Clear Sky Science · pl
Systemy wieloagentowe i zaawansowany mechanizm punktowania oparty na wiarygodności w weryfikacji faktów
Dlaczego weryfikowanie twierdzeń w sieci ma znaczenie
Codziennie sieci społecznościowe i kanały informacyjne zasypują nas twierdzeniami dotyczącymi nauki, polityki i zdrowia. Niektóre są prawdziwe, inne wprowadzające w błąd, a jeszcze inne subtelnie mieszają prawdę z fałszem. W artykule przedstawiono nowy sposób oceny, na ile takie teksty są godne zaufania: kilku cyfrowych „weryfikatorów” współpracuje ze sobą, a ich opinie są starannie łączone w jedną ocenę wiarygodności.
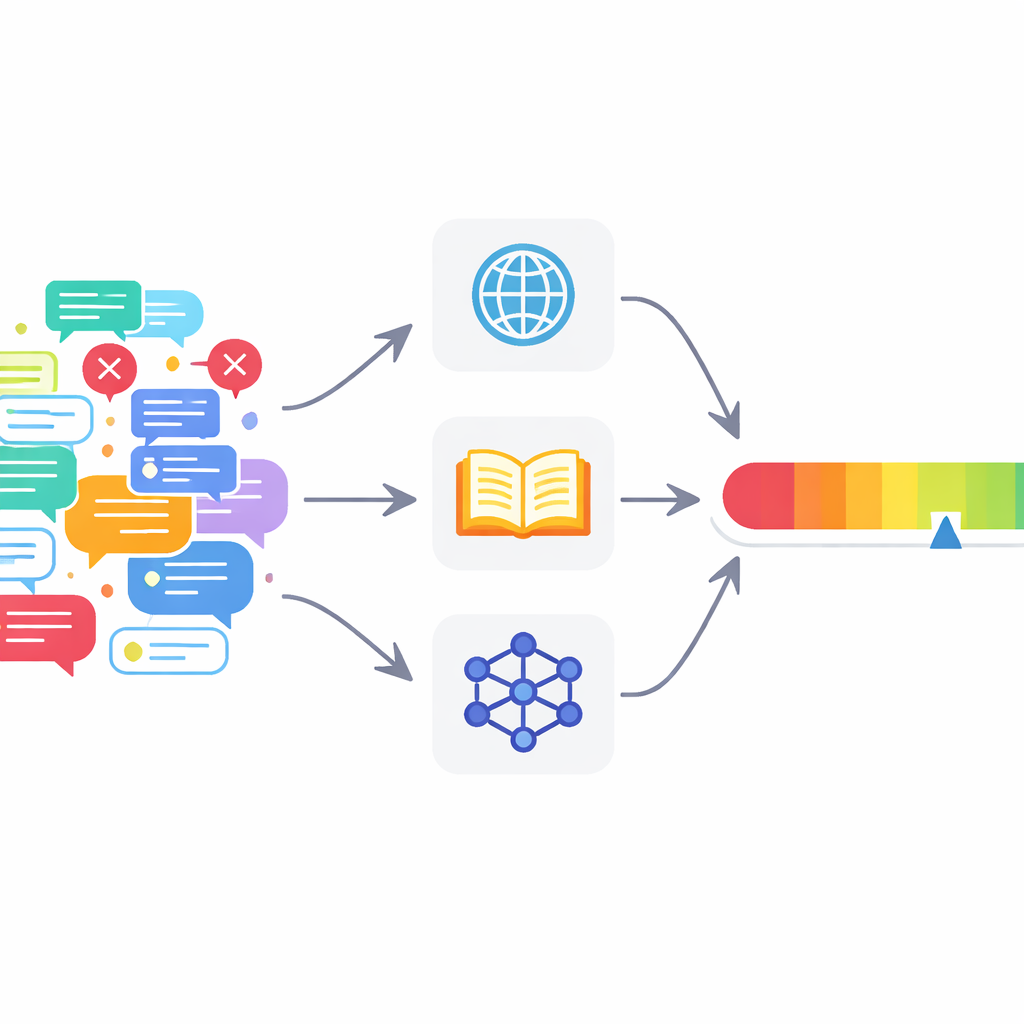
Wiele obecnych narzędzi zawodzi
Automatyczna weryfikacja faktów rozwijała się szybko wraz z rozwojem dużych modeli językowych, systemów AI stojących za nowoczesnymi chatbotami. Większość istniejących systemów skupia się na prostym wybieraniu: prawda czy fałsz? Często polegają na pojedynczym źródle informacji, a niekiedy tylko na wiedzy samego modelu językowego. Powoduje to dwa problemy w rzeczywistych dyskusjach online. Po pierwsze, modele językowe mają skłonność do nadmiernej pewności siebie i brzmią przekonująco nawet gdy się mylą. Po drugie, wpisy w sieci często mieszają poprawne i błędne stwierdzenia, więc jednowymiarowa etykieta prawda/fałsz dla całego tekstu jest zbyt grubą miarą, by była użyteczna.
Wiele cyfrowych weryfikatorów zamiast jednego
Aby sprostać tym problemom, autorzy proponują ramy wieloagentowej weryfikacji faktów (MAFC). Zamiast jednego wszechwiedzącego sprawdzacza system uruchamia kilku agentów, z których każdy korzysta z innego źródła informacji. Jeden agent przeszukuje sieć, inny odpyta Wikipedię, a trzeci użyje modelu AI do generowania i porównywania alternatywnych odpowiedzi — techniki zaczerpniętej z badań nad wykrywaniem halucynacji. Tekst poddawany weryfikacji jest najpierw dzielony na pojedyncze twierdzenia faktyczne. Każdy agent bada każde twierdzenie, ocenia, czy wydaje się ono prawdziwe, czy fałszywe, i przypisuje ocenie pewności wartość między 0 a 1, odzwierciedlającą siłę swojego przekonania.
Przekształcanie rozproszonych opinii w jedną ocenę
Rdzeniem artykułu jest nowy mechanizm punktowania, który zamienia rozproszone opinie agentów w przejrzystą miarę wiarygodności. Dla każdego twierdzenia system konwertuje oceny „prawda” na liczby dodatnie, a „fałsz” na ujemne, a następnie skaluje je według pewności każdego agenta. Uwzględnia też liczbę zgadzających się agentów, ale w sposób kontrolowany: zgoda kolejnych agentów pomaga, jednak każdy następny głos dodaje nieco mniej niż poprzedni. Zapobiega to sytuacji, w której duża grupa słabych, niepewnych agentów zdominuje mniejszą liczbę bardzo pewnych głosów. Wynikiem jest ocena na poziomie pojedynczego twierdzenia w przedziale 0–1. Oceny wszystkich twierdzeń w tekście są następnie uśredniane, by wyprowadzić ocenę wiarygodności całego tekstu, którą można interpretować jako „w pełni prawdziwe”, „częściowo prawdziwe” lub „fałszywe”.
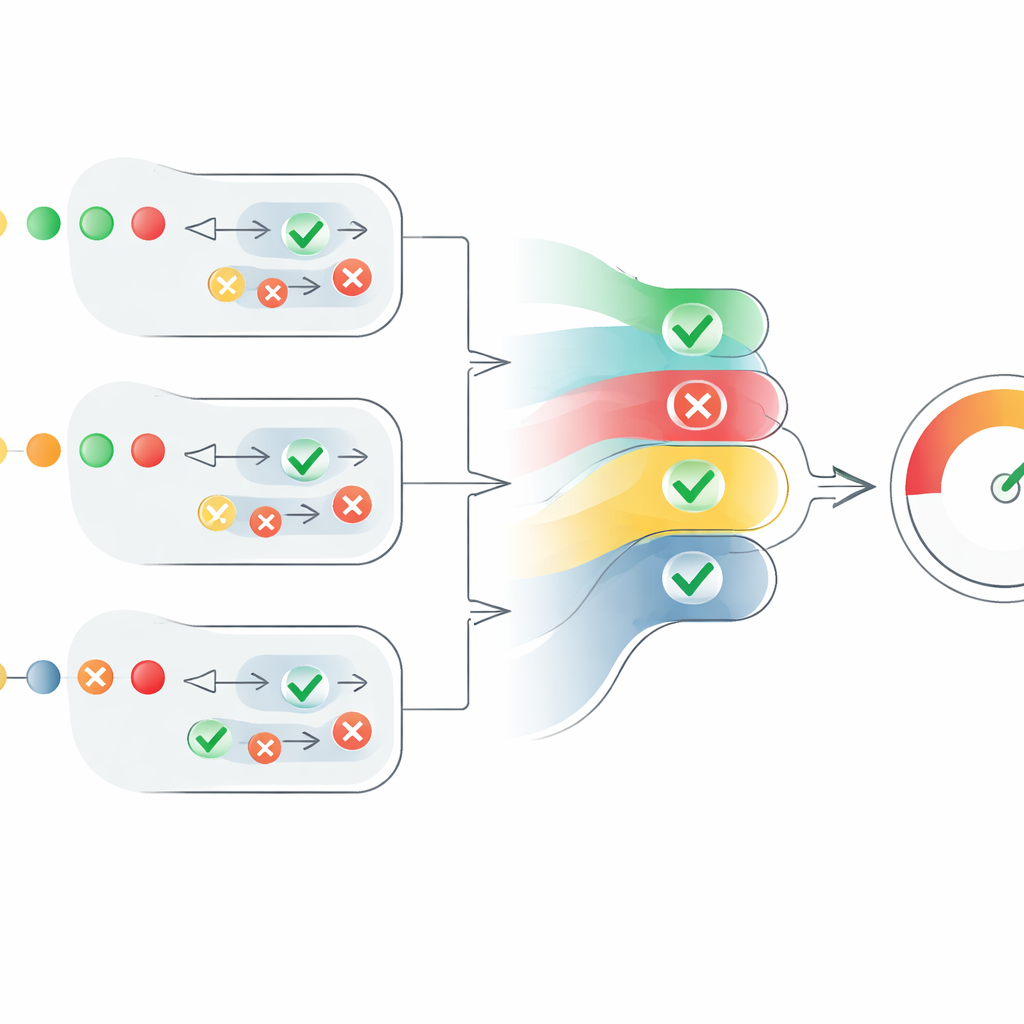
Testowanie ram w praktyce
Naukowcy ocenili MAFC na uznanych zestawach danych zawierających krótkie twierdzenia i skonstruowane teksty. Wykorzystali SciFact, który zawiera stwierdzenia naukowe oznaczone jako poparte lub obalone przez artykuły badawcze, oraz FEVER, dużą kolekcję twierdzeń opartych na treściach z Wikipedii. Stworzyli też nowy zestaw danych SciFact‑Mixed, w którym krótkie teksty powstają przez łączenie kilku twierdzeń, które mogą być wszystkie prawdziwe, wszystkie nieprawdziwe lub mieszane. Wydajność MAFC porównano z silną pojedynczą bazową metodą oraz z prostszymi sposobami łączenia wyników wielu agentów, takimi jak proste średnie czy sumowanie ocen.
Co pokazują wyniki
W tych eksperymentach system wieloagentowy z nową regułą punktowania konsekwentnie przewyższał alternatywy. Był dokładniejszy niż pojedynczy AI‑oparty weryfikator w rozstrzyganiu, czy twierdzenie jest prawdziwe czy fałszywe, i szczególnie skuteczny w rozpoznawaniu tekstów częściowo prawdziwych, mieszających dokładne i wprowadzające w błąd stwierdzenia. Na zbiorze FEVER MAFC osiągnął dokładność porównywalną z najlepszymi systemami konkursowymi specjalnie trenowanymi na tych danych, mimo że MAFC działał bez takiego treningu. Autorzy zauważają, że ich ramy mają nadal ograniczenia, np. polegają na tym samym bazowym modelu AI dla wszystkich agentów i mają trudności z twierdzeniami zależnymi od czasu, ale twierdzą, że oferują solidną i przejrzystą podstawę dla bogatszej, wielopoziomowej weryfikacji faktów.
Co to oznacza dla codziennych czytelników
Dla osoby próbującej odnaleźć się w hałaśliwym krajobrazie informacji, ta praca wskazuje drogę do narzędzi, które robią więcej niż tylko oznaczanie wpisów jako po prostu prawdziwe lub fałszywe. Dzięki czerpaniu dowodów z kilku źródeł i ważeniu ich zgodności oraz pewności w sposób zasadny, ramy MAFC mogą oszacować, na ile dany tekst jest ogólnie wiarygodny, i wskazać, kiedy jest tylko częściowo rzetelny. Choć to wciąż prototyp badawczy, tego typu system w przyszłości mógłby pomóc czytelnikom, moderatorom i platformom dyskusyjnym lepiej zrozumieć, gdzie informacja plasuje się na skali od solidnego faktu do wątpliwej plotki.
Cytowanie: Dong, Y., Ito, T. Multi-agent systems and credibility-based advanced scoring mechanism in fact-checking. Sci Rep 16, 11814 (2026). https://doi.org/10.1038/s41598-026-41862-z
Słowa kluczowe: dezinformacja, weryfikacja faktów, duże modele językowe, systemy wieloagentowe, ocena wiarygodności