Clear Sky Science · ja
ソフトウェア欠陥予測のための新しい生成型オーバーサンプリング法
なぜ隠れたソフトウェアの欠陥が重要か
自動車から医療機器まで、現代の製品は何百万行ものソフトウェアに依存している。たった一つの未検出のバグが停止やセキュリティの脆弱性、あるいは大規模なリコールを招くことがある。そのため企業はテストに多大な投資を行うが、巨大なプロジェクトの中に埋もれたごく少数の本当に危険なコードを見つけ出すことは依然として難しい。本研究は、より少ないデータでもコンピュータにそのようなリスク箇所をより確実に特定させる新しい手法を探る。
実プロジェクトにおける不均衡の問題
実際のコードベースでは、大部分のファイルは意図どおりに動作し、欠陥を含むのはごく一部だ。その偏った割合は多くの予測ツールを混乱させる。ツールは主に「正常」な例を見て、すべてが問題ないと仮定するように学んでしまう。結果として、見かけ上は精度が高く見えても、最も重要な稀な重大欠陥を見逃すモデルになりがちだ。これを改善しようと以前に試みられた方法には、正常な例を一部削除するか、少ないバグ例をコピーして僅かに変形する方法があるが、どちらも情報を捨てるか、繰り返しで非現実的なデータを生むという問題がある。
現実的なバグ例を作るより軽い方法
本論文はGeNSDPを導入する。これは予測器を訓練する前に追加の現実味あるバグ例を生成することで不均衡に対処するアプローチだ。重厚で複雑な深層学習機構の代わりに、GeNSDPはソフトウェア指標の一列の数値上で動作する簡素化された生成モデルを用いる。既知のバグモジュールの基本的な統計的パターンを学習し、既存例を単に複製するのではなく同じパターンに従う新たな人工ポイントを作成して「バグあり」サンプルのプールを豊かにする。これらの合成例は元のデータと組み合わされ、リスクの高いモジュールと安全なモジュールを区別することを学ぶ深層ニューラルネットワークに供される。
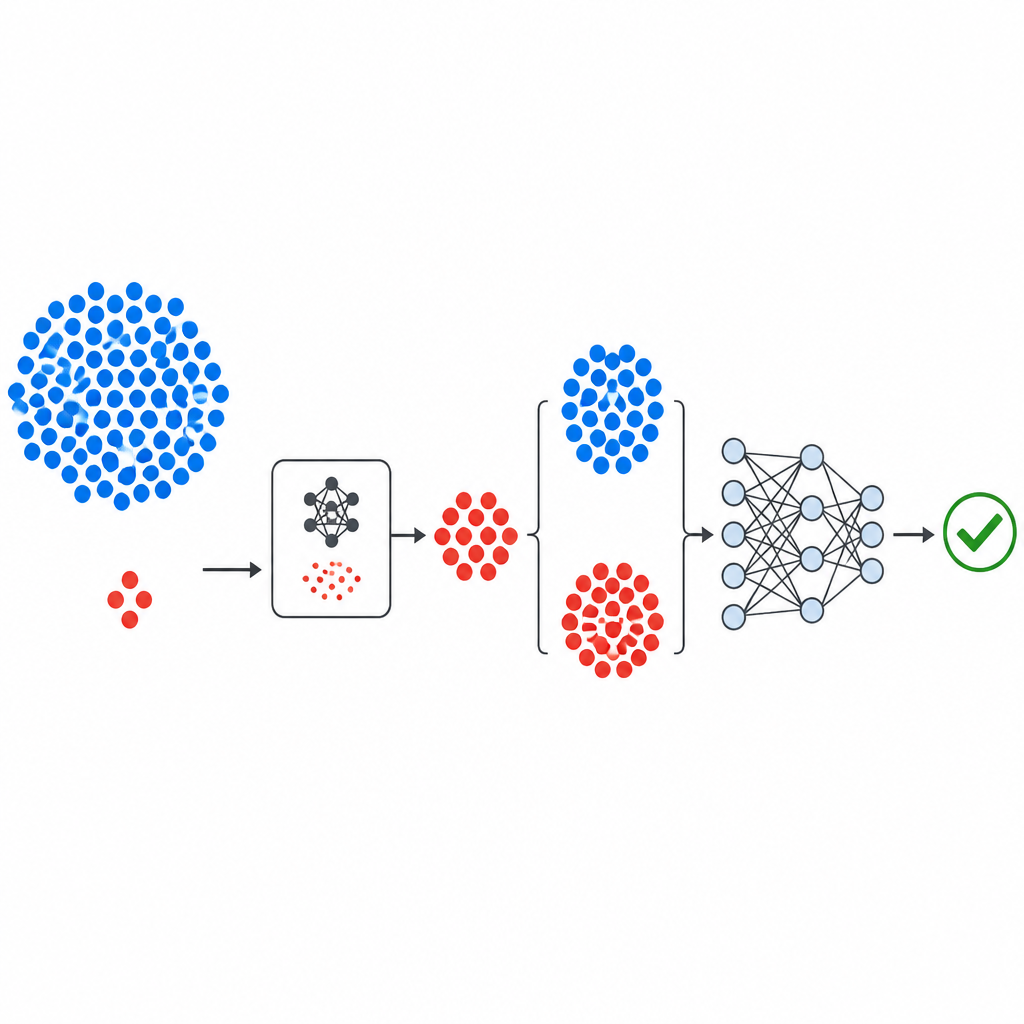
新しいパイプラインの構成
ワークフローはNASAやPROMISEリポジトリのよく知られた公開欠陥データセットから始まる。各データセットはソフトウェアモジュールを少数の数値的測定値と、モジュールがバグありか正常かを示すラベルで記述している。測定値は単一の指標が支配しないよう標準化される。GeNSDPの生成コンポーネントは希少なバグモジュールにのみ注目し、それらの典型的な範囲と変動を学習する。繰り返し新しい合成バグポイントを生成し、元データと混ぜ合わせて両クラスのバランスが改善されるまで続ける。この拡張されたデータセットは訓練とテストに慎重に分割され、評価段階に合成情報が漏れないようにする。
テスト、比較、結果への信頼
バランスを取ったデータが用意されると、小型の深層ニューラルネットワークを訓練し、十重交差検証で評価する。交差検証はどの部分がテストに使われるかを順に入れ替える方式だ。研究では複数の評価指標を確認し、特にAUC(曲線下面積)に注目する。AUCは一方のグループがずっと小さい場合でも、バグありと正常をどれだけうまく分離できるかを示す標準的な指標である。十のデータセット全体で、GeNSDPは平均約99パーセントのAUCと高いF値を達成し、ほとんどの欠陥を検出しつつ誤報を低く抑えていることを示した。著者らはランダムコピー、SMOTE、MAHAKIL、COSTEといった一般的なオーバーサンプリング手法や、生成モデルを古典的学習器や深層学習器と組み合わせたより複雑なシステムと比較した。GeNSDPは一貫して優れた性能を示し、しばしば二桁のパーセンテージ差で上回った。過大な主張を避けるため、研究はこれらの改善が偶然による可能性が低いことを示す正式な統計検定も用い、訓練スコアとテストスコアが近いままであることを確認して、単に暗記しているわけではないことも示している。
ソフトウェアチームにとっての意義
専門家でない人向けの要点は、GeNSDPが大規模な計算資源や複雑なモデル調整を必要とせずに、稀だが重要なバグ事例に関する予測ツールの「経験」を実用的に増やせる手段を提供することだ。追加のバグモジュールがどのように見えるかを軽くシミュレートし、それらの例を用いて深層ネットワークを訓練することで、この手法は問題を引き起こしやすいコードベースの部分に注意を向けるのに役立つ。結果は、単純な形の生成モデリングであっても、慎重に使えば自動化されたバグスクリーニングをよりバランス良く、より安定的に、異なるプロジェクト間で適用しやすくできることを示唆している。
引用: Goyal, S.R. A novel generative oversampling for software defect prediction. Sci Rep 16, 15957 (2026). https://doi.org/10.1038/s41598-026-41981-7
キーワード: ソフトウェア欠陥予測, クラス不均衡, 生成型オーバーサンプリング, 深層学習, GAN