Clear Sky Science · it
Una nuova sovracampionatura generativa per la previsione dei difetti software
Perché i difetti nascosti nel software contano
Ogni prodotto moderno, dalle automobili ai dispositivi medici, dipende da milioni di righe di software. Un singolo bug non rilevato può causare interruzioni, falle di sicurezza o richiami costosi. Le aziende investono molto nei test, ma faticano comunque a individuare il piccolo numero di parti effettivamente rischiose sepolte in progetti enormi. Questo studio esplora un nuovo modo per insegnare ai computer a concentrare l’attenzione su quei punti critici in modo più affidabile e con meno dati.
Il problema dello sbilanciamento nei progetti reali
Nei codebase reali la maggior parte dei file funziona come previsto, mentre solo una piccola frazione contiene difetti. Questa composizione sbilanciata confonde molti strumenti di previsione, che vedono prevalentemente esempi “puliti” e imparano a dare per scontato che tutto sia a posto. Il risultato è un modello che sembra accurato sulla carta ma che spesso non rileva i rari difetti critici che contano di più. I tentativi precedenti per risolvere il problema includevano cancellare alcuni esempi puliti o copiare e modificare leggermente i pochi esempi difettosi, ma entrambe le strategie o buttano via informazioni o generano dati ripetitivi e poco realistici.
Un modo più leggero per creare esempi difettosi realistici
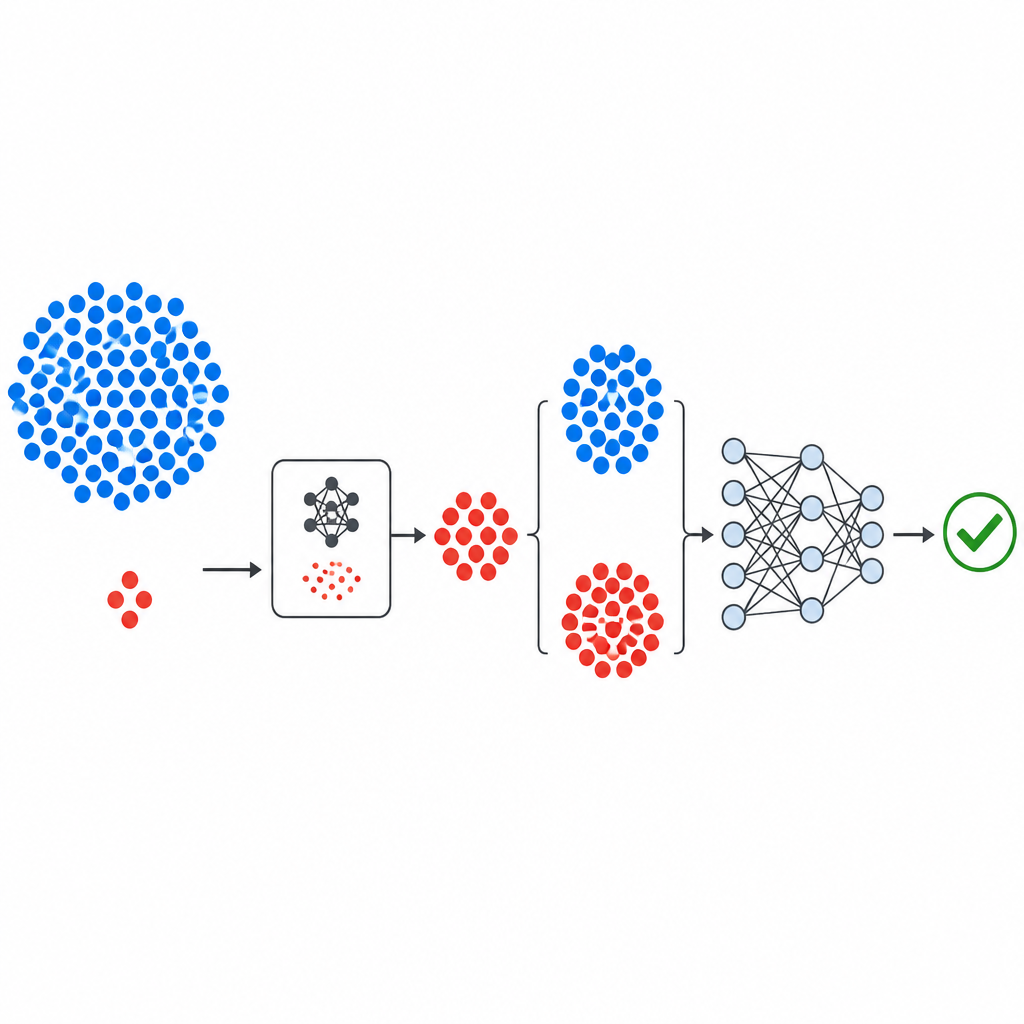
L’articolo introduce GeNSDP, un nuovo approccio che affronta questo sbilanciamento generando ulteriori esempi difettosi verosimili prima di addestrare un predittore. Invece di pesanti e complesse architetture di deep learning, GeNSDP usa un modello generativo snello che opera lungo una singola dimensione numerica di metriche software. Impara il modello statistico di base dei moduli noti come difettosi e poi crea nuovi punti artificiali che seguono lo stesso andamento, arricchendo il pool di campioni “difettosi” senza limitarsi a clonare quelli esistenti. Questi esempi sintetici vengono quindi combinati con i dati originali e forniti a una rete neurale profonda che impara a distinguere tra moduli rischiosi e sicuri.
Come è costruita la nuova pipeline
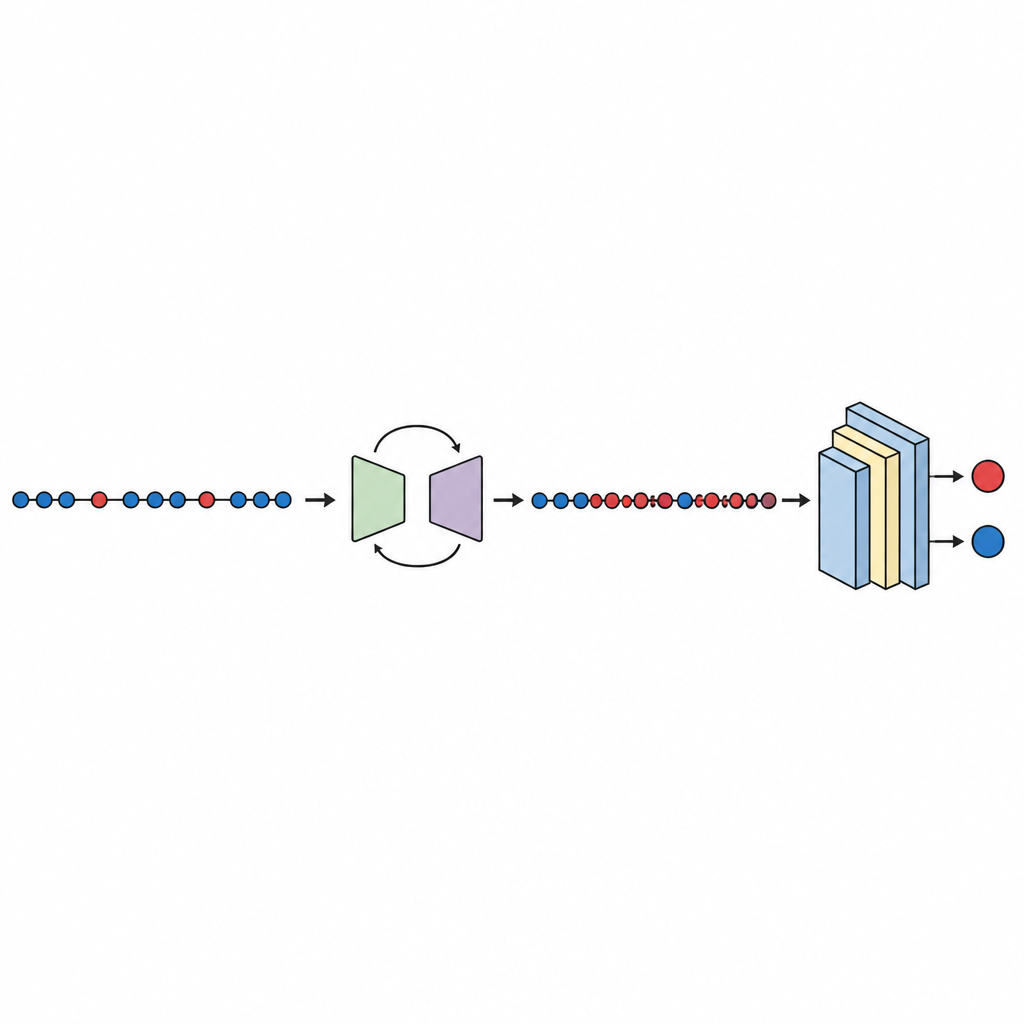
Il flusso di lavoro parte da noti dataset pubblici di difetti provenienti dalla NASA e dal repository PROMISE, ciascuno dei quali descrive moduli software usando un piccolo insieme di misure numeriche più un’etichetta che indica se il modulo è stato trovato difettoso o pulito. Le misure vengono standardizzate in modo che nessuna singola metrica domini. La componente generativa di GeNSDP si concentra poi solo sui rari moduli difettosi, apprendendone gli intervalli tipici e la variabilità. Produce ripetutamente nuovi punti difettosi sintetici e li miscela con i dati originali finché le due classi non risultano più bilanciate. Questo dataset ampliato viene diviso in parti di addestramento e test con attenzione, in modo che nessuna informazione sintetica trapeli nella fase di valutazione.
Test, confronti e affidabilità dei risultati
Con i dati bilanciati, viene addestrata e valutata una rete neurale profonda compatta usando la validazione incrociata a dieci pieghe, che ruota la porzione di dati usata per il test. Lo studio controlla diverse metriche di performance, concentrandosi sull’area sotto la curva (AUC), una misura standard di quanto bene il modello separa i moduli difettosi da quelli puliti anche quando un gruppo è molto più piccolo. Su dieci dataset, GeNSDP raggiunge una AUC media di circa il 99 percento e un elevato valore della F-measure, indicando che non solo trova la maggior parte dei difetti ma mantiene anche basso il numero di falsi allarmi. Gli autori confrontano il loro metodo con strumenti di sovracampionatura popolari come copia casuale, SMOTE, MAHAKIL e COSTE, nonché con sistemi più elaborati che combinano modelli generativi con learner classici o profondi. GeNSDP performa costantemente meglio, spesso con margini a due cifre percentuali. Per evitare affermazioni eccessive, lo studio usa anche test statistici formali per confermare che questi guadagni difficilmente siano dovuti al caso e verifica che i punteggi di training e test rimangano vicini, segno che il modello non si limita a memorizzare.
Cosa significa per i team di sviluppo software
Per i non specialisti, il messaggio chiave è che GeNSDP offre un modo pratico per dare agli strumenti di previsione dei difetti più “esperienza” con i rari ma importanti casi difettosi, senza richiedere grande potenza di calcolo o una taratura complessa dei modelli. Simulando leggermente come potrebbero apparire moduli difettosi aggiuntivi e poi usando questi esempi per addestrare una rete profonda, il metodo aiuta a concentrare l’attenzione sulle parti di un codebase più probabili a causare problemi. I risultati suggeriscono che anche una forma semplice di modellazione generativa, se usata con cura, può rendere il controllo automatico dei bug più bilanciato, più stabile e più facile da applicare a progetti diversi.
Citazione: Goyal, S.R. A novel generative oversampling for software defect prediction. Sci Rep 16, 15957 (2026). https://doi.org/10.1038/s41598-026-41981-7
Parole chiave: previsione dei difetti software, sbilanciamento delle classi, sovracampionatura generativa, deep learning, GAN