Clear Sky Science · it
Sistemi multi‑agente e meccanismo avanzato di punteggio basato sulla credibilità nel fact‑checking
Perché verificare le affermazioni online è davvero importante
Ogni giorno i social network e i feed di notizie ci sommergono di affermazioni su scienza, politica e salute. Alcune sono accurate, altre fuorvianti e altre ancora mescolano verità e falsità in modi sottili. Questo articolo presenta un nuovo modo di valutare quanto siano affidabili tali testi facendo lavorare insieme diversi “fact‑checker” digitali e combinando poi con cura le loro opinioni in un unico punteggio di credibilità.
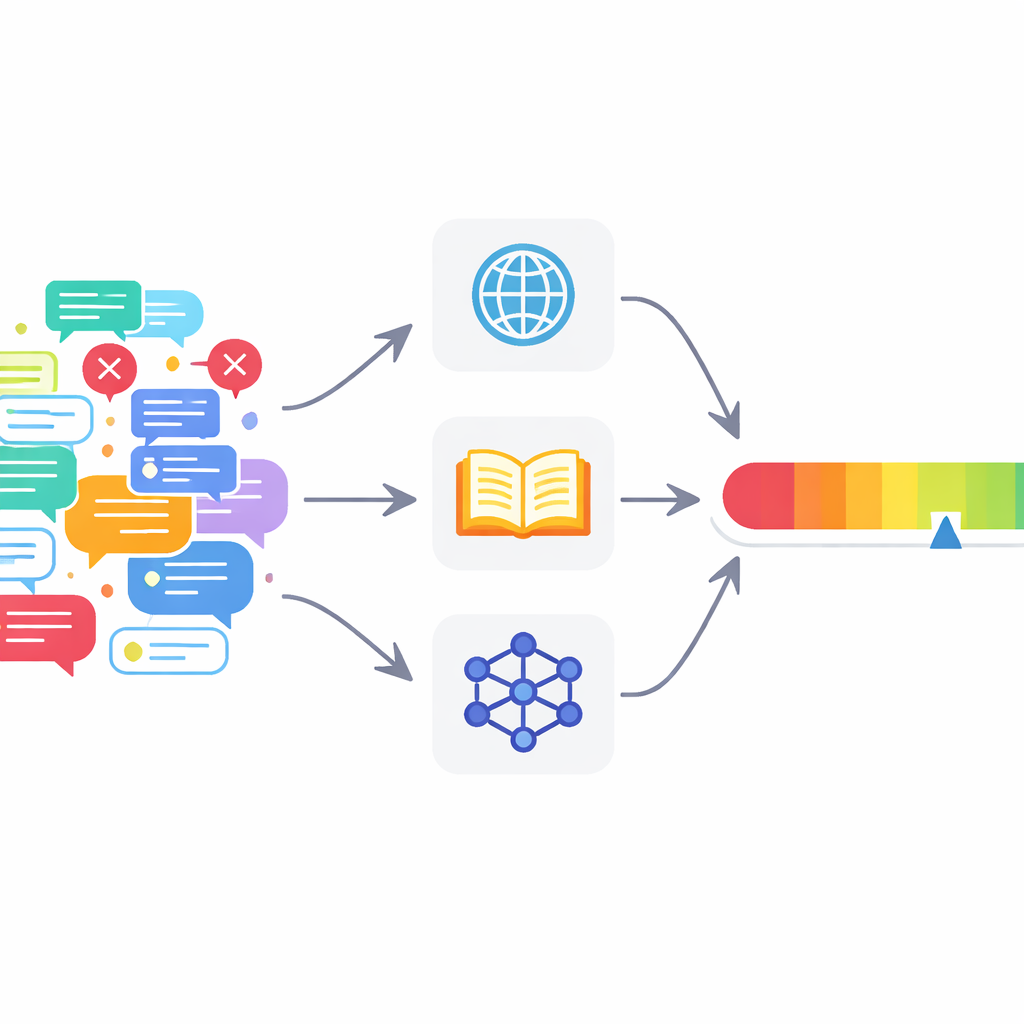
Molti strumenti attuali non bastano
Il fact‑checking automatizzato è cresciuto rapidamente insieme ai modelli linguistici di grandi dimensioni, i sistemi di IA che stanno dietro a strumenti come i chatbot moderni. La maggior parte dei sistemi esistenti si concentra su una decisione semplice sì‑o‑no: un’affermazione è vera o falsa? Spesso si appoggiano a una singola fonte di informazione, o perfino solo alla conoscenza del modello stesso. Questo porta a due problemi nelle discussioni online reali. Primo, i modelli linguistici tendono ad essere eccessivamente sicuri, dando un tono di certezza anche quando sono in errore. Secondo, i post reali spesso mescolano enunciati corretti e scorretti, perciò un’unica etichetta vero/falso per l’intero testo è troppo grossolana per essere utile.
Molti fact‑checker digitali invece di uno
Per affrontare questi problemi, gli autori propongono un framework di fact‑checking multi‑agente (MAFC). Invece di un unico verificatore onnisciente, il sistema distribuisce diversi agenti, ciascuno basato su una fonte d’informazione diversa. Un agente cerca sul web, un altro interroga Wikipedia e un terzo utilizza un modello d’IA per generare e confrontare risposte alternative, una tecnica adattata dalla ricerca sulla rilevazione delle allucinazioni. Il testo da verificare viene prima scomposto in singole affermazioni fattuali. Ogni agente indaga su ciascuna affermazione, decide se sembra vera o falsa e produce un punteggio di confidenza tra 0 e 1 che riflette quanto forte sia la sua convinzione nel proprio giudizio.
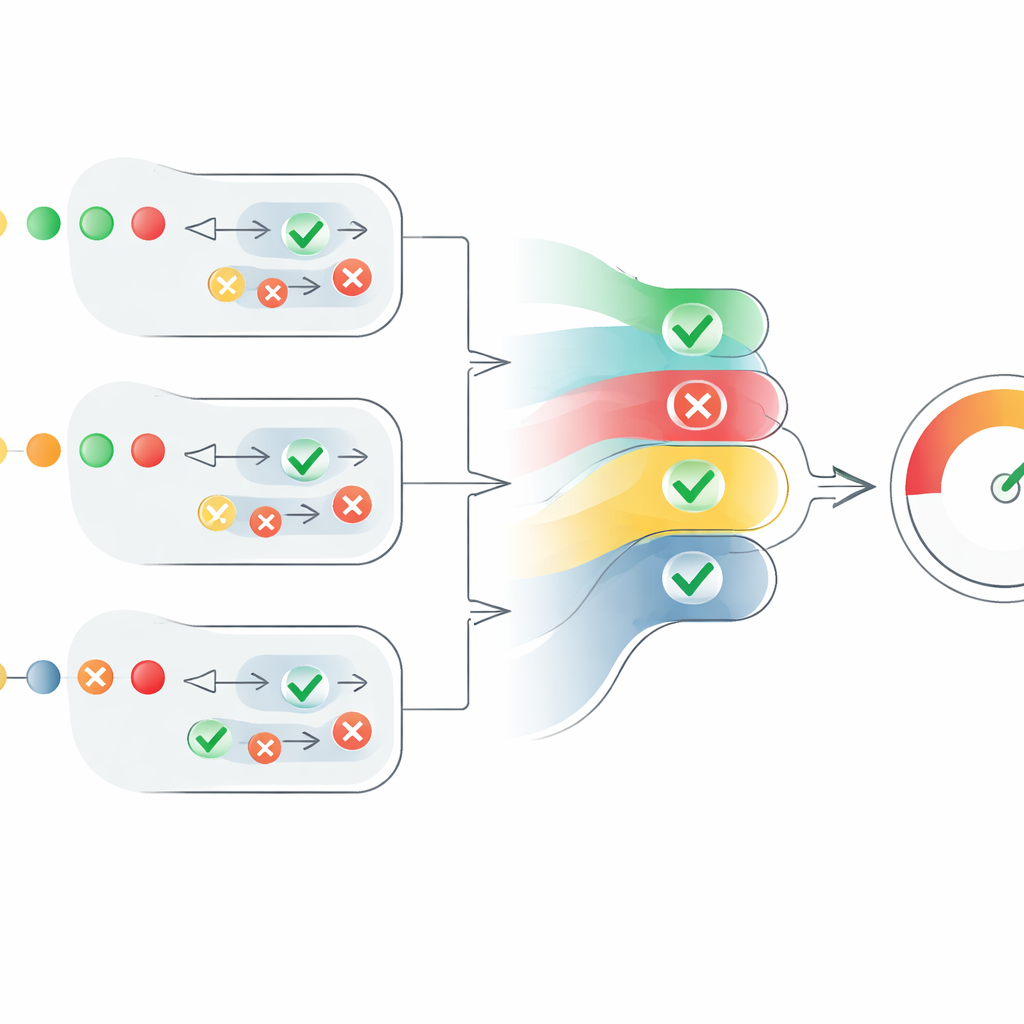
Trasformare opinioni disperse in un unico punteggio
Il cuore dell’articolo è un nuovo meccanismo di punteggio che converte queste opinioni disperse degli agenti in una misura chiara di credibilità. Per ogni affermazione, il sistema trasforma i giudizi “veri” in numeri positivi e quelli “falsi” in numeri negativi, quindi li scala in base alla confidenza di ciascun agente. Tiene anche conto di quante entità concordano, ma in modo controllato: l’accordo di agenti aggiuntivi aiuta, tuttavia ogni voce in più contribuisce un po’ meno della precedente. Questo evita che un grande gruppo di agenti deboli e incerti sovrasti un numero minore di agenti molto fiduciosi. Il risultato è un punteggio a livello di affermazione compreso tra 0 e 1. I punteggi di tutte le affermazioni in un testo vengono poi mediati per produrre un punteggio di credibilità a livello di testo, interpretabile come “completamente vero”, “parzialmente vero” o “falso”.
Mettere alla prova il framework
I ricercatori hanno valutato MAFC su dataset consolidati di affermazioni brevi e testi costruiti ad hoc. Hanno usato SciFact, che contiene enunciati scientifici etichettati come supportati o confutati da articoli di ricerca, e FEVER, una grande raccolta di affermazioni costruite a partire da Wikipedia. Hanno inoltre creato un nuovo dataset, SciFact‑Mixed, in cui testi brevi sono formati combinando più affermazioni che possono essere tutte corrette, tutte scorrette o un misto di entrambe. Le prestazioni di MAFC sono state confrontate con un forte baseline a agente singolo e con modi più semplici di combinare più agenti, come la media semplice o la somma dei loro punteggi.
Cosa mostrano i risultati
Nel corso di questi esperimenti, il sistema multi‑agente con la nuova regola di punteggio ha costantemente superato le alternative. È risultato più accurato del verificatore basato su un singolo modello IA nel decidere se un’affermazione fosse vera o falsa, ed è stato particolarmente efficace nel riconoscere testi parzialmente veri che mescolano enunciati accurati e fuorvianti. Sul dataset FEVER, MAFC ha raggiunto una accuratezza paragonabile ai migliori sistemi di competizione che erano stati appositamente addestrati su quei dati, sebbene MAFC abbia operato senza tale addestramento. Gli autori osservano che il loro framework ha ancora limiti, come l’affidarsi allo stesso modello IA sottostante per tutti gli agenti e le difficoltà con affermazioni sensibili al fattore tempo, ma ritengono che offra una base solida e trasparente per un fact‑checking più ricco e multilivello.
Cosa significa per i lettori di tutti i giorni
Per chi cerca di orientarsi in un panorama informativo rumoroso, questo lavoro indica strumenti che fanno più che bollare i post come semplicemente veri o falsi. Attraendo evidenze da più fonti e ponderando il loro accordo e la loro confidenza in modo principato, il framework MAFC può stimare quanto sia affidabile un testo nel suo complesso e mettere in evidenza quando è solo parzialmente attendibile. Pur essendo ancora un prototipo di ricerca, questo tipo di sistema potrebbe alla fine aiutare lettori, moderatori e piattaforme di discussione a comprendere meglio dove si colloca un’informazione nello spettro che va da fatto consolidato a pettegolezzo dubbio.
Citazione: Dong, Y., Ito, T. Multi-agent systems and credibility-based advanced scoring mechanism in fact-checking. Sci Rep 16, 11814 (2026). https://doi.org/10.1038/s41598-026-41862-z
Parole chiave: disinformazione, fact‑checking, modelli linguistici di grandi dimensioni, sistemi multi‑agente, valutazione della credibilità