Clear Sky Science · nl
Multi-agent systemen en geloofwaardigheidsgebaseerd geavanceerd scoringsmechanisme bij fact‑checking
Waarom het controleren van online beweringen echt belangrijk is
Dagelijks worden we op sociale netwerken en nieuwsfeeds bestookt met beweringen over wetenschap, politiek en gezondheid. Sommige zijn juist, sommige misleidend, en sommige mengen waarheid en onjuistheid op subtiele manieren. Dit artikel introduceert een nieuwe manier om te beoordelen hoe betrouwbaar zulke teksten zijn: meerdere digitale “fact‑checkers” werken samen en hun oordelen worden zorgvuldig gecombineerd tot één geloofwaardigheidsscore.
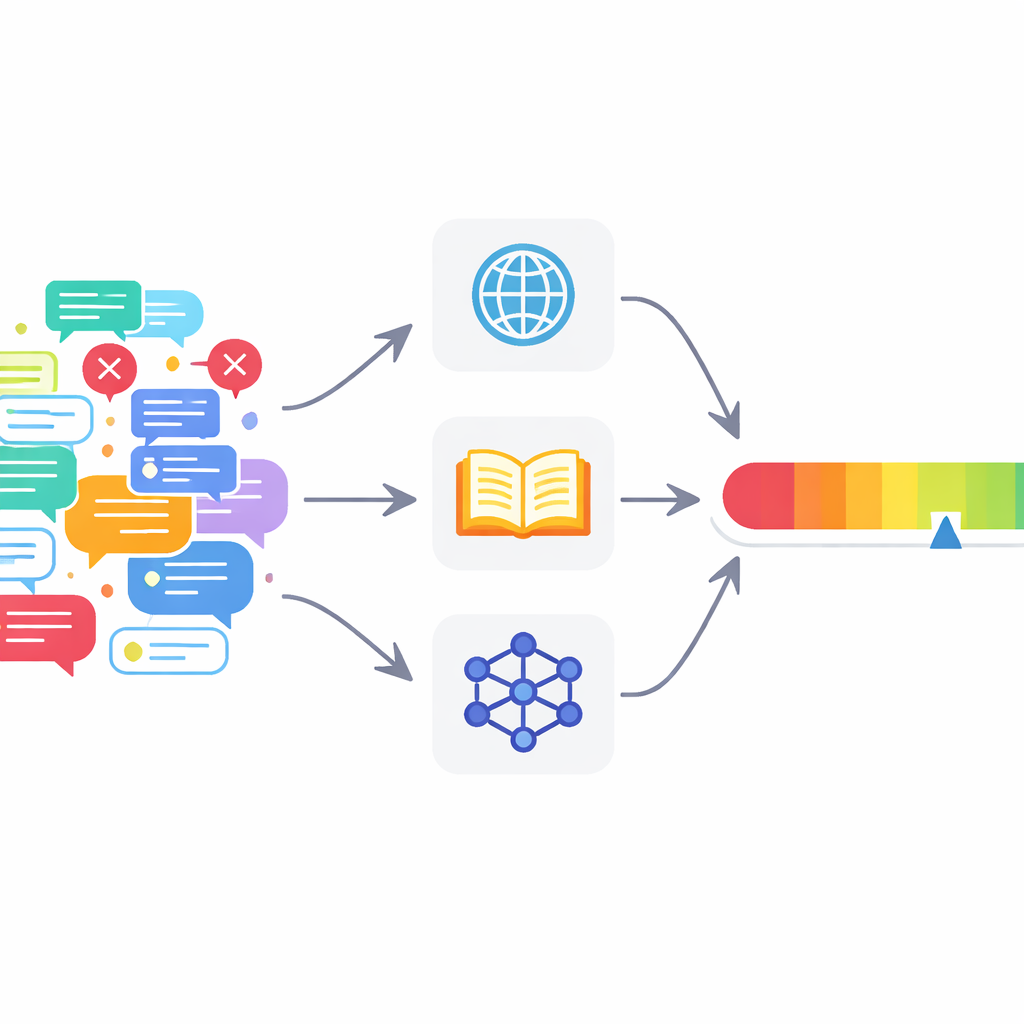
Veel huidige tools schieten tekort
Geautomatiseerd fact‑checken is snel gegroeid naast grote taalmodellen, de AI‑systemen achter moderne chatbots. De meeste bestaande systemen richten zich op een eenvoudige ja‑of‑nee beslissing: is een bewering waar of onwaar? Ze vertrouwen vaak op één informatiebron, of zelfs alleen op de kennis van het taalmodel zelf. Dat leidt tot twee problemen in echte online discussies. Ten eerste zijn taalmodellen geneigd overmoedig te klinken, zeker overkomend zelfs als ze het mis hebben. Ten tweede bevatten echte berichten vaak een mix van correcte en incorrecte uitspraken, zodat één waar/niet‑waar label voor de hele tekst te grof is om nuttig te zijn.
Meerdere digitale fact‑checkers in plaats van één
Om deze problemen aan te pakken stellen de auteurs een multi‑agent fact‑checking‑kader (MAFC) voor. In plaats van één alwetende checker zet het systeem meerdere agenten in, die elk op een andere informatiebron steunen. De ene agent doorzoekt het web, een andere raadpleegt Wikipedia, en een derde gebruikt een AI‑model om alternatieve antwoorden te genereren en te vergelijken — een techniek ontleend aan onderzoek naar het detecteren van hallucinerende antwoorden. De te controleren tekst wordt eerst opgesplitst in afzonderlijke feitelijke beweringen. Elke agent onderzoekt elke bewering, beoordeelt of deze waar of onwaar lijkt, en geeft een vertrouwensscore tussen 0 en 1 die aangeeft hoe sterk hij in zijn oordeel gelooft.
Verspreide meningen omzetten in één score
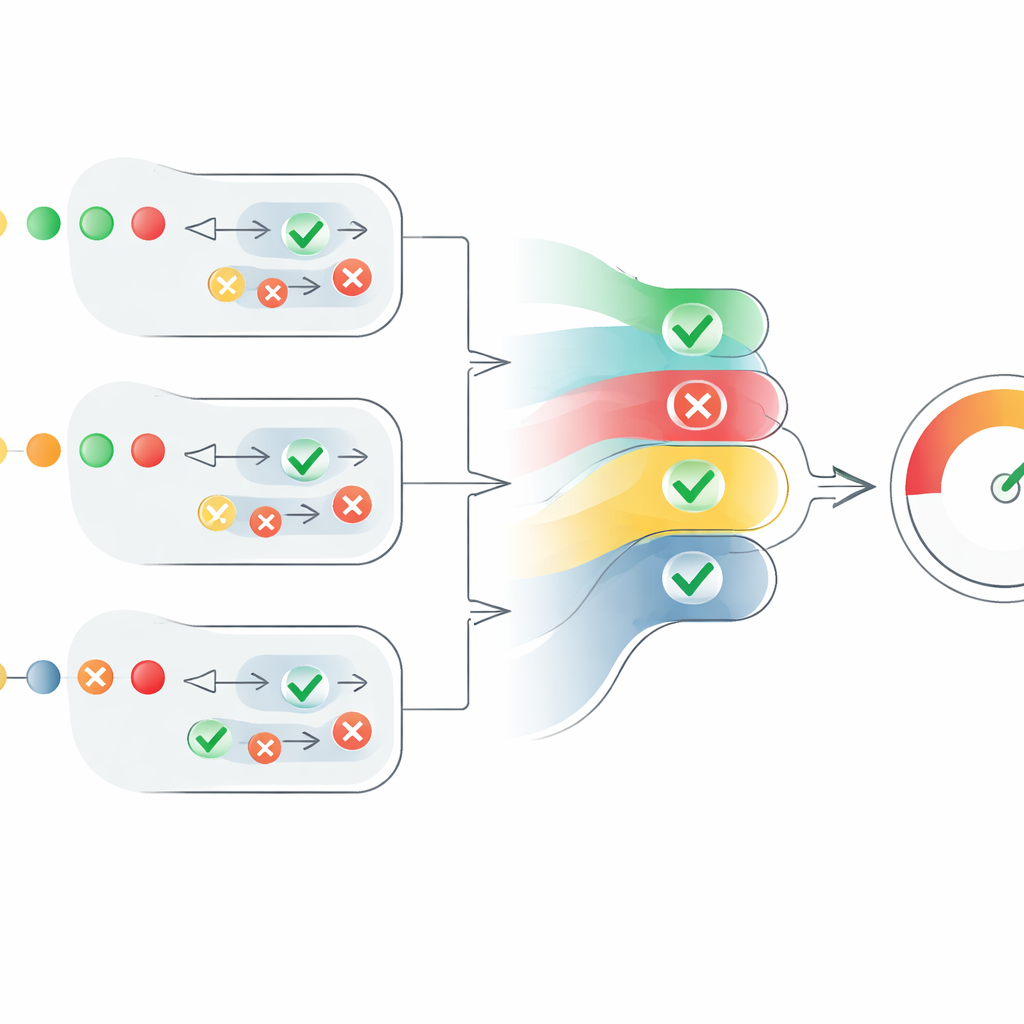
Het hart van het artikel is een nieuw scoringsmechanisme dat deze verspreide agent‑oordelen omzet in een duidelijke maat voor geloofwaardigheid. Voor elke bewering zet het systeem “waar”‑oordelen om in positieve getallen en “onwaar”‑oordelen in negatieve, en schaalt die vervolgens met het vertrouwen van elke agent. Het houdt ook rekening met hoeveel agenten het eens zijn, maar op een gecontroleerde manier: instemming van extra agenten helpt wel, maar elke extra stem telt iets minder mee dan de vorige. Dit voorkomt dat een grote groep zwakke, onzekere agenten een kleinere groep zeer zelfverzekerde agenten overstemmen. Het resultaat is een beweringsniveau‑score tussen 0 en 1. De scores voor alle beweringen in een tekst worden vervolgens gemiddeld om een tekstniveau‑geloofwaardigheidsscore te produceren, die geïnterpreteerd kan worden als “volledig waar”, “gedeeltelijk waar” of “onwaar”.
Het kader op de proef stellen
De onderzoekers evalueerden MAFC op gevestigde datasets van korte beweringen en geconstrueerde teksten. Ze gebruikten SciFact, dat wetenschappelijke beweringen bevat die door onderzoekspapers als ondersteund of weerlegd zijn gelabeld, en FEVER, een grote verzameling beweringen opgebouwd uit Wikipedia. Ze bouwden ook een nieuwe dataset, SciFact‑Mixed, waarin korte teksten zijn samengesteld uit meerdere beweringen die allemaal correct, allemaal onjuist of een mix daarvan kunnen zijn. De prestaties van MAFC werden vergeleken met een sterke single‑agent baseline en met eenvoudigere manieren om meerdere agenten te combineren, zoals simpele gemiddelden of het optellen van hun scores.
Wat de resultaten laten zien
In deze experimenten presteerde het multi‑agent systeem met de nieuwe scoringsregel consequent beter dan de alternatieven. Het was nauwkeuriger dan de enkele AI‑gebaseerde checker bij het vaststellen of een bewering waar of onwaar was, en het was bijzonder goed in het herkennen van deels waarachtige teksten die nauwkeurige en misleidende uitspraken mengen. Op de FEVER‑dataset behaalde MAFC een nauwkeurigheid vergelijkbaar met topcompetitiesystemen die speciaal op die data waren getraind, ook al werkte MAFC zonder dergelijke training. De auteurs merken op dat hun kader nog beperkingen kent, zoals het vertrouwen op hetzelfde onderliggende AI‑model voor alle agenten en moeite met tijdgevoelige beweringen, maar ze betogen dat het een solide en transparante basis biedt voor rijkere, meerlagige fact‑checking.
Wat dit betekent voor alledaagse lezers
Voor iemand die probeert te navigeren in een rumoerige informatiesfeer wijst dit werk op gereedschap dat meer doet dan berichten simpelweg als waar of onwaar stempelen. Door bewijs uit meerdere bronnen te halen en hun overeenstemming en vertrouwen op een principiële manier te wegen, kan het MAFC‑kader inschatten hoe betrouwbaar een tekst in het algemeen is en aangeven wanneer die slechts gedeeltelijk betrouwbaar is. Hoewel nog een onderzoeksprototype, kan dit soort systeem uiteindelijk lezers, moderators en discussieplatforms helpen beter te begrijpen waar informatie staat op het spectrum van solide feit tot dubieus gerucht.
Bronvermelding: Dong, Y., Ito, T. Multi-agent systems and credibility-based advanced scoring mechanism in fact-checking. Sci Rep 16, 11814 (2026). https://doi.org/10.1038/s41598-026-41862-z
Trefwoorden: misinformatie, fact‑checking, grote taalmodellen, multi-agent systemen, geloofwaardigheidsscores