Clear Sky Science · sv
Fleragentsystem och trovärdighetsbaserad avancerad poängsättningsmekanism vid faktakontroll
Varför kontroll av påståenden online verkligen spelar roll
Varje dag bombarderas vi i sociala nätverk och nyhetsflöden av påståenden om vetenskap, politik och hälsa. Vissa är korrekta, andra missvisande, och en del blandar sanning med felaktigheter på subtila sätt. Denna artikel presenterar ett nytt sätt att bedöma hur tillförlitliga sådana texter är genom att låta flera digitala ”faktagranskare” arbeta tillsammans och därefter noggrant kombinera deras omdömen till en enda trovärdighetspoäng.
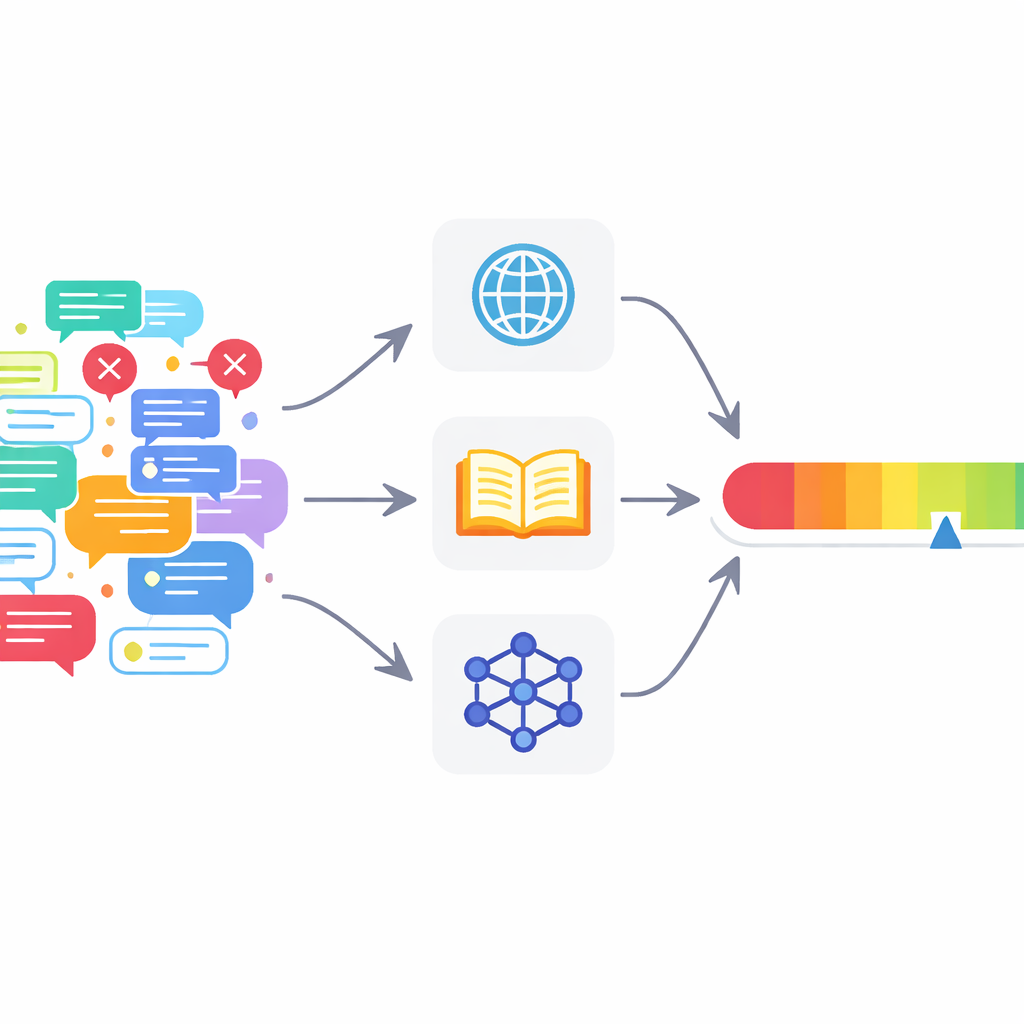
Många nuvarande verktyg räcker inte till
Automatiserad faktakontroll har vuxit snabbt i takt med framväxten av stora språkmodeller, AI-systemen bakom moderna chattbotar. De flesta existerande system fokuserar på ett enkelt ja‑eller‑nej‑beslut: är ett påstående sant eller falskt? De förlitar sig ofta på en enda informationskälla, eller till och med bara på språkmodellens egen kunskap. Det leder till två problem i verkliga online‑diskussioner. För det första tenderar språkmodeller att vara överkonfidentiella och låta säkra även när de har fel. För det andra innehåller verkliga inlägg ofta en blandning av korrekta och felaktiga uttalanden, så en enda sann/falsk‑etikett för hela texten blir för grov för att vara användbar.
Flera digitala faktagranskare i stället för en
För att hantera dessa problem föreslår författarna ett fleragents‑ramverk för faktakontroll (MAFC). I stället för en allvetande granskare använder systemet flera agenter, var och en med tillgång till olika informationskällor. En agent söker på webben, en annan frågar Wikipedia, och en tredje använder en AI‑modell för att generera och jämföra alternativa svar — en teknik hämtad från forskning om hallucinationsdetektion. Texten som ska granskas delas först upp i separata faktapåståenden. Varje agent undersöker varje påstående, bedömer om det verkar vara sant eller falskt, och ger en förtroendescore mellan 0 och 1 som speglar hur starkt den tror på sitt eget omdöme.
Att omvandla spridda åsikter till en enda poäng
Kärnan i artikeln är en ny poängsättningsmeknik som omvandlar dessa spridda agentomdömen till ett tydligt mått på trovärdighet. För varje påstående omvandlar systemet ”sanna” bedömningar till positiva värden och ”falska” bedömningar till negativa, och skalar sedan dessa med varje agents förtroende. Det tar också hänsyn till hur många agenter som är överens, men på ett kontrollerat sätt: överensstämmelse från ytterligare agenter hjälper till, men varje extra röst bidrar lite mindre än den föregående. Detta förhindrar att en stor grupp svaga, osäkra agenter dominerar över ett mindre antal mycket självsäkra. Resultatet blir en poäng per påstående mellan 0 och 1. Poängen för alla påståenden i en text genomsnittsberäknas sedan för att producera en textnivå‑trovärdighetspoäng, som kan tolkas som ”helt sann”, ”delvis sann” eller ”falsk”.
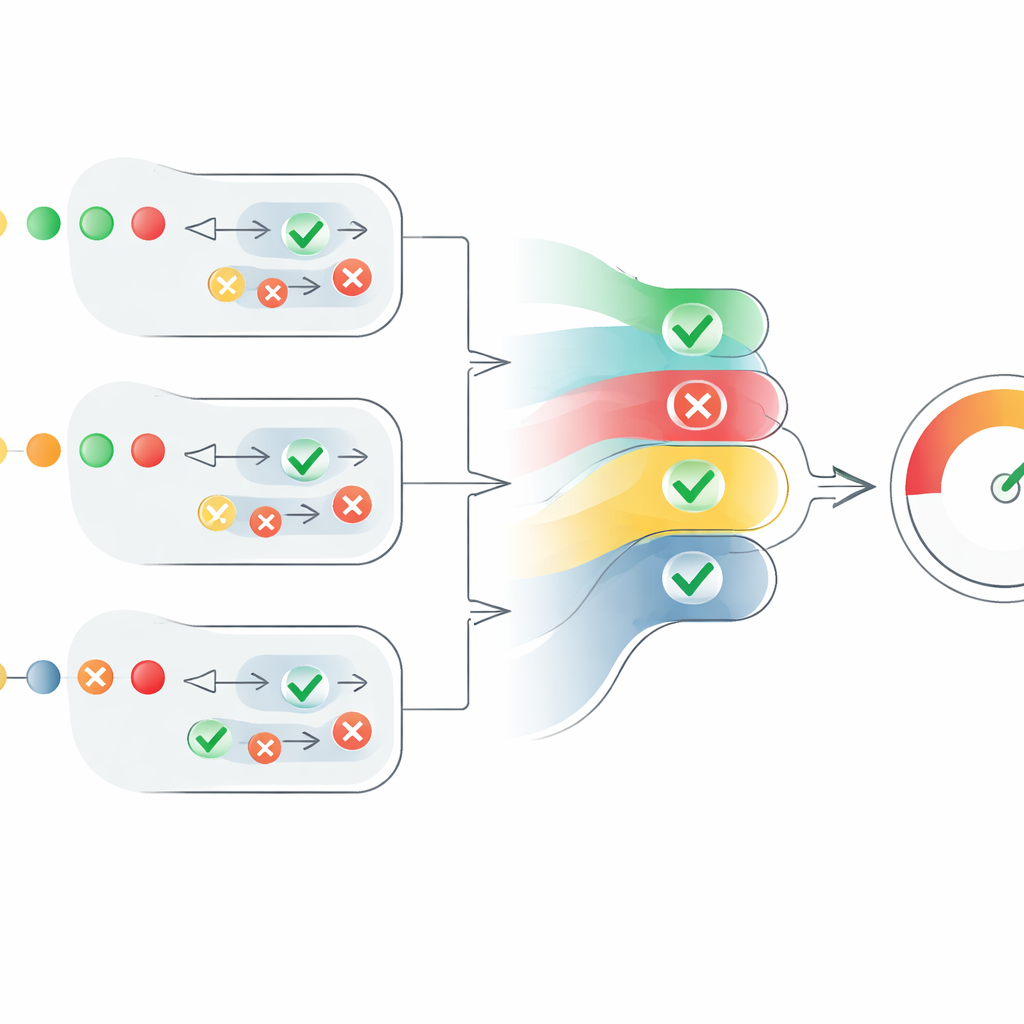
Sätta ramverket på prov
Forskarna utvärderade MAFC på etablerade dataset med korta påståenden och konstruerade texter. De använde SciFact, som innehåller vetenskapliga påståenden märkta som stödda eller motbevisade av forskningsartiklar, och FEVER, en stor samling påståenden byggda från Wikipedia. De skapade också ett nytt dataset, SciFact‑Mixed, där korta texter bildas genom att kombinera flera påståenden som kan vara helt korrekta, helt felaktiga eller en blandning av båda. MAFC:s prestation jämfördes med en stark enstaka‑agent‑baseline och med enklare sätt att kombinera flera agenter, såsom enkel medelvärdesbildning eller summation av deras poäng.
Vad resultaten visar
I dessa experiment presterade fleragentsystemet med den nya poängsättningsregeln konsekvent bättre än alternativen. Det var mer träffsäkert än den enskilda AI‑baserade granskaren när det gällde att avgöra om ett påstående var sant eller falskt, och det var särskilt starkt på att känna igen delvis sanna texter som blandar korrekta och missvisande uttalanden. På FEVER‑datasetet uppnådde MAFC en noggrannhet jämförbar med toppsystem i tävlingar som tränats särskilt på den datan, trots att MAFC fungerade utan sådan specialträning. Författarna noterar att deras ramverk fortfarande har begränsningar, såsom att det förlitar sig på samma underliggande AI‑modell för alla agenter och har svårt med tidkänsliga påståenden, men de menar att det erbjuder en solid och transparent grund för rikare, flernivåig faktakontroll.
Vad detta betyder för vardagsläsaren
För någon som försöker navigera i ett brusigt informationslandskap pekar detta arbete mot verktyg som gör mer än att bara stämpla inlägg som helt sanna eller falska. Genom att hämta bevis från flera källor och väga deras överenskommelse och förtroende på ett principfast sätt kan MAFC‑ramverket uppskatta hur trovärdig en text är överlag och lyfta fram när den bara är delvis pålitlig. Även om det fortfarande är en forskningsprototyp kan denna typ av system i framtiden hjälpa läsare, moderatorer och diskussionsplattformar att bättre förstå var information befinner sig på skalan från solidt faktum till tvivelaktigt rykte.
Citering: Dong, Y., Ito, T. Multi-agent systems and credibility-based advanced scoring mechanism in fact-checking. Sci Rep 16, 11814 (2026). https://doi.org/10.1038/s41598-026-41862-z
Nyckelord: desinformation, faktakontroll, stora språkmodeller, fleragentsystem, trovärdighetsbedömning