Clear Sky Science · de
Eine neuartige generative Oversampling-Methode zur Vorhersage von Softwarefehlern
Warum versteckte Softwarefehler wichtig sind
Jedes moderne Produkt, von Autos bis zu medizinischen Geräten, beruht auf Millionen von Codezeilen. Ein einziger unentdeckter Fehler kann Ausfälle, Sicherheitslücken oder teure Rückrufe auslösen. Deshalb investieren Firmen stark in Tests, doch ihnen fällt es weiterhin schwer, die wenigen wirklich riskanten Codeabschnitte in großen Projekten aufzuspüren. Diese Studie untersucht einen neuen Weg, Rechnern beizubringen, solche Risikostellen zuverlässiger und mit weniger Daten zu finden.
Das Ungleichgewicht in realen Projekten
In realen Codebasen funktionieren die meisten Dateien wie vorgesehen, nur ein kleiner Bruchteil enthält Defekte. Diese Schieflage verwirrt viele Vorhersagewerkzeuge, die überwiegend „saubere“ Beispiele sehen und lernen, davon auszugehen, dass alles in Ordnung ist. Das Ergebnis ist ein Modell, das auf dem Papier genau wirkt, aber oft die seltenen, kritischen Fehler übersieht, die am wichtigsten sind. Frühere Ansätze versuchten dies zu beheben, indem sie einige saubere Beispiele entfernten oder die wenigen fehlerhaften kopierten und leicht veränderten, doch beide Strategien werfen entweder Informationen weg oder erzeugen repetitive, unrealistische Daten.
Eine leichtere Methode, realistische fehlerhafte Beispiele zu erzeugen
Das Papier stellt GeNSDP vor, einen neuen Ansatz, der dieses Ungleichgewicht angeht, indem er vor dem Training eines Prädiktors zusätzliche, lebensnahe fehlerhafte Beispiele generiert. Statt schwerer und komplexer Deep-Learning-Architekturen verwendet GeNSDP ein schlankes generatives Modell, das entlang einer einzigen numerischen Achse von Softwaremetriken arbeitet. Es lernt das grundlegende statistische Muster bekannter fehlerhafter Module und erzeugt dann neue künstliche Punkte, die diesem Muster folgen, wodurch der Pool an „fehlerhaften“ Proben angereichert wird, ohne einfach vorhandene zu klonen. Diese synthetischen Beispiele werden anschließend mit den Originaldaten kombiniert und einem tiefen neuronalen Netzwerk zugeführt, das lernt, zwischen riskanten und sicheren Modulabschnitten zu unterscheiden.
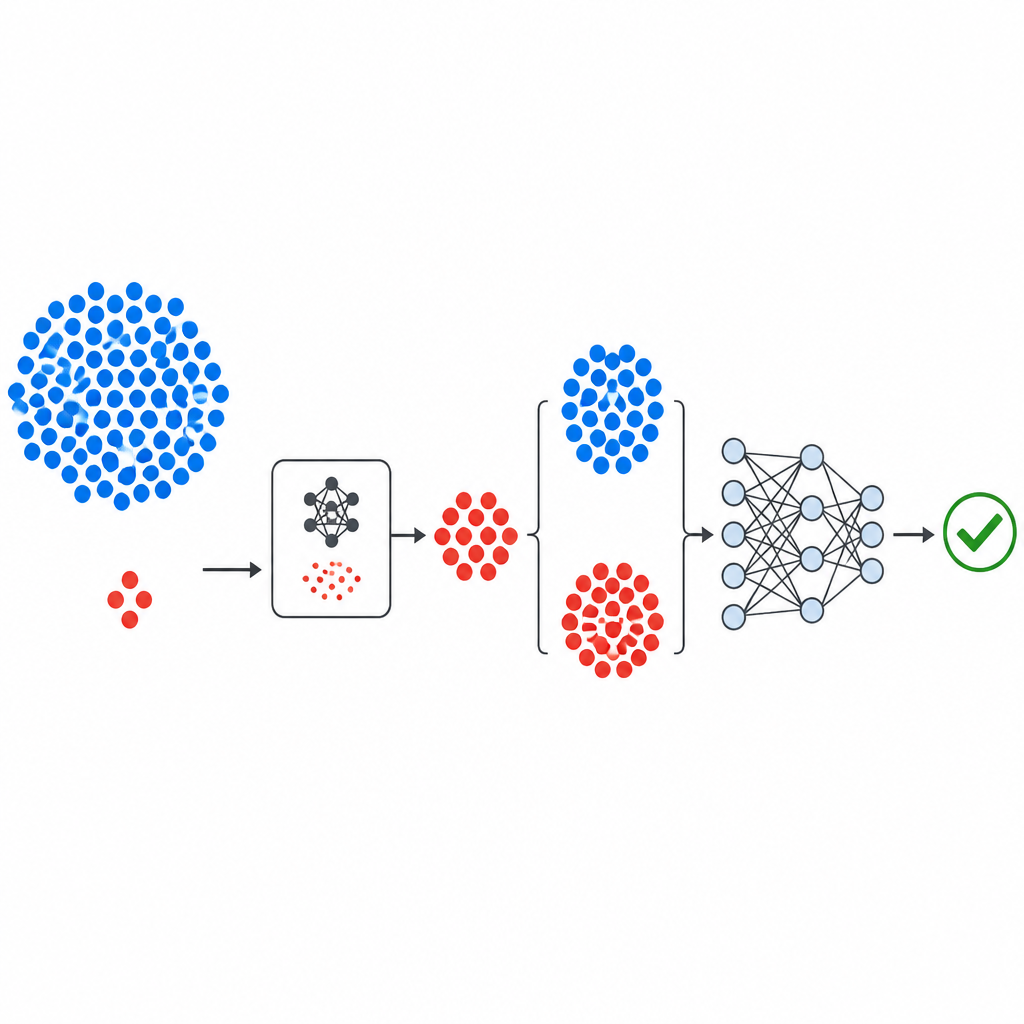
Wie die neue Pipeline aufgebaut ist
Der Arbeitsablauf beginnt mit bekannten öffentlichen Defektdatensätzen von der NASA und dem PROMISE-Repository, die jeweils Softwaremodule mit einer kleinen Menge numerischer Messwerte sowie einem Label versehen, das angibt, ob das Modul als fehlerhaft oder sauber befunden wurde. Die Messwerte werden standardisiert, sodass keine einzelne Metrik dominiert. Die generative Komponente von GeNSDP konzentriert sich dann ausschließlich auf die seltenen fehlerhaften Module und lernt deren typische Wertebereiche und Variationen. Sie erzeugt wiederholt neue synthetische fehlerhafte Punkte und mischt sie mit den Originaldaten, bis die beiden Klassen ausgeglichener sind. Dieser erweiterte Datensatz wird sorgfältig in Trainings- und Testteile aufgeteilt, sodass keine synthetischen Informationen in die Evaluationsphase „auslaufen“.
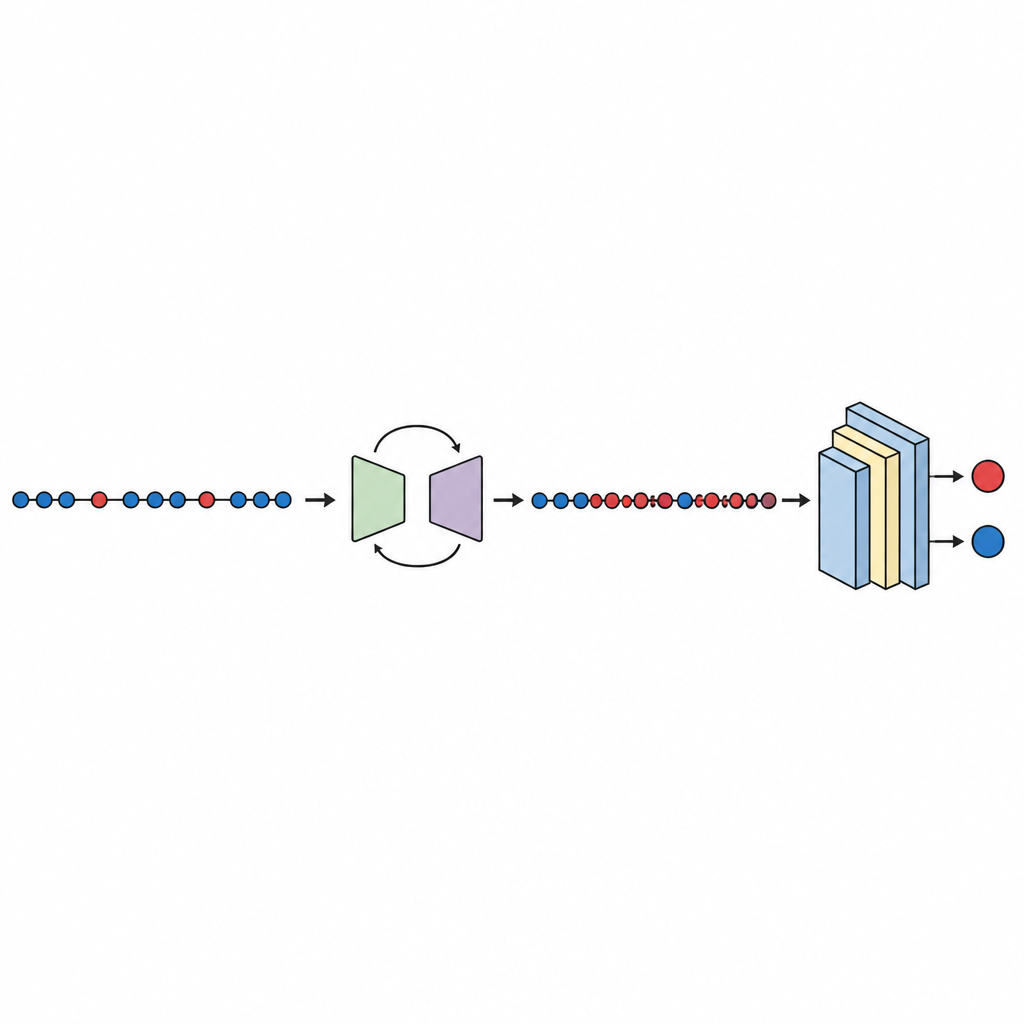
Test, Vergleich und Vertrauen in die Ergebnisse
Mit den ausgeglichenen Daten wird ein kompaktes tiefes neuronales Netzwerk trainiert und mittels zehnfacher Kreuzvalidierung bewertet, wobei jeweils ein anderer Teil der Daten für den Test verwendet wird. Die Studie prüft mehrere Leistungsmaße, mit Schwerpunkt auf der Fläche unter der Kurve (AUC), einem Standardmaß dafür, wie gut das Modell fehlerhafte von sauberen Modulen trennt, selbst wenn eine Gruppe deutlich kleiner ist. Über zehn Datensätze erreicht GeNSDP eine durchschnittliche AUC von etwa 99 Prozent sowie ein hohes F-Maß, was darauf hindeutet, dass es nicht nur die meisten Defekte findet, sondern auch die Anzahl falscher Alarme niedrig hält. Die Autoren vergleichen ihre Methode mit populären Oversampling-Methoden wie zufälligem Kopieren, SMOTE, MAHAKIL und COSTE sowie mit aufwändigeren Systemen, die generative Modelle mit klassischen oder tiefen Lernverfahren kombinieren. GeNSDP schneidet durchweg besser ab, häufig um zweistellige Prozentpunkte. Um Übertreibungen zu vermeiden, verwendet die Studie außerdem formale statistische Tests, um zu bestätigen, dass diese Verbesserungen wahrscheinlich nicht zufällig sind, und überprüft, dass Trainings- und Testergebnisse eng beieinanderliegen — ein Zeichen dafür, dass das Modell nicht einfach auswendig lernt.
Was das für Softwareteams bedeutet
Für Nicht-Fachleute lautet die wichtigste Erkenntnis, dass GeNSDP eine praktikable Möglichkeit bietet, Vorhersagewerkzeugen für Fehler mehr „Erfahrung“ mit den seltenen, aber wichtigen fehlerhaften Fällen zu geben, ohne enorme Rechenleistung oder aufwändige Modellanpassungen zu verlangen. Indem zusätzliche fehlerhafte Module leicht simuliert und diese Beispiele zum Training eines tiefen Netzwerks verwendet werden, hilft die Methode, die Aufmerksamkeit auf die Teile eines Codes zu lenken, die am ehesten Probleme verursachen. Die Ergebnisse legen nahe, dass selbst eine einfache Form generativer Modellierung, sorgfältig eingesetzt, automatisches Bug-Screening ausgewogener, stabiler und leichter auf verschiedene Projekte anwendbar machen kann.
Zitation: Goyal, S.R. A novel generative oversampling for software defect prediction. Sci Rep 16, 15957 (2026). https://doi.org/10.1038/s41598-026-41981-7
Schlüsselwörter: Vorhersage von Softwarefehlern, Klassenungleichgewicht, generatives Oversampling, Deep Learning, GAN