Clear Sky Science · en
Multi-agent systems and credibility-based advanced scoring mechanism in fact-checking
Why checking online claims really matters
Every day, social networks and news feeds bombard us with claims about science, politics, and health. Some are accurate, some are misleading, and some mix truth with falsehood in subtle ways. This paper introduces a new way to evaluate how trustworthy such texts are by having several digital “fact‑checkers” work together and then carefully combining their opinions into a single credibility score.
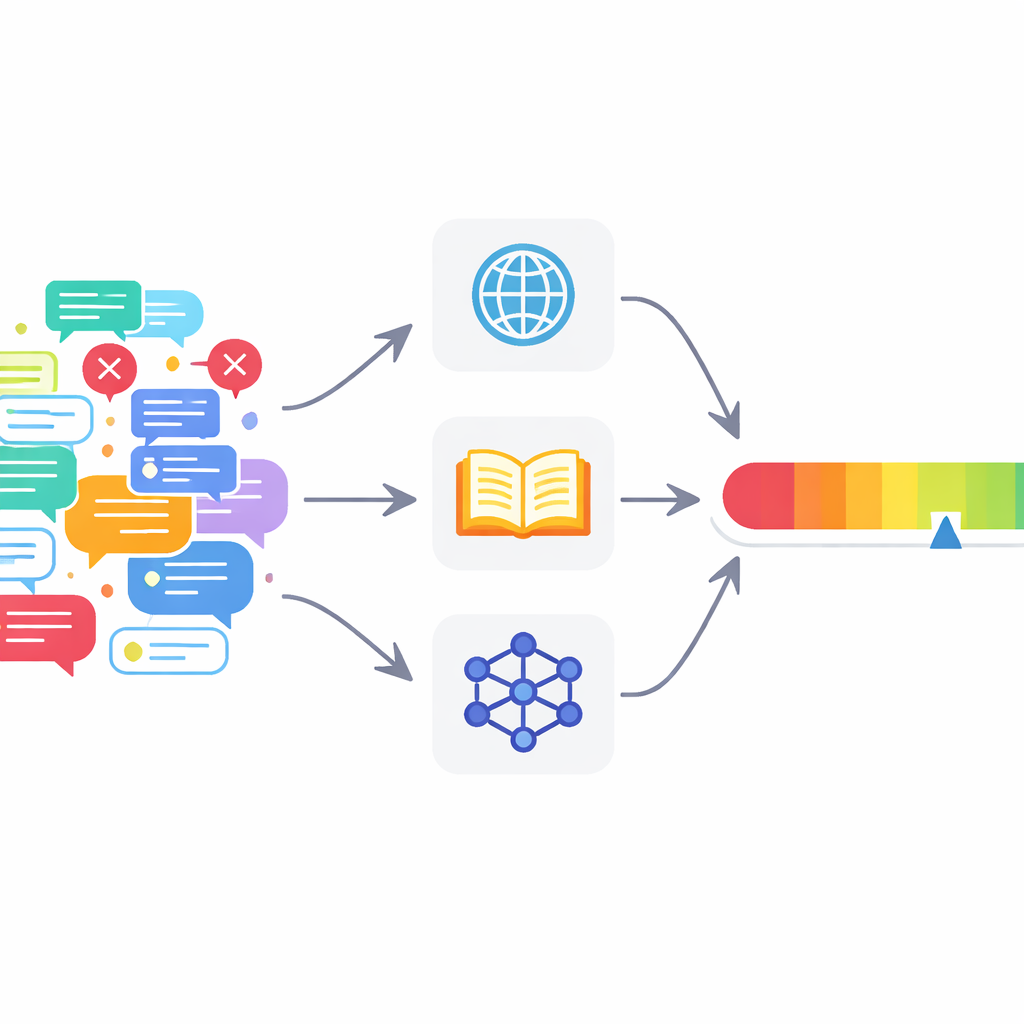
Many current tools fall short
Automated fact‑checking has grown rapidly alongside large language models, the AI systems behind tools like modern chatbots. Most existing systems focus on a simple yes‑or‑no decision: is a claim true or false? They often rely on a single information source, or even just on the language model’s own knowledge. This leads to two problems in real online discussions. First, language models tend to be overconfident, sounding sure even when they are wrong. Second, real posts frequently blend correct and incorrect statements, so a single true/false label for the whole text is too crude to be useful.
Many digital fact‑checkers instead of one
To tackle these issues, the authors propose a multi‑agent fact‑checking framework (MAFC). Instead of one all‑knowing checker, the system deploys several agents, each drawing on a different information source. One agent searches the web, another queries Wikipedia, and a third uses an AI model to generate and compare alternative answers, a technique adapted from hallucination‑detection research. The text to be checked is first broken into individual factual claims. Each agent investigates each claim, decides whether it appears true or false, and produces a confidence score between 0 and 1 that reflects how strongly it believes its own judgment.
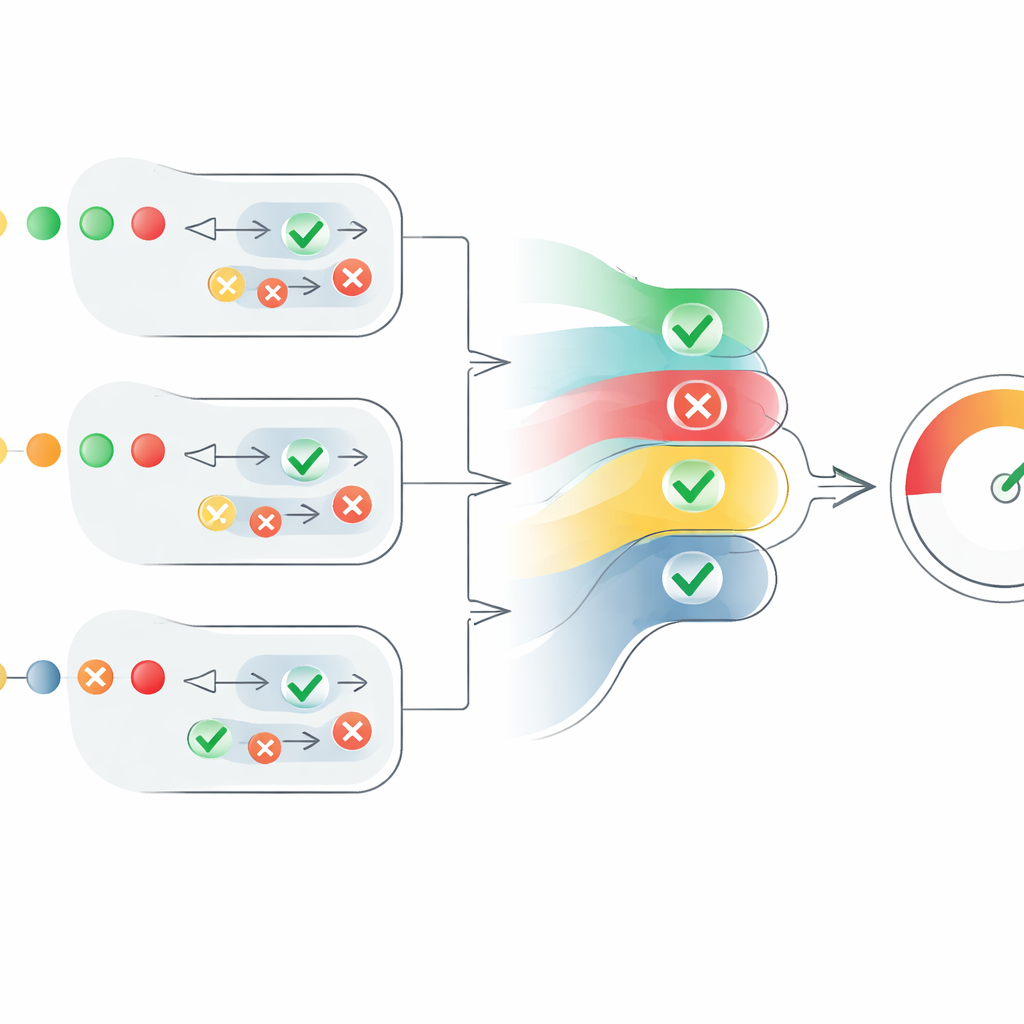
Turning scattered opinions into a single score
The heart of the paper is a new scoring mechanism that turns these scattered agent opinions into a clear measure of credibility. For each claim, the system converts “true” judgments into positive numbers and “false” judgments into negative ones, then scales them by each agent’s confidence. It also takes into account how many agents agree, but in a controlled way: agreement from additional agents helps, yet each extra voice adds a little less than the one before. This prevents a large group of weak, uncertain agents from overpowering a smaller number of highly confident ones. The result is a claim‑level score between 0 and 1. The scores for all claims in a text are then averaged to produce a text‑level credibility score, which can be interpreted as “fully true,” “partly true,” or “false.”
Putting the framework to the test
The researchers evaluated MAFC on established datasets of short claims and constructed texts. They used SciFact, which contains scientific statements labeled as supported or refuted by research papers, and FEVER, a large collection of claims built from Wikipedia. They also built a new dataset, SciFact‑Mixed, where short texts are formed by combining several claims that may be all correct, all incorrect, or a mix of both. MAFC’s performance was compared against a strong single‑agent baseline and against simpler ways of combining multiple agents, such as simple averaging or summing their scores.
What the results show
Across these experiments, the multi‑agent system with the new scoring rule consistently outperformed the alternatives. It was more accurate than the single AI‑based checker at deciding whether a claim was true or false, and it was especially strong at recognizing partially true texts that mix accurate and misleading statements. On the FEVER dataset, MAFC achieved accuracy comparable to top competition systems that had been specially trained on that data, even though MAFC operated without such training. The authors note that their framework still has limitations, such as relying on the same underlying AI model for all agents and struggling with time‑sensitive claims, but they argue it offers a solid and transparent foundation for richer, multi‑level fact‑checking.
What this means for everyday readers
For someone trying to navigate a noisy information landscape, this work points toward tools that do more than stamp posts as simply true or false. By drawing evidence from several sources and weighing their agreement and confidence in a principled way, the MAFC framework can estimate how trustworthy a piece of text is overall and highlight when it is only partly reliable. While still a research prototype, this kind of system could eventually help readers, moderators, and discussion platforms better understand where information stands on the spectrum from solid fact to dubious rumor.
Citation: Dong, Y., Ito, T. Multi-agent systems and credibility-based advanced scoring mechanism in fact-checking. Sci Rep 16, 11814 (2026). https://doi.org/10.1038/s41598-026-41862-z
Keywords: misinformation, fact-checking, large language models, multi-agent systems, credibility scoring