade moduler kan se ut och sedan använda dessa exempel för att träna ett djupt nätverk hjälper metoden att rikta uppmärksamheten mot de delar av en kodbas som mest sannolikt orsakar problem. Resultaten tyder på att även en enkel form av generativ modellering, använd med omsorg, kan göra automatisk bugggranskning mer balanserad, stabil och lättare att tillämpa över olika projekt.
Citering: Goyal, S.R. A novel generative oversampling for software defect prediction. Sci Rep 16, 15957 (2026). https://doi.org/10.1038/s41598-026-41981-7
Nyckelord: prediktion av programvarufel, klassobalans, generativ oversampling, djupinlärning, GAN