Clear Sky Science · fr
Systèmes multi‑agents et mécanisme avancé de notation basé sur la crédibilité pour la vérification des faits
Pourquoi il est vraiment important de vérifier les affirmations en ligne
Chaque jour, les réseaux sociaux et les flux d’actualité nous inondent d’allégations sur la science, la politique et la santé. Certaines sont exactes, d’autres trompeuses, et d’autres encore mêlent vérité et erreur de façon subtile. Cet article présente une nouvelle méthode pour évaluer la fiabilité de tels textes en faisant coopérer plusieurs « vérificateurs » numériques puis en combinant soigneusement leurs avis en un score de crédibilité unique.
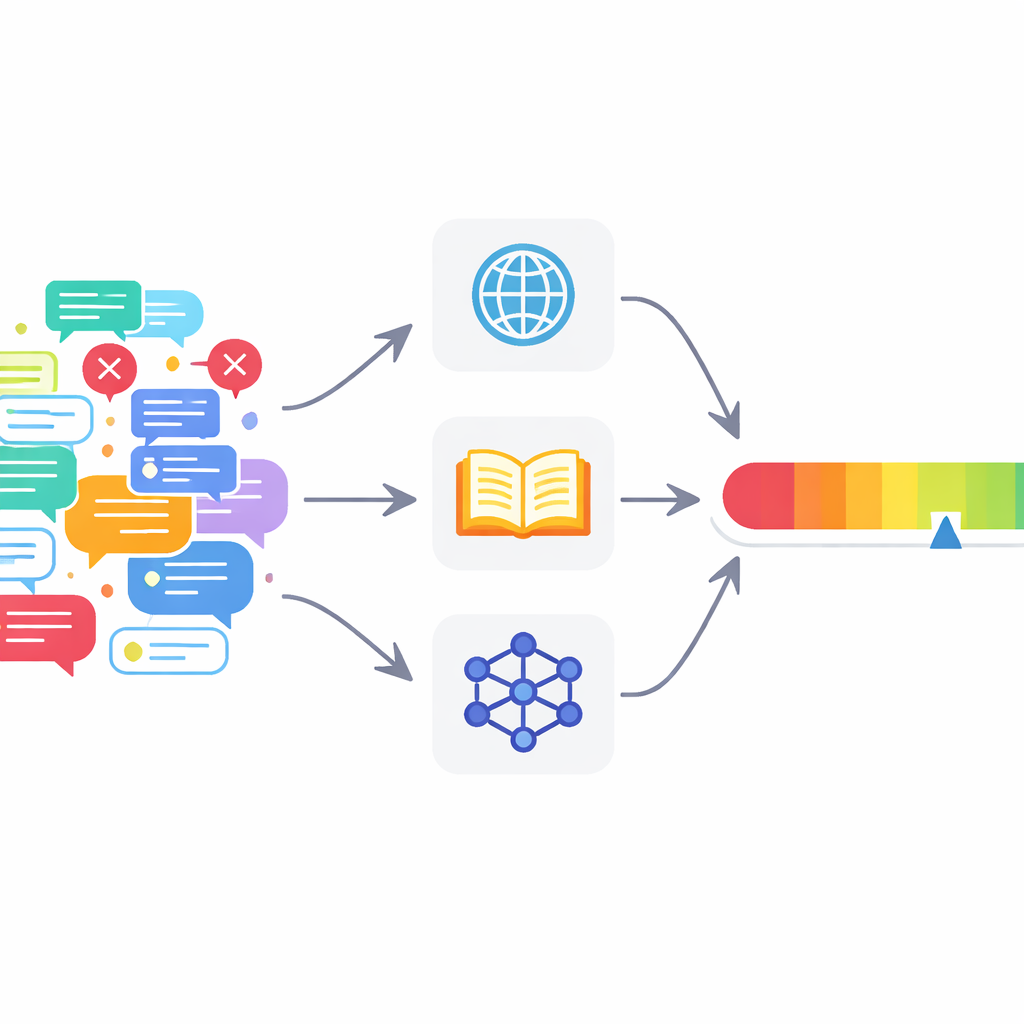
Beaucoup d’outils actuels sont insuffisants
La vérification automatisée des faits s’est fortement développée avec l’essor des grands modèles de langage, ces systèmes d’IA qui alimentent les chatbots modernes. La plupart des systèmes actuels se concentrent sur une décision binaire : une affirmation est‑elle vraie ou fausse ? Ils s’appuient souvent sur une source d’information unique, voire seulement sur la connaissance interne du modèle de langage. Cela engendre deux problèmes dans les discussions réelles en ligne. D’abord, les modèles de langage ont tendance à être excessivement confiants, donnant l’impression d’être sûrs même lorsqu’ils se trompent. Ensuite, les publications réelles mélangent fréquemment des énoncés corrects et incorrects, si bien qu’une étiquette unique vrai/faux pour l’ensemble du texte est trop grossière pour être utile.
Plusieurs vérificateurs numériques plutôt qu’un seul
Pour répondre à ces problèmes, les auteurs proposent un cadre de vérification multi‑agent (MAFC). Plutôt qu’un vérificateur omniscient, le système déploie plusieurs agents, chacun s’appuyant sur une source d’information différente. Un agent cherche sur le web, un autre interroge Wikipédia, et un troisième utilise un modèle d’IA pour générer et comparer des réponses alternatives, une technique adaptée des travaux sur la détection d’hallucinations. Le texte à vérifier est d’abord découpé en affirmations factuelles individuelles. Chaque agent examine chaque affirmation, décide si elle semble vraie ou fausse, et produit un score de confiance entre 0 et 1 reflétant la force de son jugement.
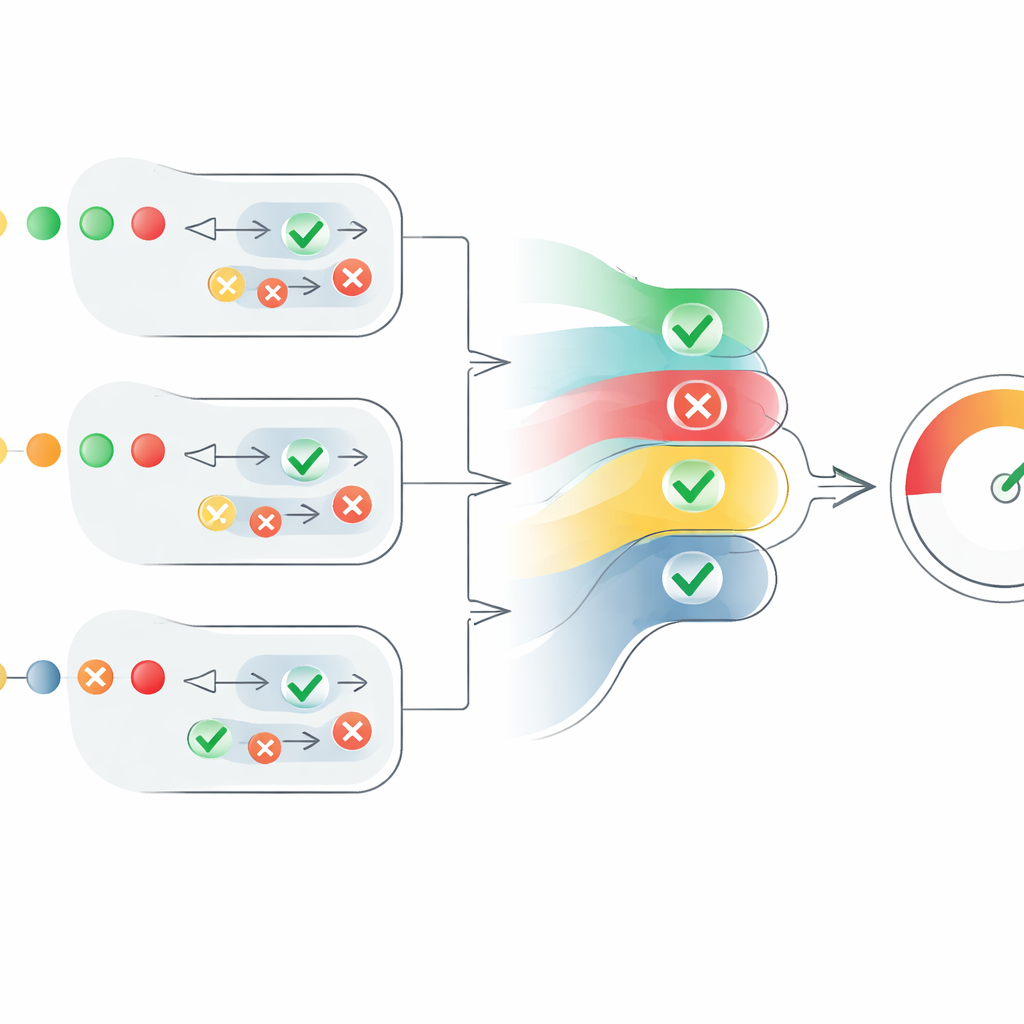
Transformer des avis dispersés en un score unique
Le cœur de l’article est un nouveau mécanisme de notation qui transforme ces avis dispersés d’agents en une mesure claire de crédibilité. Pour chaque affirmation, le système convertit les jugements « vrais » en nombres positifs et les jugements « faux » en nombres négatifs, puis les met à l’échelle par la confiance de chaque agent. Il prend aussi en compte le nombre d’agents en accord, mais de façon contrôlée : l’accord d’agents supplémentaires aide, toutefois chaque voix additionnelle compte un peu moins que la précédente. Cela empêche qu’un grand groupe d’agents peu fiables et incertains n’écrase un plus petit nombre d’agents très confiants. Le résultat est un score au niveau de l’affirmation compris entre 0 et 1. Les scores de toutes les affirmations d’un texte sont ensuite moyennés pour produire un score de crédibilité au niveau du texte, interprétable comme « entièrement vrai », « partiellement vrai » ou « faux ».
Soumettre le cadre à l’épreuve
Les chercheurs ont évalué MAFC sur des jeux de données établis contenant des affirmations courtes et des textes construits. Ils ont utilisé SciFact, qui contient des énoncés scientifiques annotés comme soutenus ou réfutés par des articles de recherche, et FEVER, une large collection d’affirmations construites à partir de Wikipédia. Ils ont aussi créé un nouveau jeu de données, SciFact‑Mixed, où de courts textes sont formés en combinant plusieurs affirmations qui peuvent être toutes correctes, toutes incorrectes ou un mélange des deux. Les performances de MAFC ont été comparées à une solide référence à agent unique et à des méthodes plus simples de combinaison d’agents, comme la moyenne simple ou la somme de leurs scores.
Ce que montrent les résultats
Au travers de ces expériences, le système multi‑agent avec la nouvelle règle de notation a systématiquement surpassé les alternatives. Il était plus précis que le vérificateur unique basé sur l’IA pour déterminer si une affirmation était vraie ou fausse, et il était particulièrement efficace pour reconnaître les textes partiellement vrais mêlant énoncés exacts et trompeurs. Sur le jeu de données FEVER, MAFC a atteint une précision comparable à celle des meilleurs systèmes de compétition spécialement entraînés sur ces données, bien que MAFC ait opéré sans entraînement spécifique. Les auteurs notent que leur cadre présente encore des limites, comme le fait de s’appuyer sur le même modèle d’IA sous‑jacent pour tous les agents et des difficultés avec les affirmations sensibles au temps, mais ils soutiennent qu’il offre une base solide et transparente pour une vérification des faits plus riche et multiniveaux.
Ce que cela signifie pour les lecteurs quotidiens
Pour quelqu’un qui tente de s’y retrouver dans un paysage informationnel bruyant, ce travail montre la voie vers des outils qui font plus que tamponner les publications comme simplement vraies ou fausses. En tirant des preuves de plusieurs sources et en pondérant de façon raisonnée leur accord et leur confiance, le cadre MAFC peut estimer la fiabilité d’un texte dans son ensemble et signaler quand il n’est que partiellement fiable. Bien qu’il reste un prototype de recherche, ce type de système pourrait à terme aider les lecteurs, les modérateurs et les plateformes de discussion à mieux situer l’information sur le spectre allant du fait solide à la rumeur douteuse.
Citation: Dong, Y., Ito, T. Multi-agent systems and credibility-based advanced scoring mechanism in fact-checking. Sci Rep 16, 11814 (2026). https://doi.org/10.1038/s41598-026-41862-z
Mots-clés: désinformation, vérification des faits, grands modèles de langage, systèmes multi‑agents, notation de crédibilité