Clear Sky Science · tr
Çok ajanlı sistemler ve doğruluk temelli gelişmiş puanlama mekanizmasıyla bilgi doğrulama
Çevrimiçi iddiaları doğrulamak neden gerçekten önemli
Her gün sosyal ağlar ve haber akışları bize bilim, siyaset ve sağlık hakkında pek çok iddia sunuyor. Bazıları doğru, bazıları yanıltıcı ve bazıları gerçeği yanlışla ince bir şekilde karıştırıyor. Bu makale, bu tür metinlerin ne kadar güvenilir olduğunu değerlendirmek için birkaç dijital “doğrulayıcı”nın birlikte çalışmasını ve ardından görüşlerini dikkatle tek bir güvenilirlik puanına dönüştürmeyi öneren yeni bir yöntem sunuyor.
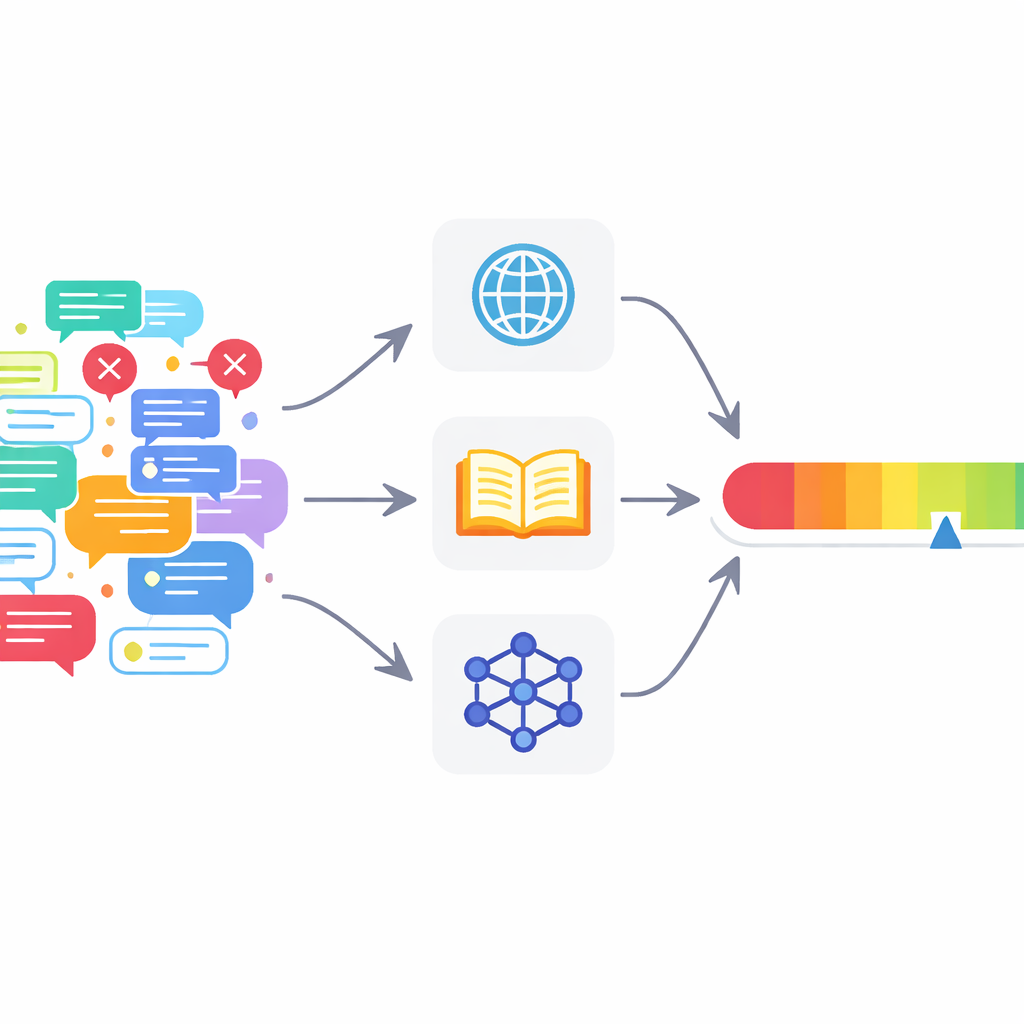
Mevcut birçok araç yetersiz kalıyor
Otomatik bilgi doğrulama, modern sohbet botlarının arkasındaki yapay zeka sistemleri olan büyük dil modelleriyle birlikte hızla gelişti. Mevcut sistemlerin çoğu basit bir evet‑hayır kararına odaklanıyor: bir iddia doğru mu yoksa yanlış mı? Çoğunlukla tek bir bilgi kaynağına ya da hatta yalnızca dil modelinin kendi bilgisine dayanıyorlar. Bu durum gerçek çevrimiçi tartışmalarda iki soruna yol açıyor. Birincisi, dil modelleri hatalı olduklarında bile kendinden emin görünme eğiliminde; aşırı güven sergileyebiliyorlar. İkincisi, gerçek gönderiler sık sık doğru ve yanlış ifadeleri harmanladığı için tüm metin için tek bir doğru/yanlış etiketi fazla kaba kalıyor.
Bir tane yerine birçok dijital doğrulayıcı
Bu sorunları ele almak için yazarlar çok ajanlı bir doğrulama çerçevesi (MAFC) öneriyor. Her şeyi bilen tek bir doğrulayıcı yerine sistem, her biri farklı bir bilgi kaynağına dayanan birkaç ajan konuşlandırıyor. Bir ajan webi tarıyor, başka bir ajan Vikipedi’ye sorgu gönderiyor ve üçüncü bir ajan, halüsinasyon tespiti araştırmasından uyarlanan bir teknikle alternatif cevaplar üreten ve karşılaştıran bir yapay zeka modeli kullanıyor. Doğrulanacak metin önce bireysel maddi iddialara ayrılıyor. Her ajan her iddiayı inceliyor, iddianın doğru veya yanlış görünüp görünmediğine karar veriyor ve kendi yargısına ne kadar güvendiğini 0 ile 1 arasında bir güven puanı olarak üretiyor.
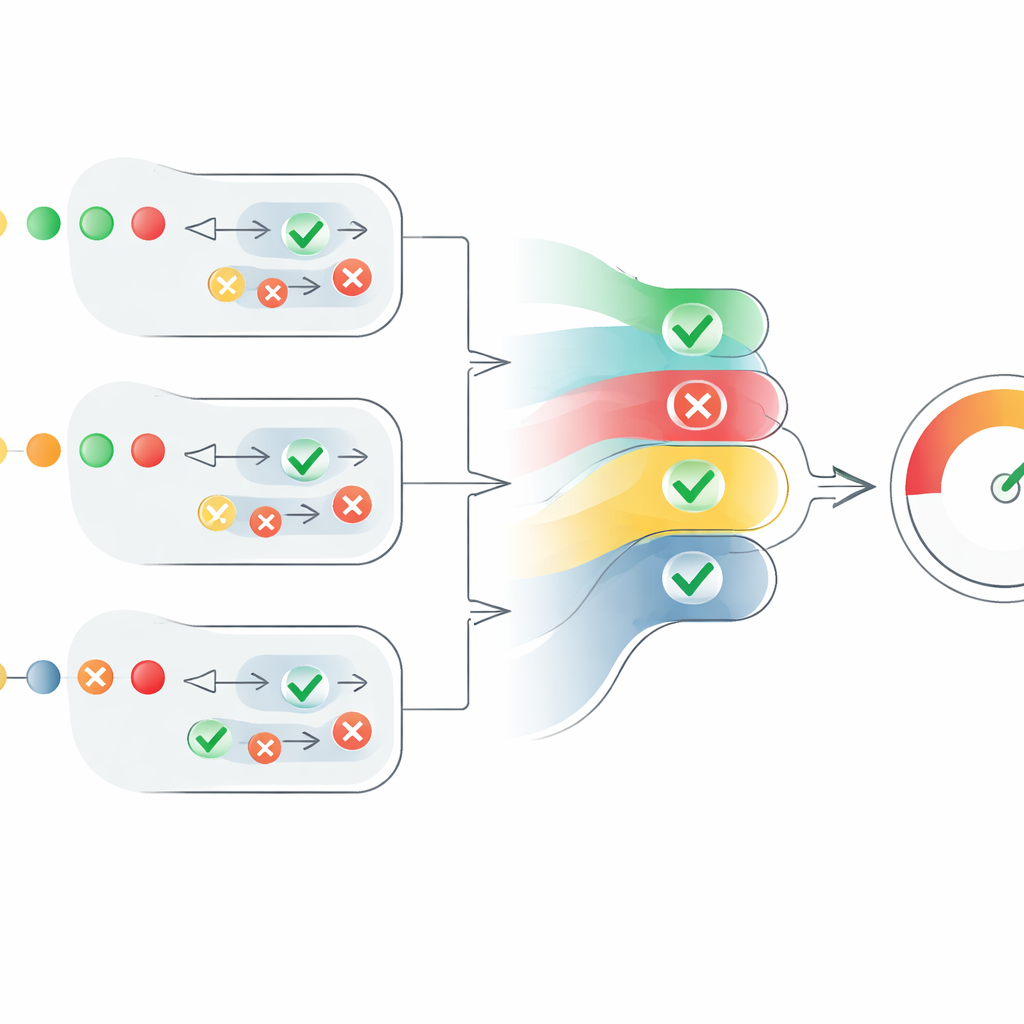
Dağınık görüşleri tek bir puana dönüştürmek
Makaleye damgasını vuran kısım, bu dağınık ajan görüşlerini net bir güvenilirlik ölçüsüne dönüştüren yeni puanlama mekanizması. Her iddia için sistem “doğru” yargılarını pozitif sayılara, “yanlış” yargılarını negatife çeviriyor ve ardından bunları her ajanın güveniyle ölçeklendiriyor. Ayrıca kaç ajanın aynı fikirde olduğuna da kontrollü şekilde bakıyor: ek ajanların mutabakatı yardımcı oluyor, ancak her yeni ses bir öncekinden biraz daha az katkı sağlıyor. Bu, zayıf ve belirsiz büyük bir grubun, daha az ama yüksek güvenli ajanların etkisini bastırmasını engelliyor. Sonuç, 0 ile 1 arasında bir iddia düzeyi puanı. Bir metindeki tüm iddiaların puanları ortalanarak metin düzeyinde bir güvenilirlik puanı elde ediliyor; bu puan “tamamen doğru”, “kısmen doğru” veya “yanlış” olarak yorumlanabiliyor.
Çerçeveyi teste sokmak
Araştırmacılar MAFC’yi kısa iddialardan ve oluşturulmuş metinlerden oluşan yerleşik veri kümeleri üzerinde değerlendirdi. Bilimsel ifadeleri araştırma makaleleri tarafından desteklenmiş veya çürütülmüş olarak etiketleyen SciFact ve Vikipedi’den oluşturulmuş geniş bir iddia koleksiyonu olan FEVER’ı kullandılar. Ayrıca kısa metinlerin tümü doğru, tümü yanlış veya karışık olabilecek birkaç iddiadan oluşturulduğu yeni bir veri kümesi, SciFact‑Mixed, geliştirdiler. MAFC’nin performansı güçlü bir tek‑ajan karşıtıyla ve çoklu ajanları birleştirmenin basit yöntemleriyle (örneğin basit ortalama veya puanların toplanması) karşılaştırıldı.
Sonuçlar ne gösteriyor
Bu deneylerin tümünde yeni puanlama kuralına sahip çok ajanlı sistem alternatiflerden tutarlı şekilde daha iyi performans gösterdi. Bir iddianın doğru veya yanlış olduğunu belirlemede tek bir yapay zeka tabanlı doğrulayıcıdan daha isabetliydi ve doğru ile yanıltıcı ifadeleri karıştıran kısmen doğru metinleri tanımada özellikle güçlüydü. FEVER veri kümesinde MAFC, o veriye özel olarak eğitilmiş en iyi yarışma sistemleriyle karşılaştırılabilir doğruluk elde etti; üstelik MAFC böyle bir eğitim olmadan çalışıyordu. Yazarlar, çerçevelerinin hâlâ tüm ajanlar için aynı temel yapay zeka modeline dayanması ve zaman duyarlı iddialarda zorluk yaşaması gibi sınırlamaları olduğunu belirtiyor, ancak bunun daha zengin, çok düzeyli bilgi doğrulama için sağlam ve şeffaf bir temel sunduğunu savunuyorlar.
Günlük okurlar için ne anlama geliyor
Gürültülü bir bilgi ortamında yol almaya çalışan biri için bu çalışma, gönderilere sadece doğru veya yanlış damgası vurmanın ötesine geçen araçlara işaret ediyor. Birden fazla kaynaktan kanıt çekerek ve bunların mutabakatını ve güvenini ilkesel bir şekilde tartarak MAFC çerçevesi, bir metnin genel olarak ne kadar güvenilir olduğunu tahmin edebilir ve yalnızca kısmen güvenilir olduğunda bunu vurgulayabilir. Henüz bir araştırma prototipi olsa da bu tür bir sistem, ileride okuyuculara, içerik denetleyicilere ve tartışma platformlarına bilginin sağlam gerçeklerden kuşkulu söylentilere uzanan spektrumda nerede durduğunu daha iyi anlamada yardımcı olabilir.
Atıf: Dong, Y., Ito, T. Multi-agent systems and credibility-based advanced scoring mechanism in fact-checking. Sci Rep 16, 11814 (2026). https://doi.org/10.1038/s41598-026-41862-z
Anahtar kelimeler: yanlış bilgi, bilgi doğrulama, büyük dil modelleri, çok ajanlı sistemler, güvenilirlik puanlaması