Clear Sky Science · pt
Sistemas multiagente e mecanismo avançado de pontuação baseado em credibilidade na checagem de fatos
Por que verificar afirmações online realmente importa
Diariamente, redes sociais e feeds de notícias nos bombardeiam com afirmações sobre ciência, política e saúde. Algumas são precisas, outras são enganosas, e outras misturam verdade e falsidade de forma sutil. Este artigo apresenta uma nova maneira de avaliar quão confiáveis são esses textos, fazendo com que vários “verificadores de fatos” digitais trabalhem juntos e depois combinando cuidadosamente suas opiniões em uma única pontuação de credibilidade.
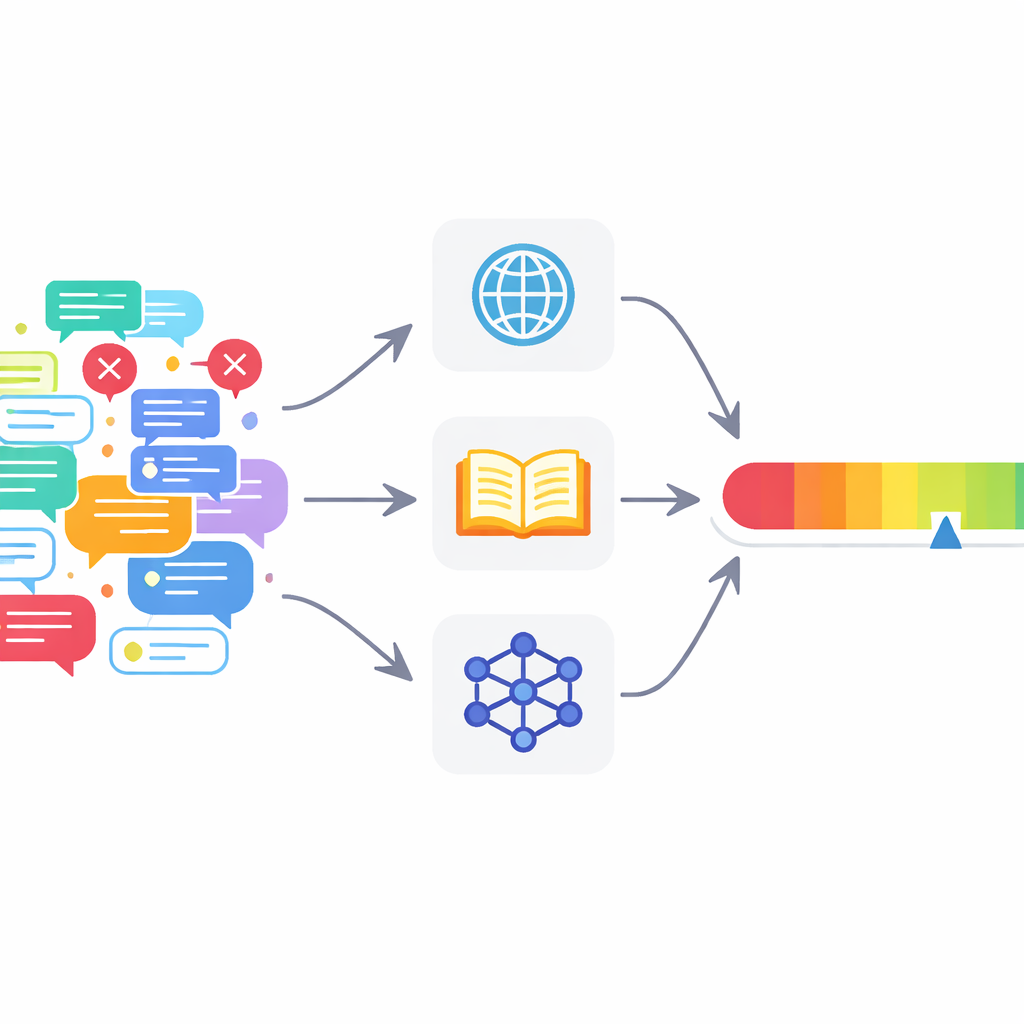
Muitas ferramentas atuais deixam a desejar
A checagem automática de fatos cresceu rapidamente junto com os grandes modelos de linguagem, os sistemas de IA por trás de ferramentas como os chatbots modernos. A maioria dos sistemas existentes foca numa decisão simples de sim ou não: uma afirmação é verdadeira ou falsa? Eles frequentemente dependem de uma única fonte de informação, ou até mesmo do próprio conhecimento do modelo de linguagem. Isso leva a dois problemas nas discussões online reais. Primeiro, modelos de linguagem tendem a ser excessivamente confiantes, soando certos mesmo quando estão errados. Segundo, publicações reais frequentemente misturam afirmações corretas e incorretas, então um único rótulo verdadeiro/falso para todo o texto é muito rústico para ser útil.
Muitos verificadores digitais em vez de apenas um
Para enfrentar essas questões, os autores propõem uma arquitetura de checagem multiagente (MAFC). Em vez de um verificador onisciente, o sistema emprega vários agentes, cada um recorrendo a uma fonte de informação diferente. Um agente pesquisa a web, outro consulta a Wikipedia, e um terceiro usa um modelo de IA para gerar e comparar respostas alternativas, uma técnica adaptada de pesquisas sobre detecção de alucinações. O texto a ser verificado é primeiro dividido em afirmações factuais individuais. Cada agente investiga cada afirmação, decide se ela aparenta ser verdadeira ou falsa, e produz uma pontuação de confiança entre 0 e 1 que reflete o quão fortemente acredita em seu próprio julgamento.
Transformando opiniões dispersas em uma única pontuação
O cerne do artigo é um novo mecanismo de pontuação que transforma essas opiniões dispersas dos agentes em uma medida clara de credibilidade. Para cada afirmação, o sistema converte julgamentos “verdadeiros” em números positivos e julgamentos “falsos” em números negativos, então escala esses valores pela confiança de cada agente. Também leva em conta quantos agentes concordam, mas de forma controlada: a concordância de agentes adicionais ajuda, porém cada voz extra contribui um pouco menos que a anterior. Isso evita que um grande grupo de agentes fracos e incertos sobrepuje um número menor de agentes altamente confiantes. O resultado é uma pontuação por afirmação entre 0 e 1. As pontuações de todas as afirmações em um texto são então promediadas para produzir uma pontuação de credibilidade ao nível do texto, que pode ser interpretada como “totalmente verdadeira”, “parcialmente verdadeira” ou “falsa”.
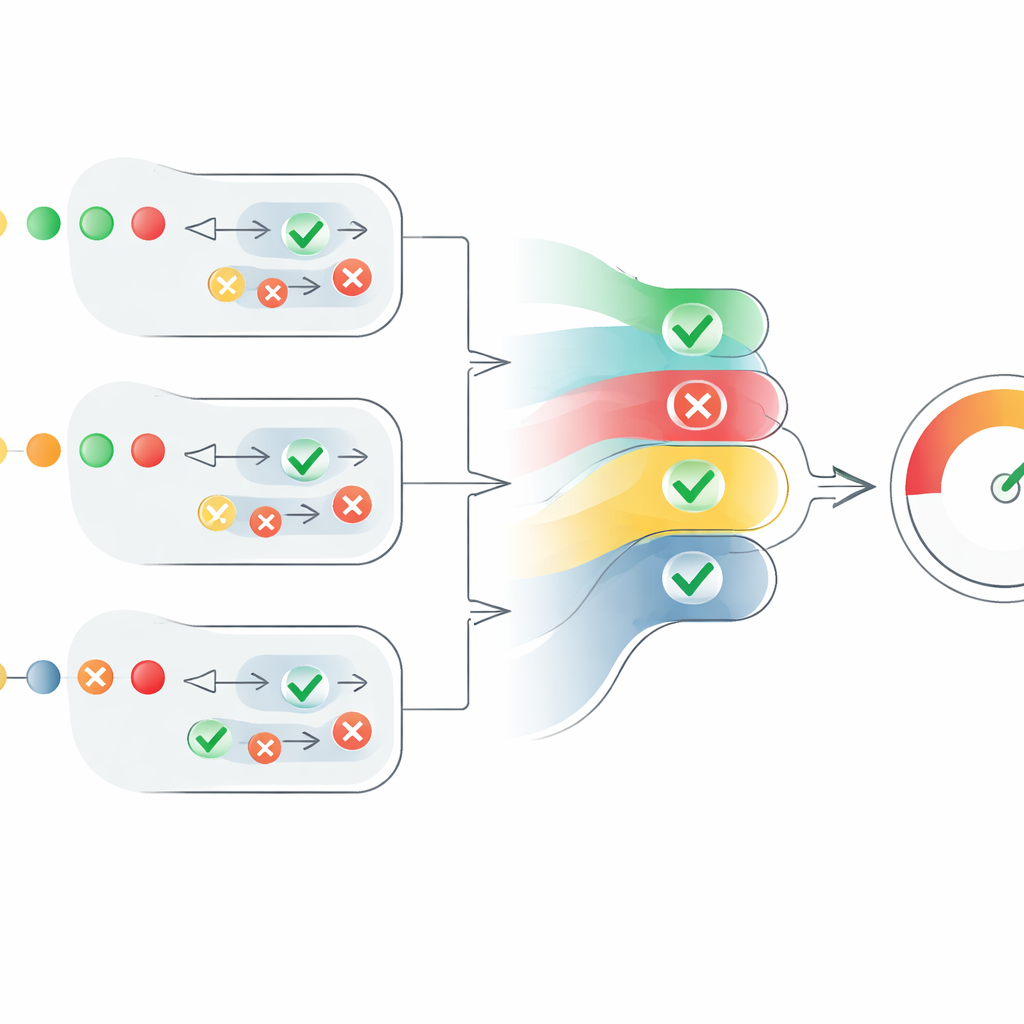
Colocando a arquitetura à prova
Os pesquisadores avaliaram o MAFC em conjuntos de dados estabelecidos de afirmações curtas e textos construídos. Usaram o SciFact, que contém declarações científicas rotuladas como apoiadas ou refutadas por artigos de pesquisa, e o FEVER, uma grande coleção de afirmações construídas a partir da Wikipedia. Eles também criaram um novo conjunto de dados, SciFact‑Mixed, onde textos curtos são formados combinando várias afirmações que podem ser todas corretas, todas incorretas ou uma mistura de ambas. O desempenho do MAFC foi comparado a um forte baseline de agente único e a formas mais simples de combinar múltiplos agentes, como média simples ou soma de suas pontuações.
O que os resultados mostram
Ao longo desses experimentos, o sistema multiagente com a nova regra de pontuação superou consistentemente as alternativas. Ele foi mais preciso do que o verificador único baseado em IA ao decidir se uma afirmação era verdadeira ou falsa, e mostrou-se especialmente forte em reconhecer textos parcialmente verdadeiros que misturam afirmações precisas e enganosas. No conjunto FEVER, o MAFC alcançou precisão comparável aos principais sistemas de competição que haviam sido treinados especificamente nesses dados, apesar de o MAFC operar sem esse tipo de treinamento. Os autores observam que a arquitetura ainda tem limitações, como depender do mesmo modelo de IA subjacente para todos os agentes e ter dificuldades com afirmações sensíveis ao fator temporal, mas defendem que ela oferece uma base sólida e transparente para uma checagem de fatos mais rica e multinível.
O que isso significa para leitores no dia a dia
Para quem tenta navegar num cenário informacional ruidoso, este trabalho aponta para ferramentas que fazem mais do que simplesmente carimbar publicações como verdadeiras ou falsas. Ao reunir evidências de várias fontes e ponderar sua concordância e confiança de maneira principiada, a arquitetura MAFC pode estimar quão confiável é um texto no geral e destacar quando ele é apenas parcialmente confiável. Embora ainda seja um protótipo de pesquisa, esse tipo de sistema poderia, no futuro, ajudar leitores, moderadores e plataformas de discussão a entender melhor onde a informação se situa no espectro entre fato sólido e boato duvidoso.
Citação: Dong, Y., Ito, T. Multi-agent systems and credibility-based advanced scoring mechanism in fact-checking. Sci Rep 16, 11814 (2026). https://doi.org/10.1038/s41598-026-41862-z
Palavras-chave: desinformação, checagem de fatos, grandes modelos de linguagem, sistemas multiagente, pontuação de credibilidade