Clear Sky Science · zh
多代理系统与基于信誉的高级评分机制在事实核查中的应用
为什么核查网络声明很重要
每天,社交网络和新闻推送都会向我们轰炸有关科学、政治和健康的各种说法。有些是准确的,有些具有误导性,还有一些以微妙方式混合了真实与虚假。本文提出了一种新方法,通过让若干数字“事实核查者”协同工作,然后将它们的意见谨慎地合并为单一的可信度分数,来评估此类文本的可信性。
许多现有工具存在不足
随着大型语言模型的发展(这些模型驱动了现代聊天机器人等工具),自动化事实核查迅速增长。大多数现有系统侧重于简单的二元判断:一个陈述是真还是假?它们经常依赖单一信息来源,甚至仅依赖语言模型自身的知识。这在真实的在线讨论中带来两个问题。首先,语言模型往往过于自信,即使错误也会表现得很肯定。其次,真实帖子经常将正确与不正确的陈述混合在一起,因此对整段文字给出单一的真/假标签太粗糙,难以发挥作用。
用多个数字核查者替代单一核查者
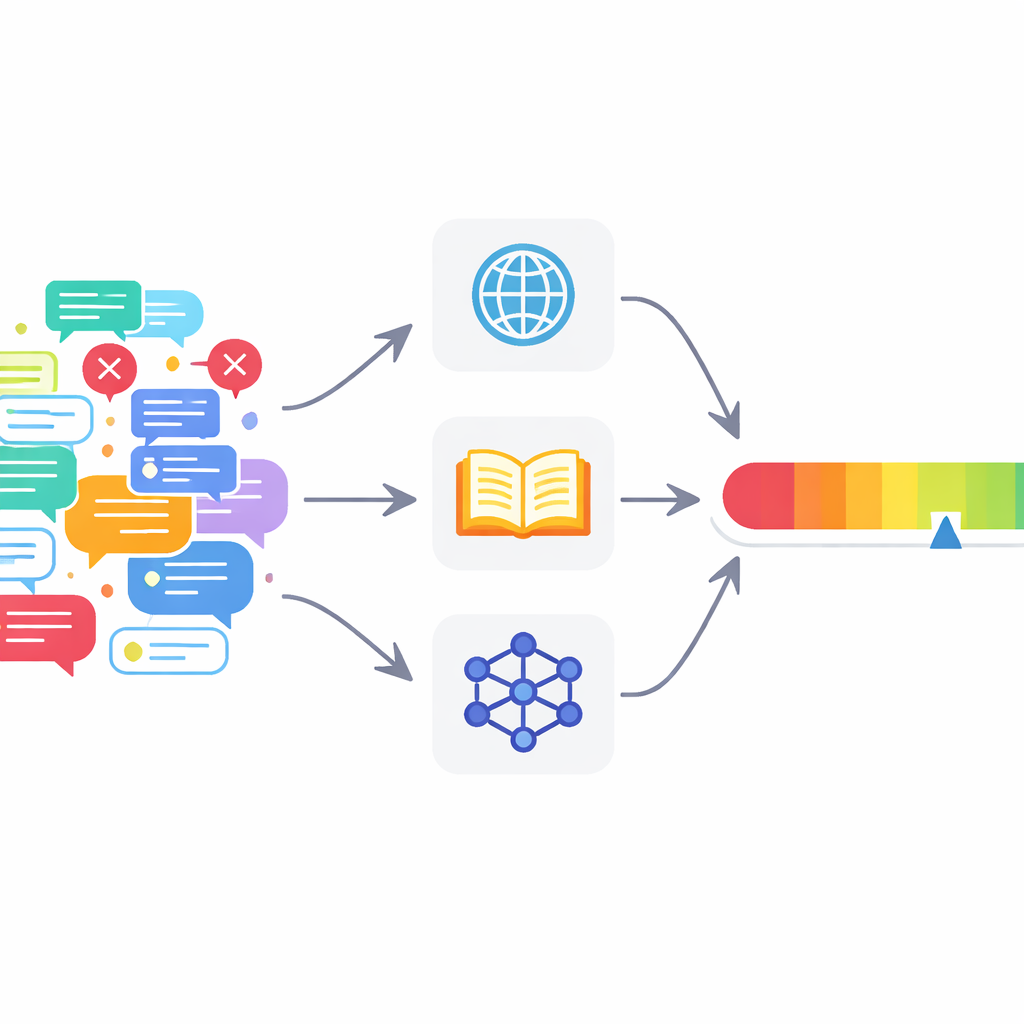
为了解决这些问题,作者提出了一个多代理事实核查框架(MAFC)。系统不再依赖一个全知的核查者,而是部署多个代理,每个代理依赖不同的信息来源。一个代理在网络上搜索,另一个查询维基百科,第三个使用AI模型生成并比较备选答案,这是一种借鉴于幻觉检测研究的技术。需要核查的文本首先被拆分为独立的事实性陈述。每个代理调查每一条陈述,判断其看起来是真还是假,并给出一个介于0到1之间的置信度分数,反映其对自身判断的确信程度。
将分散意见转化为单一分数
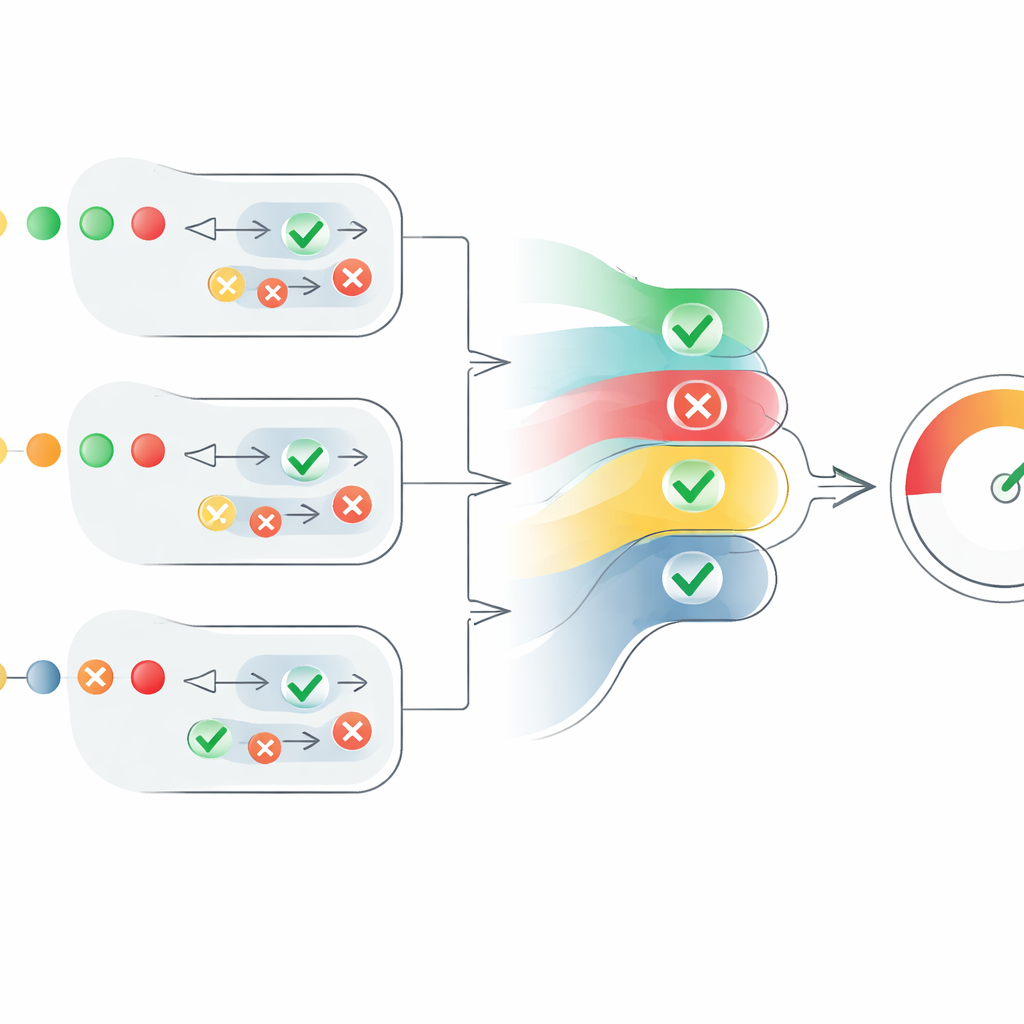
论文的核心是一种新的评分机制,它把这些分散的代理意见转化为明确的可信度度量。对于每一条陈述,系统将“真”判断转为正值、“假”判断转为负值,然后按各代理的置信度进行缩放。它还考虑了有多少代理达成一致,但采取受控处理:更多代理的一致性会有所帮助,然而每增加一个声音所带来的边际作用逐渐减弱。这可以防止大量弱而不确定的代理压倒少数高度自信的代理。得到的结果是每条陈述的分数位于0到1之间。文本中所有陈述的分数随后被平均以产生文本层面的可信度分数,该分数可被解读为“完全真实”、“部分真实”或“虚假”。
对该框架进行测试
研究者在若干已建立的数据集上评估了MAFC,用于短陈述和合成文本的检测。他们使用了SciFact,该数据集包含被研究论文标注为支持或反驳的科学陈述;以及FEVER,这是一个以维基百科为基础构建的大型陈述集合。研究者还构建了一个新数据集SciFact‑Mixed,其中短文本由若干陈述组合而成,这些陈述可能全部正确、全部错误或部分正确部分错误。MAFC的表现与一个强大的单代理基线以及多代理合并的更简单方法(例如简单平均或直接相加分数)进行了比较。
结果显示了什么
在这些实验中,采用新评分规则的多代理系统始终优于其他替代方案。它在判断单条陈述的真伪方面比单一基于AI的核查器更准确,且在识别那些混合了准确与误导性陈述的部分真实文本方面表现尤为突出。在FEVER数据集上,MAFC达到了可与那些专门在该数据上训练的顶级竞赛系统相媲美的准确率,尽管MAFC并未进行此类专门训练。作者指出,他们的框架仍存在局限性,例如所有代理可能依赖相同的底层AI模型,以及处理时效性强的陈述时的困难,但他们认为该方法为更丰富、分层的事实核查提供了一个稳健且透明的基础。
这对日常读者意味着什么
对于试图在嘈杂信息环境中导航的读者而言,这项工作指向了比简单给帖文贴上真或假的工具更有用的方向。通过从多个来源提取证据并以有原则的方式权衡它们的一致性与置信度,MAFC框架能够估计一段文本的整体可信度并突出其何时仅部分可靠。虽然仍处于研究原型阶段,这类系统最终可能帮助读者、版主和讨论平台更好地理解信息在“可靠事实”到“可疑传闻”谱系中的位置。
引用: Dong, Y., Ito, T. Multi-agent systems and credibility-based advanced scoring mechanism in fact-checking. Sci Rep 16, 11814 (2026). https://doi.org/10.1038/s41598-026-41862-z
关键词: 错误信息, 事实核查, 大型语言模型, 多代理系统, 信誉评分