Clear Sky Science · ja
ファクトチェックにおけるマルチエージェントシステムと信頼性ベースの高度なスコアリング機構
オンライン上の主張を検証することが本当に重要な理由
毎日、ソーシャルネットワークやニュースフィードは科学、政治、健康に関する様々な主張を私たちに浴びせかけます。正確なものもあれば、誤解を招くもの、真実と虚偽が微妙に混ざり合っているものもあります。本稿は、そのような文書がどれだけ信頼できるかを評価する新しい方法を紹介します。複数のデジタル「ファクトチェッカー」を協調させ、それらの意見を慎重に組み合わせて単一の信頼性スコアを算出するアプローチです。
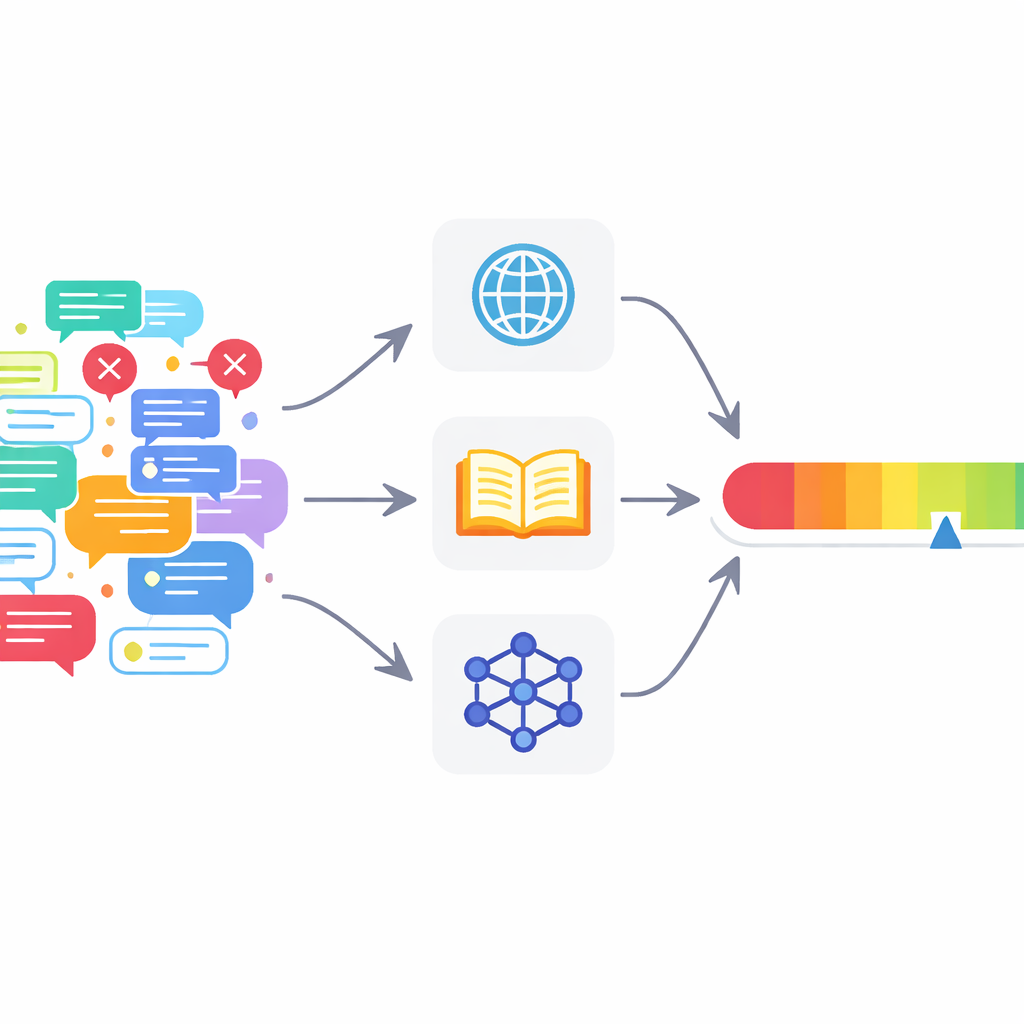
多くの既存ツールが十分でない理由
自動ファクトチェックは、現代のチャットボット等の基盤となる大規模言語モデルの発展とともに急速に成長してきました。既存のシステムの多くは単純な二者択一の判断、すなわち主張は「真」か「偽」かに焦点を当てています。これらはしばしば単一の情報源、あるいは言語モデル自身の知識のみに依存します。その結果、実際のオンライン議論では二つの問題が生じます。第一に、言語モデルは過信しがちで、誤っているときでも確信を持って語る傾向があります。第二に、実際の投稿は正しい記述と誤った記述を混在させることが多く、テキスト全体に対する単一の真/偽ラベルは粗すぎて有用性に欠けます。
一つのチェッカーではなく複数のデジタルファクトチェッカー
これらの課題に対処するために、著者らはマルチエージェント・ファクトチェックフレームワーク(MAFC)を提案します。一つの全知的なチェッカーの代わりに、システムは異なる情報源に基づく複数のエージェントを展開します。あるエージェントはウェブを検索し、別のエージェントはウィキペディアを照会し、さらに別のエージェントはAIモデルを用いて代替回答を生成・比較する—これはハルシネーション検出研究から適応した手法です。チェック対象のテキストはまず個々の事実主張に分割されます。各エージェントは各主張を調査し、その主張が真に見えるか偽に見えるかを判断し、自らの判断の確信度を0から1のスコアで出力します。
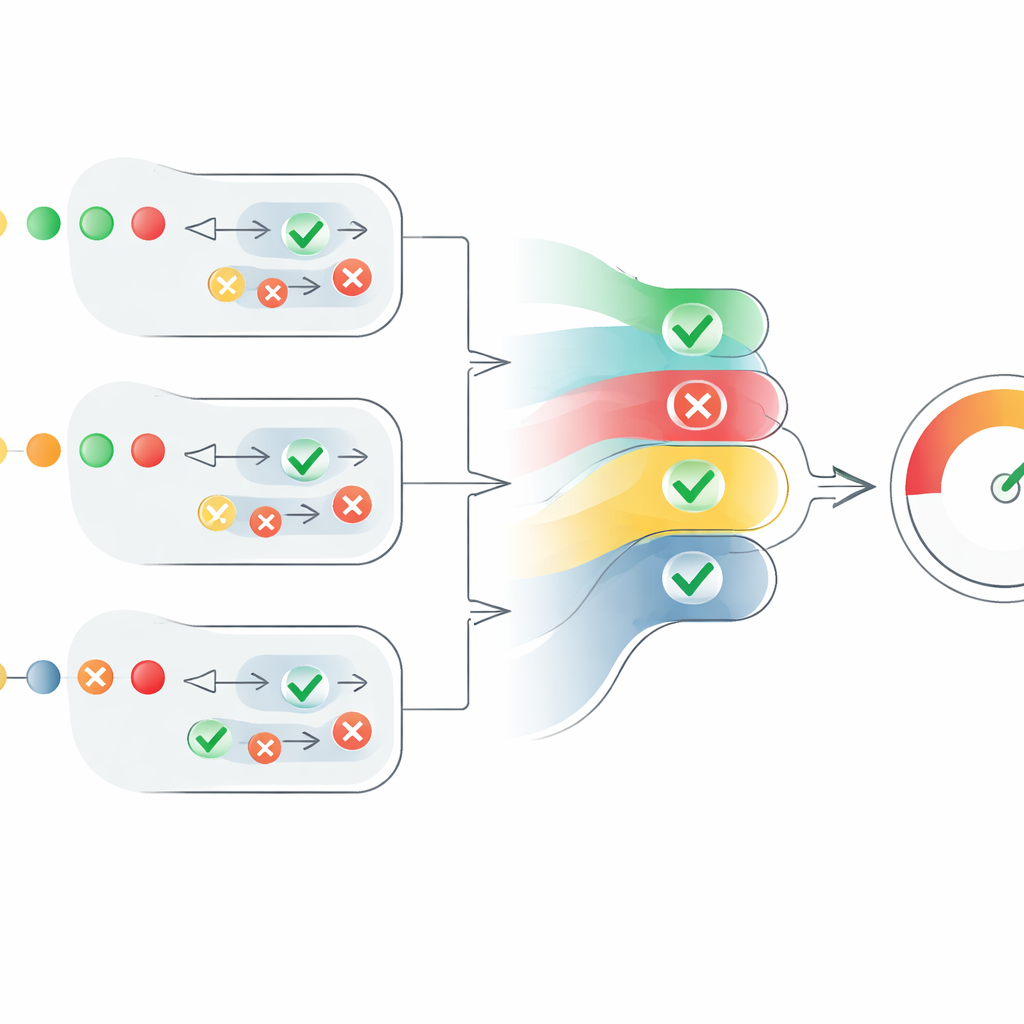
ばらばらの意見を単一のスコアに変換する
本稿の核心は、これらの分散したエージェント意見を明確な信頼性指標に変換する新しいスコアリング機構です。各主張について、システムは「真」の判断を正の数に、「偽」の判断を負の数に変換し、それぞれを各エージェントの確信度でスケーリングします。また、何人のエージェントが同意しているかも考慮しますが、制御された方法で行います:追加のエージェントからの同意は有利に働きますが、各追加の声は前の声よりもわずかに寄与が減ります。これにより、不確かで弱い多数のエージェントが少数の高確信のエージェントを圧倒してしまうのを防ぎます。結果として各主張には0から1のスコアが得られ、テキスト内の全主張のスコアを平均してテキストレベルの信頼性スコアを算出します。このスコアは「完全に真」「部分的に真」「偽」のように解釈できます。
フレームワークの検証
研究者らはMAFCを短い主張や構成テキストの既存データセットで評価しました。使用したデータセットには、研究論文によって支持または反証された科学的主張を含むSciFact、ウィキペディアに基づいて構成された大規模な主張コレクションであるFEVERが含まれます。さらに、短いテキストを複数の主張の組み合わせで作成し、すべて正しい場合、すべて誤りの場合、あるいは混在する場合がある新しいデータセットSciFact-Mixedも作成しました。MAFCの性能は、強力な単一エージェントのベースラインや、単純平均やスコアの合算といった複数エージェントの単純な結合法と比較されました。
結果が示すもの
これらの実験を通じて、新しいスコアリング規則を組み込んだマルチエージェントシステムは一貫して代替手法を上回りました。単一のAIベースのチェッカーよりも主張の真偽判定で高い正確性を示し、特に正確な記述と誤解を招く記述が混在する「部分的に真」テキストの識別に強みを発揮しました。FEVERデータセット上では、MAFCはそのデータで特別に訓練された上位の競合システムに匹敵する精度を達成しました。これはMAFCがそのような訓練を行わずに動作した点を踏まえると注目に値します。著者らは、すべてのエージェントが同じ基盤のAIモデルに依存している点や、時間に敏感な主張への苦手意識などの制約が残ることも指摘していますが、より豊かで多層的なファクトチェックのための堅実で透明性のある基盤を提供すると論じています。
日常の読者にとっての意味
雑多な情報の海を渡る読者にとって、この研究は投稿を単に真か偽かと判定する以上のことを行うツールの可能性を示しています。複数の情報源から証拠を集め、それらの同意と確信度を原理的に重み付けすることで、MAFCフレームワークはテキスト全体がどれだけ信頼できるかを推定し、部分的にしか信頼できない箇所を浮き彫りにできます。まだ研究プロトタイプではありますが、この種のシステムは将来的に読者、モデレーター、議論プラットフォームが情報を確かな事実から疑わしい噂までのスペクトル上でより正確に理解するのに役立つ可能性があります。
引用: Dong, Y., Ito, T. Multi-agent systems and credibility-based advanced scoring mechanism in fact-checking. Sci Rep 16, 11814 (2026). https://doi.org/10.1038/s41598-026-41862-z
キーワード: 誤情報, ファクトチェック, 大規模言語モデル, マルチエージェントシステム, 信頼度スコアリング