Clear Sky Science · ru
Новый генеративный оверсэмплинг для предсказания дефектов в ПО
Почему скрытые дефекты ПО важны
Каждый современный продукт — от автомобилей до медицинских приборов — зависит от миллионов строк кода. Одна незамеченная ошибка может привести к сбоям, уязвимостям или дорогостоящему отзыву. Поэтому компании активно инвестируют в тестирование, но им всё равно сложно найти небольшое количество действительно рискованных фрагментов кода, скрытых в крупных проектах. В этом исследовании предлагается новый способ обучить компьютеры более надёжно и с меньшим объёмом данных фокусироваться на таких проблемных местах.
Проблема дисбаланса в реальных проектах
В реальных кодовых базах большинство файлов работают как задумано, тогда как лишь небольшая часть содержит дефекты. Такое несоответствие сбивает с толку многие инструменты предсказания: они в основном видят «чистые» примеры и вырабатывают предположение, что всё в порядке. В результате модель выглядит точной на бумаге, но часто пропускает редкие и критичные дефекты, которые имеют наибольшее значение. Ранее пытались исправить это удалением некоторых чистых примеров или копированием и лёгкой модификацией немногих проблемных — но оба подхода либо теряют ценную информацию, либо создают повторяющиеся, нереалистичные данные.
Более лёгкий способ создать правдоподобные проблемные примеры
В статье представлен GeNSDP — новый подход, который решает проблему дисбаланса путём генерации дополнительных правдоподобных проблемных примеров перед обучением предсказателя. Вместо тяжёлых и сложных механизмов глубокого обучения GeNSDP использует упрощённую генеративную модель, работающую вдоль одной числовой шкалы программных метрик. Она изучает базовый статистический паттерн известных проблемных модулей и затем создаёт новые искусственные точки, следующие тому же распределению, обогащая пул «ошибочных» образцов без простого клонирования существующих. Эти синтетические примеры затем объединяют с исходными данными и подают в глубокую нейронную сеть, которая учится различать рискованные и безопасные модули кода.
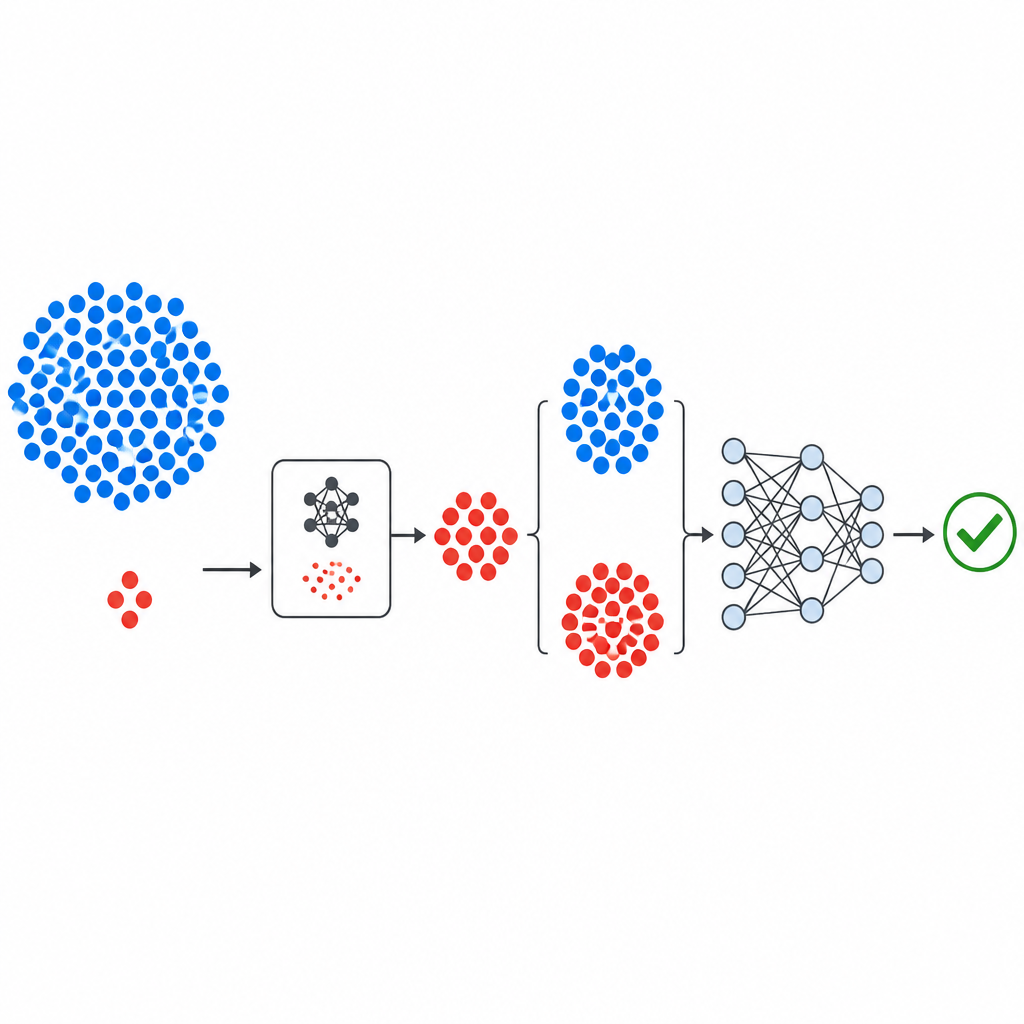
Как построен новый конвейер
Рабочий процесс начинается с хорошо известных публичных наборов данных о дефектах от NASA и репозитория PROMISE, каждый из которых описывает модули ПО с помощью небольшого набора числовых измерений и метки, указывающей, был ли модуль обнаружен как проблемный или чистый. Измерения стандартизируются, чтобы ни одна метрика не доминировала. Генеративный компонент GeNSDP затем концентрируется только на редких проблемных модулях, изучая их типичные диапазоны и вариативность. Он многократно порождает новые синтетические проблемные точки и смешивает их с исходными данными до тех пор, пока классы не станут более сбалансированными. Этот расширенный набор данных аккуратно разделяется на обучающую и тестовую части так, чтобы никакая синтетическая информация не «просочилась» в этап оценки.
Тестирование, сравнение и доверие к результатам
После балансировки данных обучается компактная глубокая нейронная сеть и оценивается с использованием десятикратной кросс-валидации, при которой меняются части данных, используемые для теста. В работе проверяются несколько показателей качества, с акцентом на площадь под кривой (AUC) — стандартную меру того, насколько хорошо модель отделяет проблемные модули от чистых, даже когда одна группа значительно меньше. По десяти наборам данных средний AUC GeNSDP составляет около 99 процентов, а высокое значение F-меры указывает, что метод не только находит большинство дефектов, но и сохраняет низкий уровень ложных тревог. Авторы сравнивают свой метод с популярными инструментами оверсэмплинга, такими как случайное копирование, SMOTE, MAHAKIL и COSTE, а также с более сложными системами, комбинирующими генеративные модели с классическими или глубокими алгоритмами. GeNSDP последовательно показывает лучшие результаты, часто с преимуществом в двузначных процентных пунктах. Чтобы не переоценивать выводы, исследование использует формальные статистические тесты, подтверждающие, что эти улучшения вряд ли случайны, и проверяет, что оценки на обучении и тесте остаются близкими — признак того, что модель не просто запоминает данные.
Что это значит для команд разработчиков
Для неспециалистов главный вывод таков: GeNSDP предлагает практичный способ дать инструментам предсказания дефектов больше «опыта» с редкими, но важными проблемными случаями, без необходимости в огромных вычислительных ресурсах или сложной настройке моделей. Лёгкая симуляция того, как могли бы выглядеть дополнительные проблемные модули, с последующим обучением на этих примерах помогает сосредоточить внимание на частях кода, наиболее вероятно вызывающих проблемы. Результаты показывают, что даже простая форма генеративного моделирования, применённая аккуратно, может сделать автоматическую проверку на ошибки более сбалансированной, стабильной и проще переносимой между проектами.
Цитирование: Goyal, S.R. A novel generative oversampling for software defect prediction. Sci Rep 16, 15957 (2026). https://doi.org/10.1038/s41598-026-41981-7
Ключевые слова: предсказание дефектов ПО, несбалансированность классов, генеративный оверсэмплинг, глубокое обучение, GAN