Clear Sky Science · es
Sistemas multiagente y un mecanismo avanzado de puntuación basado en credibilidad en la verificación de hechos
Por qué verificar las afirmaciones en línea realmente importa
Cada día, las redes sociales y los feeds de noticias nos bombardean con afirmaciones sobre ciencia, política y salud. Algunas son precisas, otras son engañosas y otras mezclan verdad y falsedad de maneras sutiles. Este artículo presenta una nueva forma de evaluar cuán confiables son esos textos: varios “verificadores” digitales trabajan juntos y sus opiniones se combinan cuidadosamente en una única puntuación de credibilidad.
Muchos instrumentos actuales se quedan cortos
La verificación automática de hechos ha crecido rápidamente junto con los modelos de lenguaje a gran escala, los sistemas de IA detrás de herramientas como los chatbots modernos. La mayoría de los sistemas existentes se centran en una decisión simple de sí o no: ¿una afirmación es verdadera o falsa? A menudo dependen de una única fuente de información, o incluso solo del conocimiento del propio modelo de lenguaje. Esto conduce a dos problemas en discusiones reales en línea. Primero, los modelos de lenguaje tienden a mostrar exceso de confianza, sonando seguros incluso cuando están equivocados. Segundo, las publicaciones reales con frecuencia mezclan afirmaciones correctas e incorrectas, por lo que una etiqueta única de verdadero/falso para todo el texto es demasiado burda para ser útil.
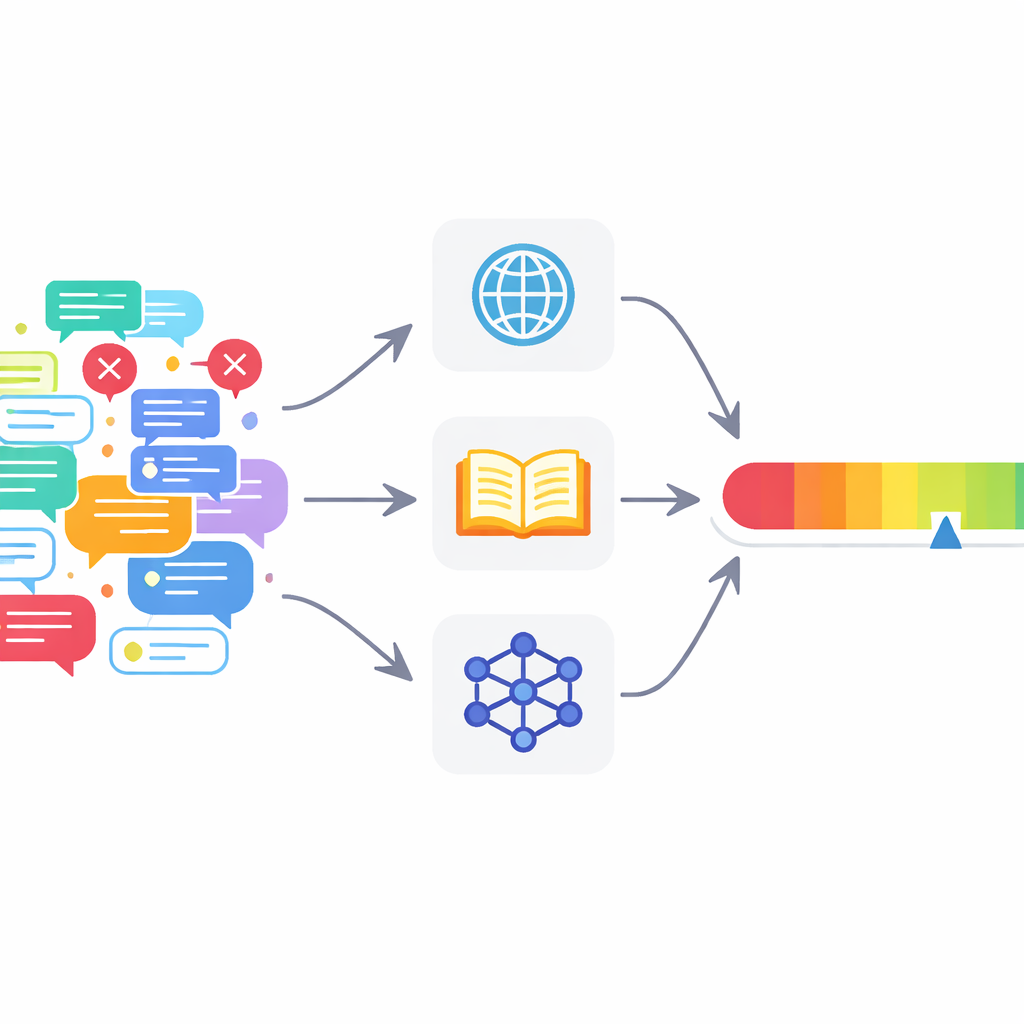
Muchos verificadores digitales en lugar de uno
Para abordar estos problemas, los autores proponen un marco de verificación multiagente (MAFC). En lugar de un verificador omnisciente, el sistema despliega varios agentes, cada uno recurriendo a una fuente de información distinta. Un agente busca en la web, otro consulta Wikipedia y un tercero utiliza un modelo de IA para generar y comparar respuestas alternativas, una técnica adaptada de la investigación sobre detección de alucinaciones. El texto a verificar se divide primero en afirmaciones fácticas individuales. Cada agente investiga cada afirmación, decide si parece verdadera o falsa y produce una puntuación de confianza entre 0 y 1 que refleja cuánto cree en su propio juicio.
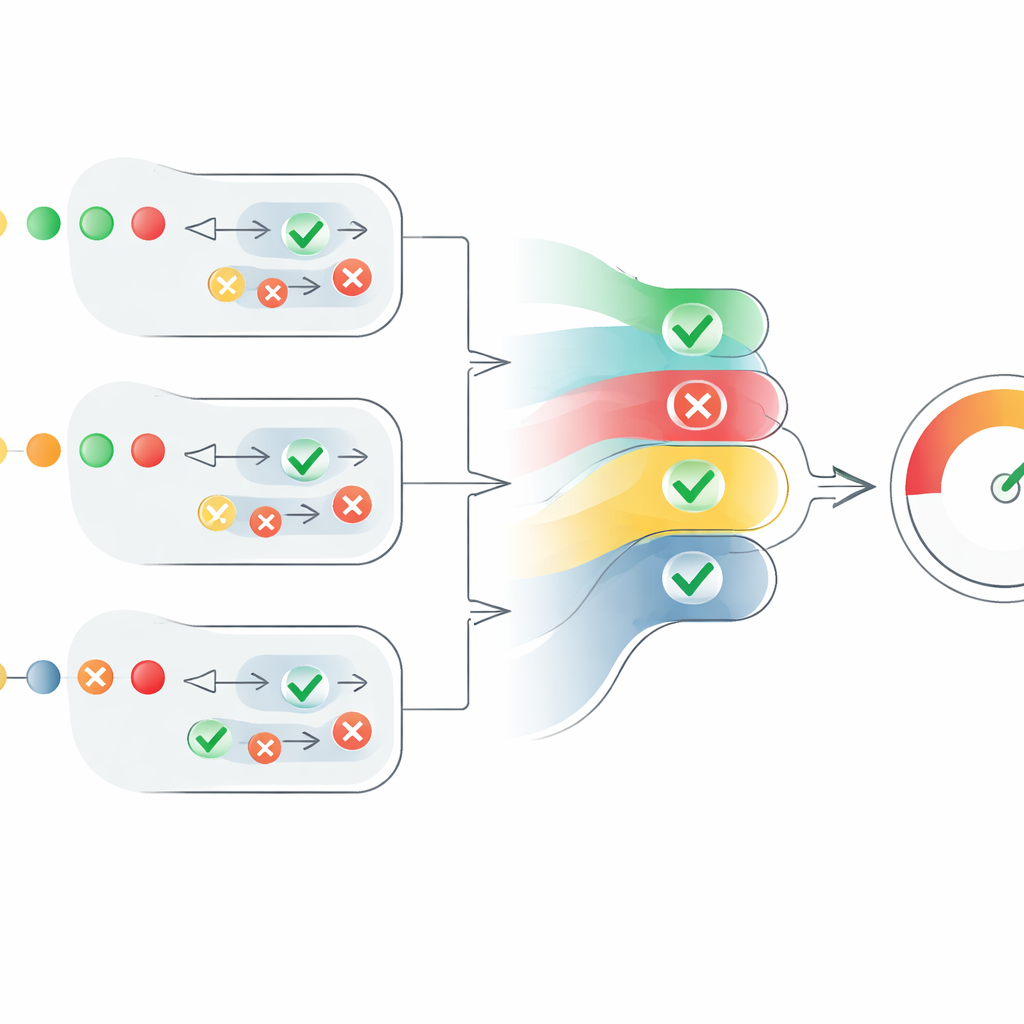
Convertir opiniones dispersas en una única puntuación
El núcleo del artículo es un nuevo mecanismo de puntuación que transforma estas opiniones dispersas de los agentes en una medida clara de credibilidad. Para cada afirmación, el sistema convierte los juicios “verdadero” en números positivos y los “falso” en negativos, y luego los escala por la confianza de cada agente. También tiene en cuenta cuántos agentes coinciden, pero de forma controlada: el acuerdo de agentes adicionales ayuda, pero cada voz extra aporta un poco menos que la anterior. Esto evita que un gran grupo de agentes débiles e inciertos eclipse a un número menor de agentes muy confiados. El resultado es una puntuación a nivel de afirmación entre 0 y 1. Las puntuaciones de todas las afirmaciones en un texto se promedian para producir una puntuación de credibilidad a nivel de texto, que puede interpretarse como “totalmente verdadero”, “parcialmente verdadero” o “falso”.
Poniendo el marco a prueba
Los investigadores evaluaron MAFC en conjuntos de datos establecidos de afirmaciones breves y textos construidos. Usaron SciFact, que contiene afirmaciones científicas etiquetadas como apoyadas o refutadas por artículos de investigación, y FEVER, una gran colección de afirmaciones construidas a partir de Wikipedia. También crearon un nuevo conjunto de datos, SciFact‑Mixed, en el que se forman textos breves combinando varias afirmaciones que pueden ser todas correctas, todas incorrectas o una mezcla de ambas. El rendimiento de MAFC se comparó con una sólida línea base de un solo agente y con formas más simples de combinar múltiples agentes, como el promedio simple o la suma de sus puntuaciones.
Qué muestran los resultados
En estos experimentos, el sistema multiagente con la nueva regla de puntuación superó de forma consistente a las alternativas. Fue más preciso que el verificador único basado en IA al decidir si una afirmación era verdadera o falsa, y resultó especialmente eficaz en reconocer textos parcialmente verdaderos que mezclan afirmaciones precisas y engañosas. En el conjunto FEVER, MAFC alcanzó una precisión comparable a la de sistemas punteros en la competencia que habían sido entrenados específicamente con esos datos, aunque MAFC operó sin tal entrenamiento. Los autores señalan que su marco aún tiene limitaciones, como depender del mismo modelo de IA subyacente para todos los agentes y tener dificultades con afirmaciones sensibles al tiempo, pero sostienen que ofrece una base sólida y transparente para una verificación de hechos más rica y multinivel.
Qué significa esto para los lectores de a pie
Para alguien que intenta navegar en un paisaje informativo ruidoso, este trabajo apunta hacia herramientas que hacen más que etiquetar las publicaciones como simplemente verdaderas o falsas. Al extraer evidencias de varias fuentes y ponderar su acuerdo y confianza de manera principiada, el marco MAFC puede estimar cuán digno de confianza es un texto en conjunto y señalar cuándo es solo parcialmente fiable. Aunque sigue siendo un prototipo de investigación, este tipo de sistema podría, eventualmente, ayudar a lectores, moderadores y plataformas de discusión a entender mejor dónde se sitúa la información en el espectro desde un hecho sólido hasta un rumor dudoso.
Cita: Dong, Y., Ito, T. Multi-agent systems and credibility-based advanced scoring mechanism in fact-checking. Sci Rep 16, 11814 (2026). https://doi.org/10.1038/s41598-026-41862-z
Palabras clave: desinformación, verificación de hechos, modelos de lenguaje a gran escala, sistemas multiagente, puntuación de credibilidad