Clear Sky Science · he
מערכות מרובות‑סוכנים ומנגנון ניקוד מתקדם מבוסס אמינות בבדיקת עובדות
מדוע חשוב לבדוק טענות מקוונות
כל יום רשתות חברתיות ופידים חדשותיים מציפים אותנו בטענות על מדע, פוליטיקה ובריאות. חלקן מדויקות, חלקן מטעות, וחלקן מערבבות אמת ושקר בצורה עדינה. מאמר זה מציג גישה חדשה להערכת מידת האמינות של טקסטים כאלה על‑ידי הפעלת מספר "בודקי‑עובדות" דיגיטליים שעובדים יחד ולאחר מכן שילוב זהיר של דעותיהם לציון אמינות יחיד.
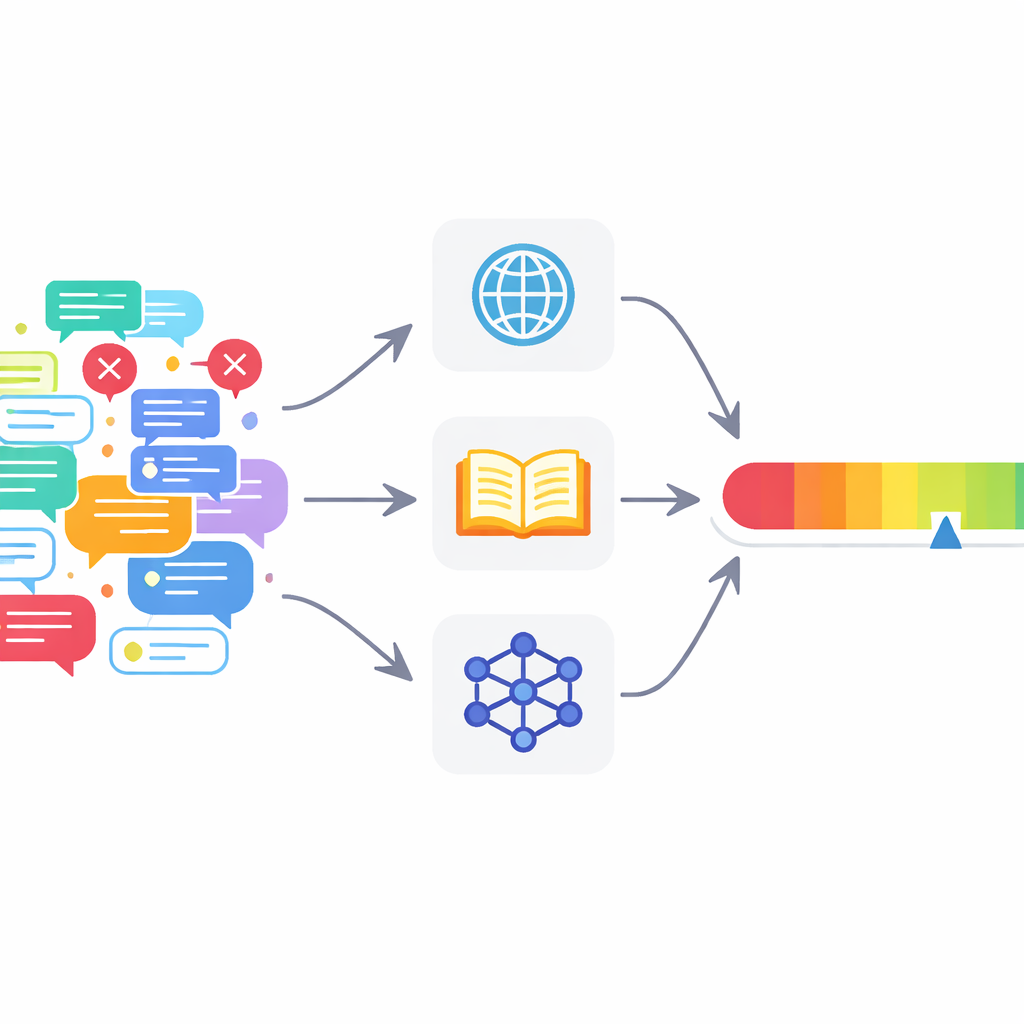
כלים רבים כיום נכשלים
בדיקת עובדות אוטומטית צמחה במהירות לצד המודלים הלשוניים הגדולים — מערכות ה‑AI שעומדות מאחורי כלים כמו צ׳אטבוטים מודרניים. רוב המערכות הקיימות מתמקדות בהחלטה בינארית פשוטה: האם טענה נכונה או שגויה? הן לעתים נשענות על מקור מידע יחיד, או אפילו רק על הידע הפנימי של המודל הלשוני. זה יוצר שתי בעיות בשיחות מקוונות אמיתיות. ראשית, למודלים לשוניים יש נטייה להיות בטוחים מדי, להישמע החלטיים גם כשהם טועים. שנית, פוסטים אמיתיים לעתים קרובות משלבים הצהרות נכונות ושגויות, כך שתווית נכונה/שגויה אחת לכל הטקסט גסה מדי כדי להיות שימושית.
כמה בודקים דיגיטליים במקום אחד
כדי להתמודד עם הבעיות הללו, המחברים מציעים מסגרת בדיקת‑עובדות מרובת‑סוכנים (MAFC). במקום בורר יחיד שכל יודע, המערכת מפעילה מספר סוכנים, שכל אחד מהם שואב ממקור מידע שונה. סוכן אחד מחפש באינטרנט, אחר שואל את ויקיפדיה, ושלישי משתמש במודל AI כדי לייצר ולהשוות תשובות חלופיות — טכניקה שאומצה ממחקר לזיהוי הזיות. הטקסט הנבדק מפורק תחילה לטענות עובדתיות בודדות. כל סוכן חוקר כל טענה, מחליט אם היא נראית נכונה או שגויה, ומייצר ציון ביטחון בין 0 ל‑1 שמשקף עד כמה הוא מאמין בשיפוטו.
הפיכת דעות מפוזרות לציון יחיד
ליבה של המאמר הוא מנגנון ניקוד חדש הממזג את דעות הסוכנים המפוזרות למדד אמינות ברור. עבור כל טענה, המערכת ממירה שיפוטים של "נכון" למספרים חיוביים ושיפוטים של "שגוי" למספרים שליליים, ולאחר מכן מאזנת אותם לפי רמת הביטחון של כל סוכן. היא גם לוקחת בחשבון כמה סוכנים מסכימים, אך בצורה מבוקרת: הסכמה של סוכנים נוספים מסייעת, אך כל קול נוסף מוסיף מעט פחות מקודמו. זה מונע מקבוצה גדולה של סוכנים חלשים ולא בטוחים להכריע קבוצה קטנה של סוכנים חסרי־פשרה ובטוחים מאוד. התוצאה היא ציון ברמת‑הטענה בטווח 0 עד 1. הציונים של כל הטענות בטקסט ממוצעים לאחר מכן כדי לייצר ציון אמינות ברמת‑הטקסט, שניתן לפרש כ"נכון לחלוטין", "נכון בחלקו" או "שגוי".
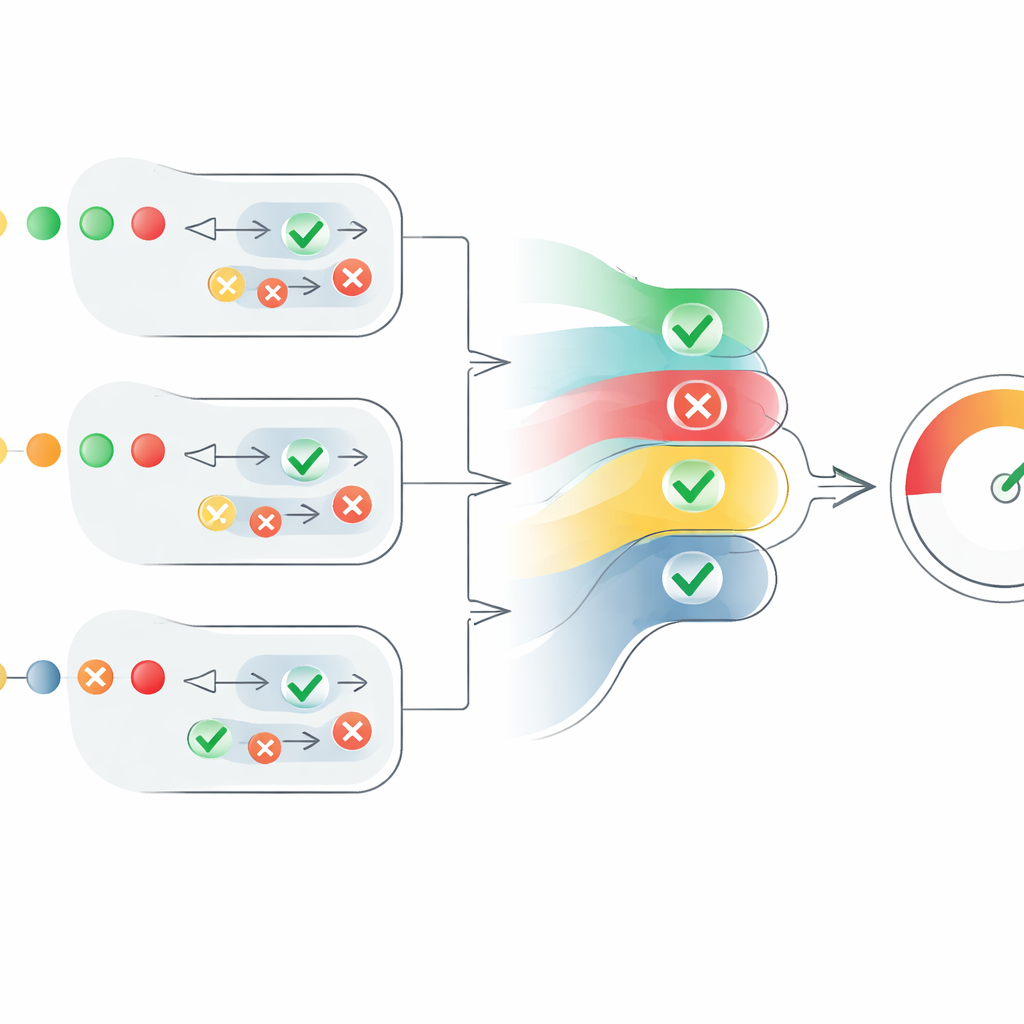
בדיקת המסגרת בפועל
החוקרים העריכו את MAFC על מערכי נתונים מבוססים של טענות קצרות וטקסטים מורכבים. הם השתמשו ב‑SciFact, שמכיל הצהרות מדעיות שסומנו כנתמכות או מופרכות על‑ידי מאמרי מחקר, וב‑FEVER, אוסף גדול של טענות שנבנו מוויקיפדיה. הם גם בנו מאגר חדש, SciFact‑Mixed, שבו טקסטים קצרים נוצרו על‑ידי שילוב מספר טענות שיכולות להיות כולן נכונות, כולן שגויות, או תערובת של שתיהן. ביצועי MAFC הושוו לבסיס חזק של סוכן יחיד ולהשוואות פשוטות יותר של שילוב סוכנים, כגון ממוצע פשוט או סכימת ציונים.
מה מראים התוצאות
באמצעות ניסויים אלה, המערכת המרובת‑הסוכנים עם כלל הניקוד החדש עקפה בעקביות את האלטרנטיבות. היא הייתה מדויקת יותר מהבודק הבודד המבוסס AI בקביעת נכונות או שגיאות של טענה, והצטיינה במיוחד בזיהוי טקסטים נכונים בחלקם שמערבבים הצהרות מדויקות ומטעות. במערך הנתונים FEVER, MAFC השיגה דיוק השווה למערכות מתחרות מובילות שאומנו במיוחד על אותו נתון, אף ש‑MAFC פעלה ללא אימון כזה. המחברים מציינים שמסגרתם עדיין נתונה למגבלות, כמו התבססות על אותו מודל AI בסיסי לכל הסוכנים והקשיים עם טענות תלויות‑זמן, אך הם טוענים כי היא מציעה יסוד שקוף וחזק לבדיקה עשירה ורב‑רמתית של עובדות.
מה זה אומר עבור הקוראים היומיומיים
למי שמנסה לנווט בנוף מידע רועש, עבודה זו מצביעה לכיוונים של כלים שעושים יותר מלתייג פוסטים כ"נכונים" או "שגויים" בלבד. על‑ידי משיכת ראיות ממספר מקורות ושיקלול הסכמתם וביטחונם באופן עקרוני, מסגרת MAFC יכולה להעריך עד כמה טקסט מהימן ככלל ולהדגיש מתי הוא מהימן רק באופן חלקי. למרות שמדובר עדיין בפרוטוטיפ מחקרי, סוג מערכת זה עשוי בעתיד לעזור לקוראים, למודרטורים ולפלטפורמות דיון להבין טוב יותר היכן עומדת המידע בספקטרום מאמת מוצק ועד שמועה מפוקפקת.
ציטוט: Dong, Y., Ito, T. Multi-agent systems and credibility-based advanced scoring mechanism in fact-checking. Sci Rep 16, 11814 (2026). https://doi.org/10.1038/s41598-026-41862-z
מילות מפתח: מידע מוטעה, בדיקת עובדות, מודלים לשוניים גדולים, מערכות מרובות‑סוכנים, דירוג אמינות