Clear Sky Science · es
Un novedoso sobremuestreo generativo para la predicción de defectos de software
Por qué importan los fallos ocultos en el software
Cualquier producto moderno, desde automóviles hasta dispositivos médicos, depende de millones de líneas de software. Un único error no detectado puede provocar interrupciones, brechas de seguridad o costosas retiradas de producto. Por eso las empresas invierten mucho en pruebas, pero aún así les cuesta localizar el pequeño número de fragmentos de código realmente riesgosos escondidos en proyectos enormes. Este estudio explora una nueva forma de enseñar a los ordenadores a centrarse en esos puntos críticos con más fiabilidad y con menos datos.
El problema del desbalance en proyectos reales
En las bases de código reales, la mayoría de los archivos funcionan como se espera, mientras que solo una pequeña fracción contiene defectos. Esa mezcla desigual confunde muchas herramientas de predicción, que ven sobre todo ejemplos “limpios” y aprenden a asumir que todo está bien. El resultado es un modelo que parece preciso sobre el papel pero que con frecuencia pasa por alto los defectos raros y críticos que más importan. Intentos anteriores para corregir esto han incluido eliminar algunos ejemplos limpios o copiar y modificar ligeramente los pocos defectuosos, pero ambas estrategias o bien descartan información o bien generan datos repetitivos e irreales.
Una forma más ligera de crear ejemplos defectuosos realistas
El artículo presenta GeNSDP, un nuevo enfoque que aborda este desbalance generando ejemplos defectuosos adicionales y verosímiles antes de entrenar un predictor. En lugar de maquinaria profunda y compleja, GeNSDP emplea un modelo generativo simplificado que opera a lo largo de una única línea numérica de métricas de software. Aprende el patrón estadístico básico de los módulos conocidos con fallos y luego crea nuevos puntos artificiales que siguen ese mismo patrón, enriqueciendo el conjunto de muestras “defectuosas” sin limitarse a clonar las existentes. Estos ejemplos sintéticos se combinan con los datos originales y se introducen en una red neuronal profunda que aprende a distinguir entre módulos riesgosos y seguros.
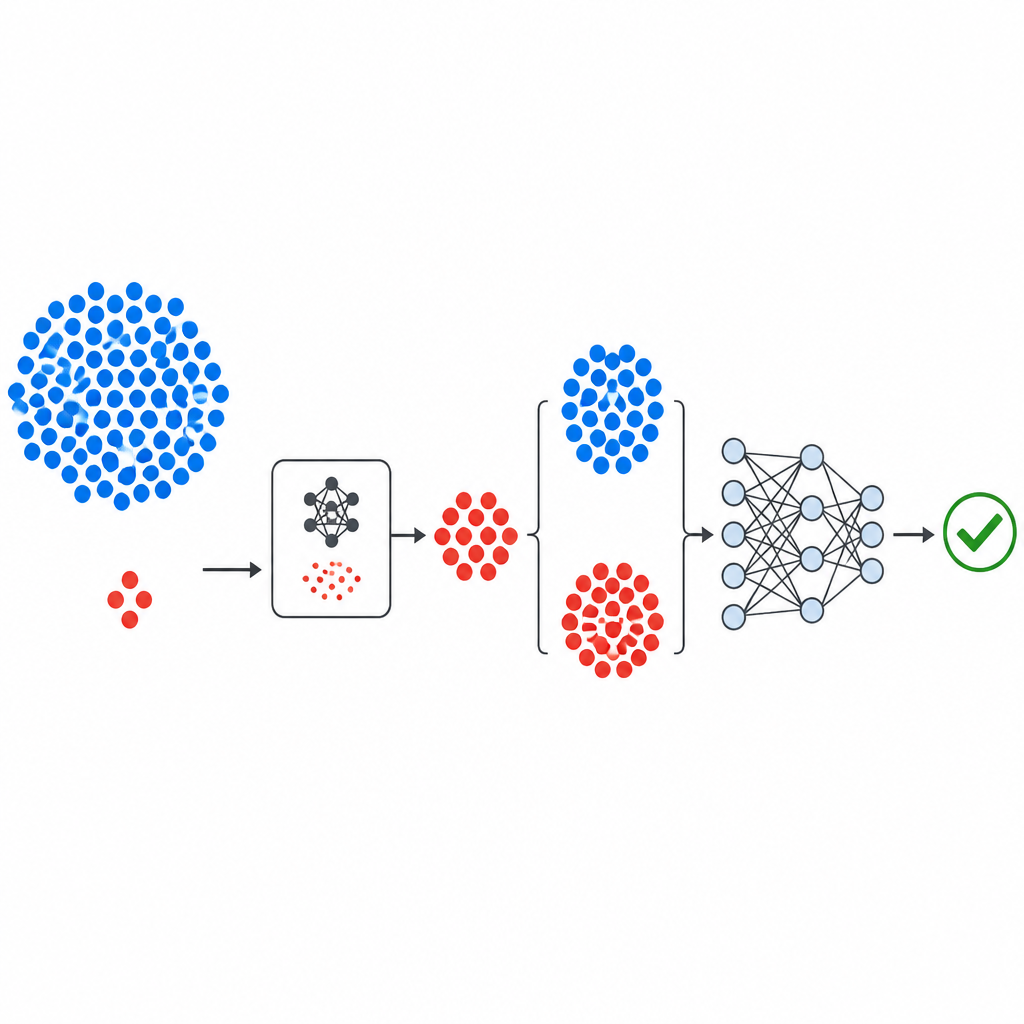
Cómo se construye la nueva canalización
El flujo de trabajo comienza con conjuntos de datos públicos y bien conocidos sobre defectos, procedentes de la NASA y del repositorio PROMISE, cada uno describiendo módulos de software mediante un pequeño conjunto de medidas numéricas más una etiqueta que indica si el módulo se encontró con fallos o limpio. Las medidas se estandarizan para que ninguna métrica domine. El componente generativo de GeNSDP entonces se centra únicamente en los escasos módulos con fallos, aprendiendo sus rangos típicos y su variación. Produce repetidamente nuevos puntos sintéticos defectuosos y los mezcla con los datos originales hasta que las dos clases estén más equilibradas. Este conjunto ampliado se divide en partes de entrenamiento y prueba de forma cuidadosa para que no se filtre información sintética en la fase de evaluación.
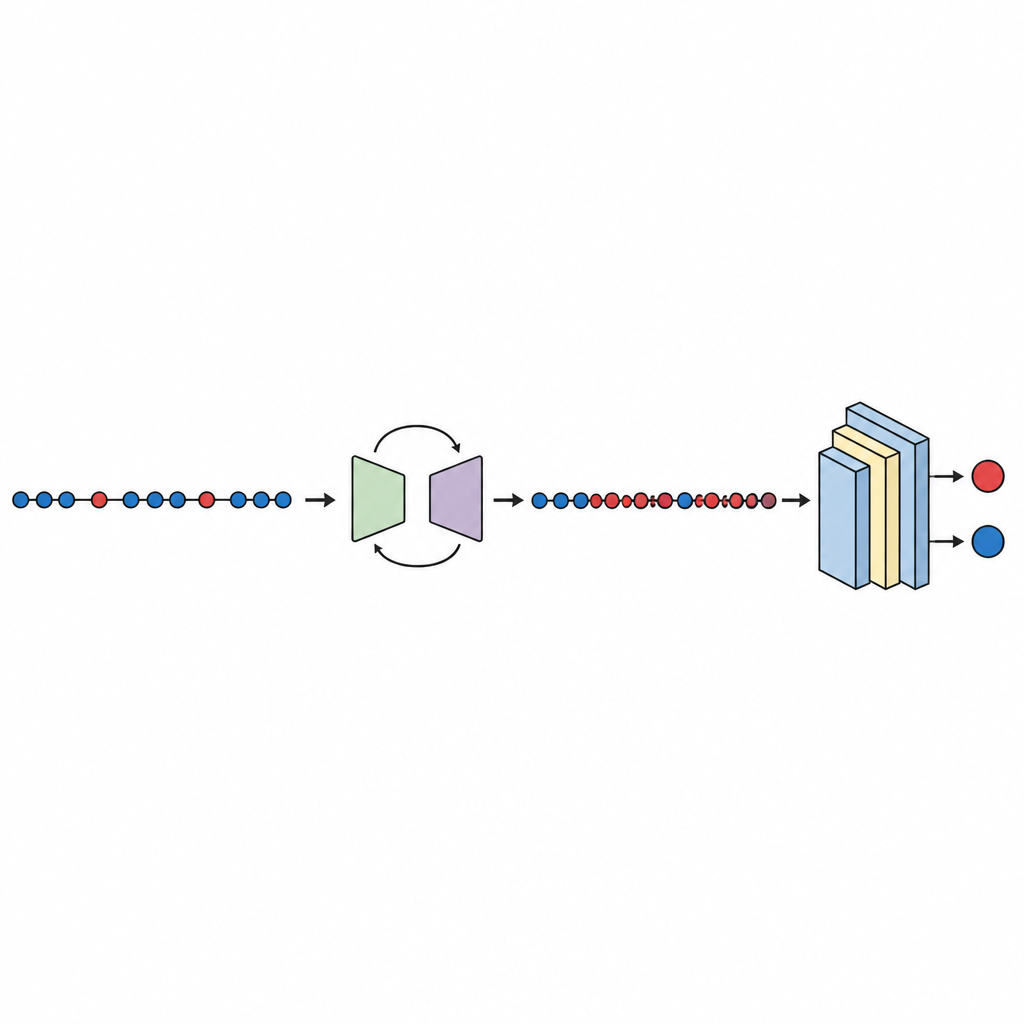
Pruebas, comparación y confianza en los resultados
Con los datos equilibrados, se entrena y evalúa una red neuronal profunda compacta usando validación cruzada de diez pliegues, que rota qué parte de los datos se emplea para la prueba. El estudio revisa varias métricas de rendimiento, centrando la atención en el área bajo la curva (AUC), una medida estándar de qué tan bien el modelo separa módulos defectuosos de limpios incluso cuando un grupo es mucho más pequeño. En diez conjuntos de datos, GeNSDP alcanza una AUC media de cerca del 99 por ciento y una alta medida F, lo que indica que no solo detecta la mayoría de los defectos sino que también mantiene bajos los falsos positivos. Los autores comparan su método con herramientas populares de sobremuestreo como la copia aleatoria, SMOTE, MAHAKIL y COSTE, así como con sistemas más elaborados que combinan modelos generativos con aprendices clásicos o profundos. GeNSDP rinde de forma consistente mejor, a menudo por puntos porcentuales de dos dígitos. Para evitar exageraciones, el estudio también usa pruebas estadísticas formales para confirmar que estas mejoras probablemente no se deben al azar y comprueba que las puntuaciones de entrenamiento y prueba se mantienen cercanas, una señal de que el modelo no está simplemente memorizando.
Qué significa esto para los equipos de desarrollo
Para los no especialistas, la conclusión principal es que GeNSDP ofrece una manera práctica de dar a las herramientas de predicción de defectos más “experiencia” con los casos defectuosos raros pero importantes, sin exigir gran potencia de cálculo ni ajustes de modelo intrincados. Al simular ligeramente cómo podrían ser módulos defectuosos adicionales y luego usar esos ejemplos para entrenar una red profunda, el método ayuda a centrar la atención en las partes de una base de código más propensas a causar problemas. Los hallazgos sugieren que incluso una forma simple de modelado generativo, usada con cuidado, puede hacer que el cribado automático de errores sea más equilibrado, más estable y más fácil de aplicar en distintos proyectos.
Cita: Goyal, S.R. A novel generative oversampling for software defect prediction. Sci Rep 16, 15957 (2026). https://doi.org/10.1038/s41598-026-41981-7
Palabras clave: predicción de defectos de software, desbalance de clases, sobremuestreo generativo, aprendizaje profundo, GAN