Clear Sky Science · ru
Мультиагентные системы и основанный на достоверности продвинутый механизм оценивания в проверке фактов
Почему проверка онлайн‑утверждений действительно важна
Каждый день социальные сети и новостные ленты засыпают нас заявлениями о науке, политике и здоровье. Некоторые из них точны, некоторые вводят в заблуждение, а некоторые тонко смешивают правду с вымыслом. В этой статье предлагается новый способ оценить доверие к таким текстам: несколько цифровых «факт‑чекеров» работают совместно, а затем их мнения аккуратно объединяются в единый показатель достоверности.
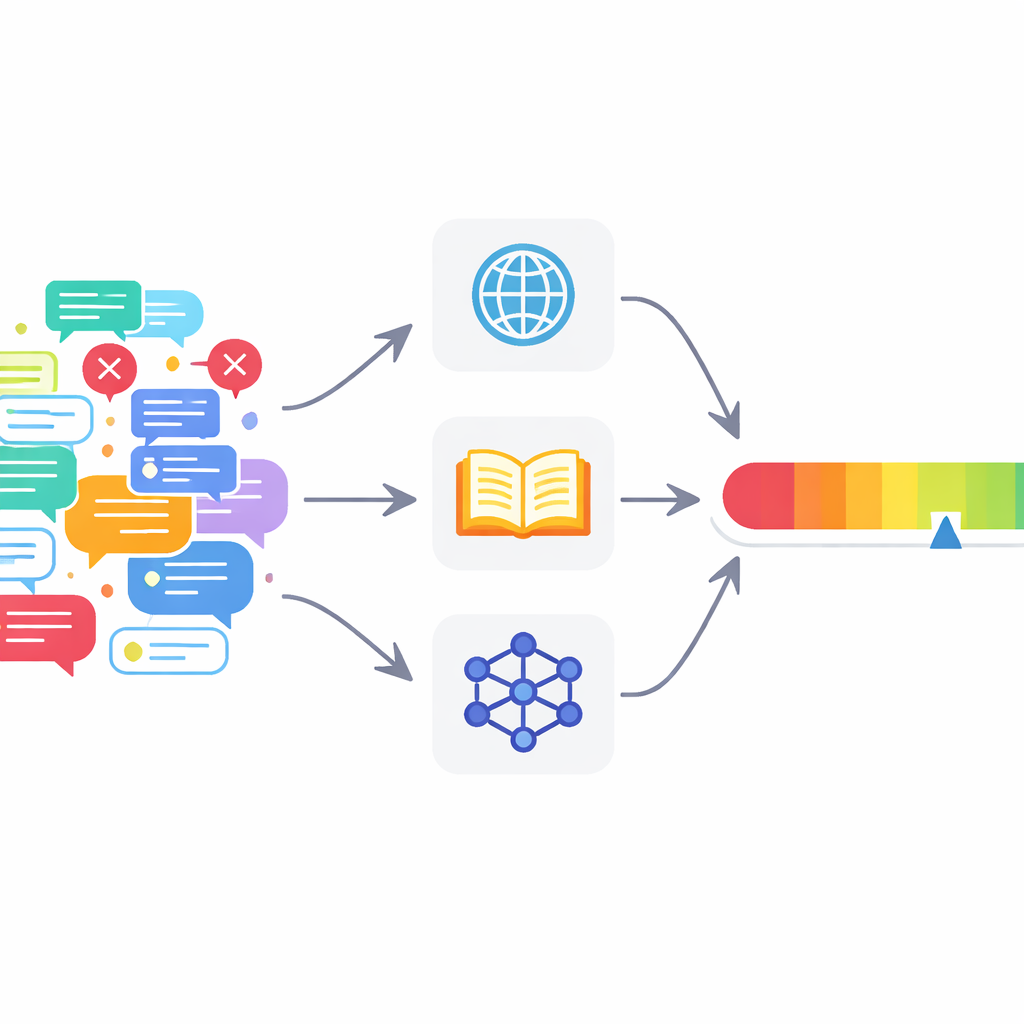
Многие современные инструменты оказываются недостаточными
Автоматическая проверка фактов быстро развивалась вместе с моделями большого языка — системами ИИ, стоящими за современными чат‑ботами. Большинство существующих систем ориентируются на простое решение «да‑или‑нет»: правда ли утверждение или нет? Они часто полагаются на единый источник информации или даже только на знания самой языковой модели. Это порождает две проблемы в реальных онлайн‑обсуждениях. Во‑первых, языковые модели склонны к избыточной уверенности, звуча уверенно даже когда ошибаются. Во‑вторых, реальные посты часто смешивают корректные и некорректные утверждения, поэтому единая метка «правда/ложь» для всего текста оказывается слишком грубой, чтобы быть полезной.
Не один факт‑чекер, а многие
Чтобы справиться с этими проблемами, авторы предлагают мультиагентную архитектуру проверки фактов (MAFC). Вместо единого всеведущего проверяющего система развертывает несколько агентов, каждый из которых опирается на разный источник информации. Один агент ищет в сети, другой запрашивает данные из Википедии, а третий использует модель ИИ для генерации и сравнения альтернативных ответов — прием, позаимствованный из исследований по обнаружению галлюцинаций. Текст, подлежащий проверке, сначала разбивают на отдельные фактические утверждения. Каждый агент исследует каждое утверждение, решает, кажется ли оно истинным или ложным, и выдает показатель уверенности от 0 до 1, отражающий силу его убеждения.
Превращение разрозненных мнений в единый показатель
Сердце статьи — новый механизм оценивания, который преобразует разрозненные мнения агентов в ясную меру достоверности. Для каждого утверждения система переводит суждения «истинно» в положительные числа, а «ложно» — в отрицательные, затем масштабирует их в соответствии с уверенностью каждого агента. Учитывается также число согласных агентов, но контролируемым образом: согласие дополнительного агента помогает, однако каждый следующий голос добавляет немного меньше, чем предыдущий. Это предотвращает ситуацию, когда большая группа слабых, неуверенных агентов перекрывает меньшинство высоко уверенных. В результате получается оценка уровня утверждения в диапазоне от 0 до 1. Оценки всех утверждений в тексте затем усредняются, чтобы получить оценку достоверности всего текста, которую можно интерпретировать как «полностью верно», «частично верно» или «ложно».
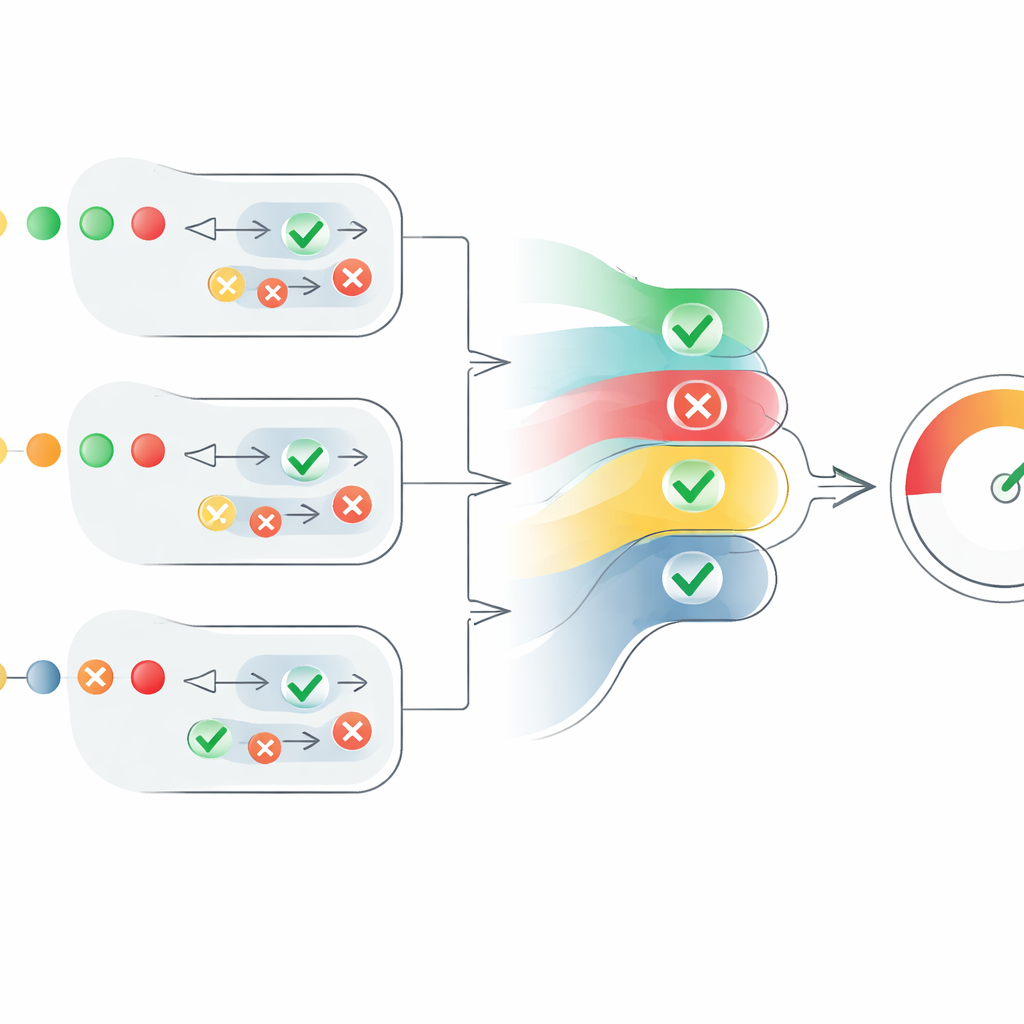
Проверка рамки на практике
Исследователи протестировали MAFC на общепринятых наборах данных с короткими утверждениями и составными текстами. Они использовали SciFact, содержащий научные высказывания, помеченные как подтвержденные или опровергнутые исследованиями, и FEVER — большой корпус утверждений, сформированных из материалов Википедии. Также был создан новый набор данных SciFact‑Mixed, где короткие тексты формируются путем объединения нескольких утверждений, которые могут быть все верными, все неверными или представлять смесь. Производительность MAFC сравнивали с сильной одноагентной базовой системой и с более простыми способами объединения нескольких агентов, такими как простое усреднение или суммирование их оценок.
Что показывают результаты
Во всех этих экспериментах мультиагентная система с новым правилом оценивания стабильно превосходила альтернативы. Она была точнее одноагентного ИИ‑проверяющего в решении, истинно ли утверждение, и особенно хорошо справлялась с распознаванием частично верных текстов, сочетающих точные и вводящие в заблуждение утверждения. На наборе FEVER MAFC показала точность, сопоставимую с лучшими специализированными системами, обученными на этих данных, несмотря на то что MAFC работала без такой дообученной привязки. Авторы отмечают, что их рамка по‑прежнему имеет ограничения — например, использование одной и той же базовой модели ИИ для всех агентов и сложности с утверждениями, чувствительными ко времени — но считают, что она предлагает солидную и прозрачную основу для более глубокой многоуровневой проверки фактов.
Что это означает для повседневных читателей
Для тех, кто пытается ориентироваться в шумном информационном поле, эта работа указывает на инструменты, которые делают больше, чем просто ставят ярлык «верно» или «неверно». Собирая доказательства из нескольких источников и взвешивая их согласие и уверенность принципиальным способом, рамка MAFC может оценить, насколько надежен текст в целом, и выделить случаи, когда он лишь частично заслуживает доверия. Хотя это пока исследовательский прототип, такие системы в будущем могут помочь читателям, модераторам и платформам обсуждений лучше понять, где информация находится на шкале от убедительного факта до сомнительного слуха.
Цитирование: Dong, Y., Ito, T. Multi-agent systems and credibility-based advanced scoring mechanism in fact-checking. Sci Rep 16, 11814 (2026). https://doi.org/10.1038/s41598-026-41862-z
Ключевые слова: дезинформация, проверка фактов, модели большого языка, мультиагентные системы, оценка достоверности