Clear Sky Science · de
Multi-Agent-Systeme und glaubwürdigkeitsbasierter erweiteter Bewertungsmechanismus im Fact‑Checking
Warum das Überprüfen von Online‑Behauptungen wirklich wichtig ist
Jeden Tag bombardieren uns soziale Netzwerke und Nachrichtenfeeds mit Behauptungen zu Wissenschaft, Politik und Gesundheit. Einige sind richtig, andere irreführend, und wieder andere mischen Wahrheit und Falschheit auf subtile Weise. Dieses Papier stellt einen neuen Weg vor, die Vertrauenswürdigkeit solcher Texte zu bewerten, indem mehrere digitale „Fact‑Checker“ gemeinsam arbeiten und ihre Einschätzungen dann sorgfältig zu einer einzigen Glaubwürdigkeitsbewertung kombiniert werden.
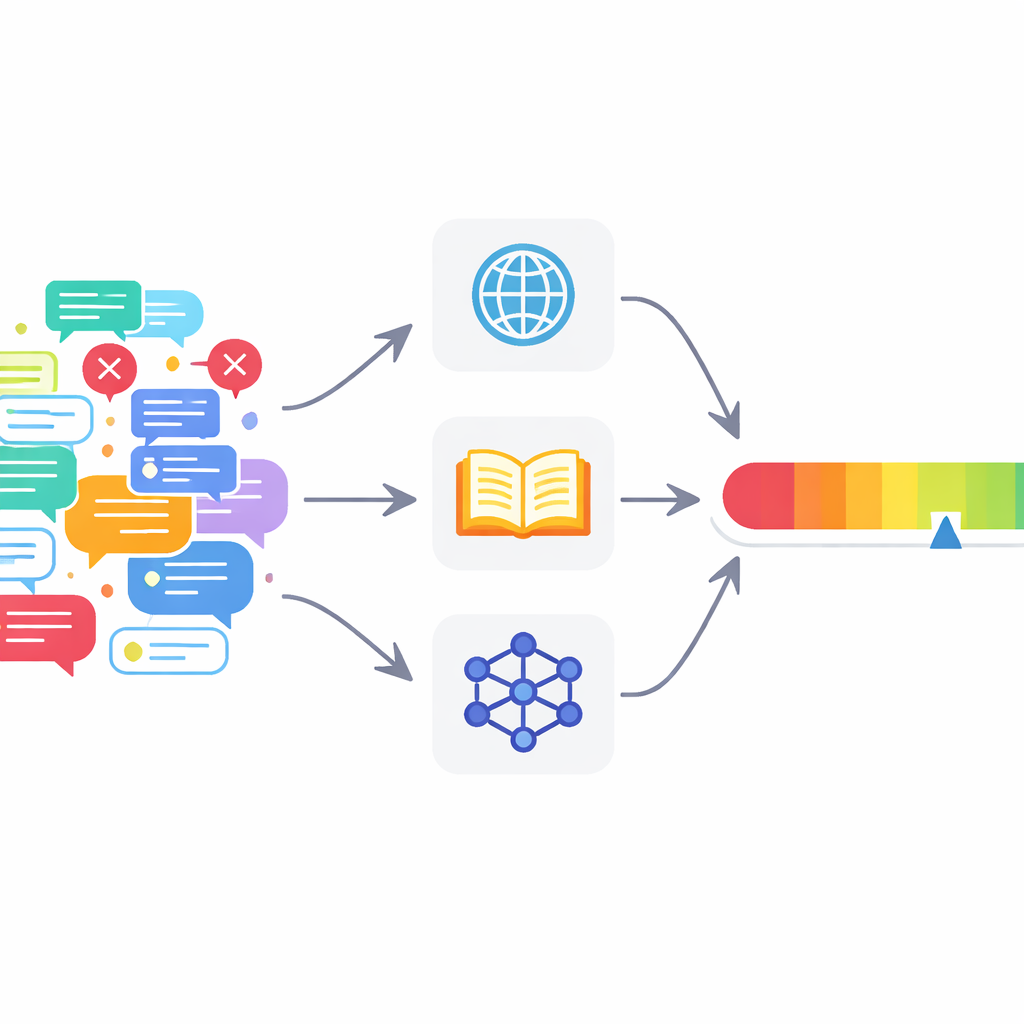
Viele aktuelle Werkzeuge sind unzureichend
Automatisiertes Fact‑Checking ist parallel zu den großen Sprachmodellen, den KI‑Systemen hinter modernen Chatbots, schnell gewachsen. Die meisten bestehenden Systeme konzentrieren sich auf eine einfache Ja‑oder‑Nein‑Entscheidung: Ist eine Behauptung wahr oder falsch? Häufig stützen sie sich auf eine einzige Informationsquelle oder sogar nur auf das Wissen des Sprachmodells selbst. Das führt in realen Online‑Diskussionen zu zwei Problemen. Erstens neigen Sprachmodelle dazu, übermäßig selbstsicher zu wirken und sicher zu klingen, auch wenn sie falsch liegen. Zweitens mischen echte Beiträge oft richtige und falsche Aussagen, sodass ein einzelnes Wahr/Falsch‑Label für den gesamten Text zu grob ist, um nützlich zu sein.
Viele digitale Fact‑Checker statt einem
Um diese Probleme anzugehen, schlagen die Autorinnen und Autoren ein Multi‑Agenten‑Fact‑Checking‑Framework (MAFC) vor. Statt eines allwissenden Prüfers setzt das System mehrere Agenten ein, die jeweils auf unterschiedlichen Informationsquellen beruhen. Ein Agent durchsucht das Web, ein anderer fragt Wikipedia ab und ein dritter nutzt ein KI‑Modell, um alternative Antworten zu generieren und zu vergleichen — eine Technik, die aus der Forschung zur Erkennung von Halluzinationen adaptiert ist. Der zu überprüfende Text wird zunächst in einzelne faktische Behauptungen zerlegt. Jeder Agent untersucht jede Behauptung, entscheidet, ob sie offenbar wahr oder falsch ist, und liefert eine Vertrauensbewertung zwischen 0 und 1, die widerspiegelt, wie stark er an seine eigene Einschätzung glaubt.
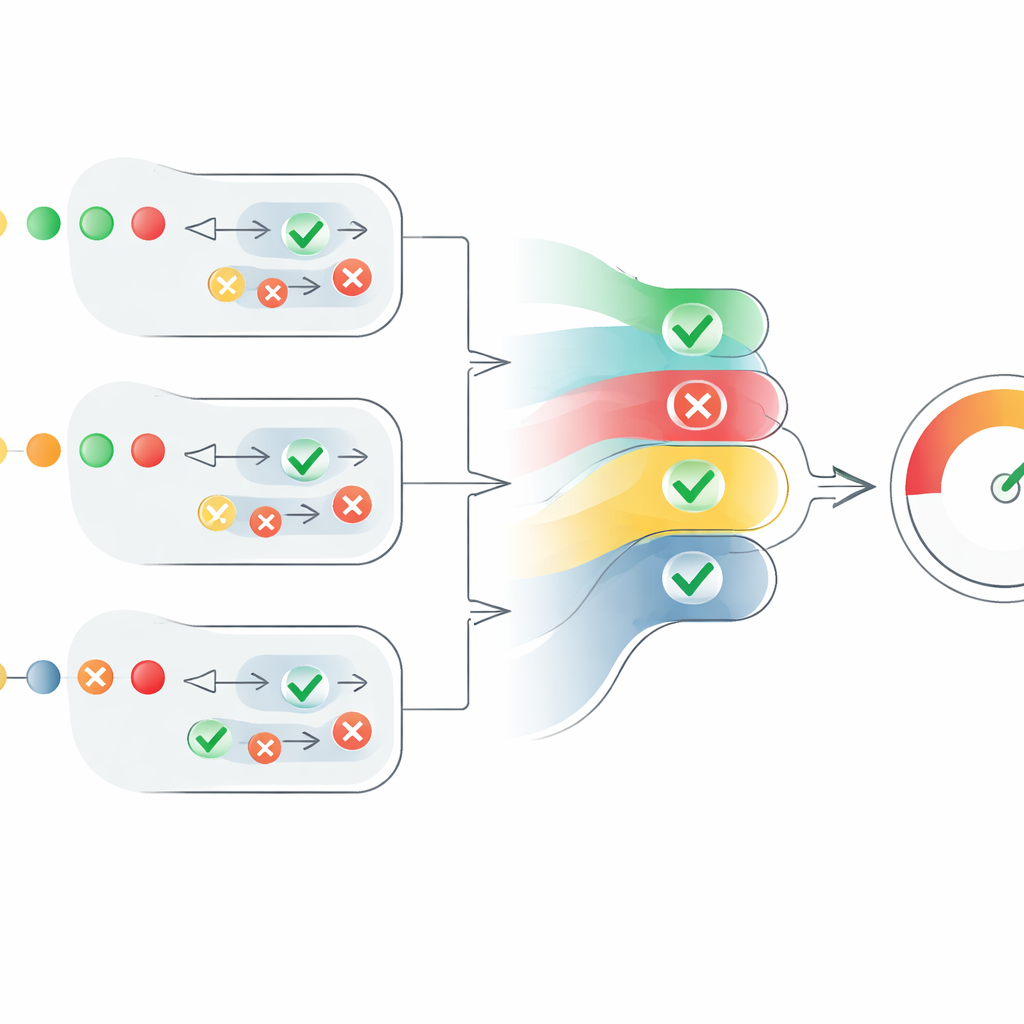
Geteilter Meinungen in eine einzige Bewertung überführen
Das Kernstück des Papiers ist ein neuer Bewertungsmechanismus, der diese verstreuten Agenten‑Einschätzungen in ein klares Glaubwürdigkeitsmaß überführt. Für jede Behauptung wandelt das System „wahr“‑Urteile in positive Zahlen und „falsch“‑Urteile in negative um und skaliert sie mit der jeweiligen Vertrauensbewertung des Agenten. Es berücksichtigt außerdem, wie viele Agenten übereinstimmen, jedoch auf kontrollierte Weise: Übereinstimmung zusätzlicher Agenten unterstützt das Ergebnis, doch jede zusätzliche Stimme trägt etwas weniger bei als die vorherige. Das verhindert, dass eine große Gruppe schwacher, unsicherer Agenten eine kleinere Zahl hochgradig zuversichtlicher Agenten überstimmt. Das Ergebnis ist eine behauptungsbezogene Bewertung zwischen 0 und 1. Die Bewertungen aller Behauptungen in einem Text werden dann gemittelt, um eine Text‑Ebene‑Glaubwürdigkeitsbewertung zu erzeugen, die als „vollständig wahr“, „teilweise wahr“ oder „falsch“ interpretiert werden kann.
Das Framework auf die Probe stellen
Die Forschenden evaluierten MAFC an etablierten Datensätzen mit kurzen Behauptungen und konstruierten Texten. Sie nutzten SciFact, das wissenschaftliche Aussagen enthält, die durch Forschungsarbeiten als gestützt oder widerlegt gekennzeichnet sind, sowie FEVER, eine große Sammlung von Behauptungen, die aus Wikipedia aufgebaut wurde. Zusätzlich erstellten sie einen neuen Datensatz, SciFact‑Mixed, in dem kurze Texte durch die Kombination mehrerer Behauptungen gebildet werden, die entweder alle korrekt, alle inkorrekt oder gemischt sein können. Die Leistung von MAFC wurde mit einer starken Einzel‑Agent‑Baseline und mit einfacheren Möglichkeiten zur Kombination mehrerer Agenten verglichen, etwa einfachem Mittelwertbilden oder Summieren ihrer Bewertungen.
Was die Ergebnisse zeigen
In diesen Experimenten übertraf das Multi‑Agenten‑System mit der neuen Bewertungsregel konsistent die Alternativen. Es war genauer als der einzelne KI‑basierte Prüfer bei der Entscheidung, ob eine Behauptung wahr oder falsch ist, und zeigte besondere Stärke darin, teilweise wahre Texte zu erkennen, die richtige und irreführende Aussagen mischen. Im FEVER‑Datensatz erreichte MAFC eine Genauigkeit, die mit den besten Wettbewerbssystemen vergleichbar war, die speziell auf diese Daten trainiert worden waren, obwohl MAFC ohne ein solches Training arbeitete. Die Autorinnen und Autoren weisen darauf hin, dass ihr Framework weiterhin Einschränkungen hat, etwa die Nutzung desselben zugrundeliegenden KI‑Modells für alle Agenten und Schwierigkeiten mit zeitlich sensiblen Behauptungen, aber sie argumentieren, dass es eine solide und transparente Grundlage für reichhaltigeres, mehrstufiges Fact‑Checking bietet.
Was das für Alltagsleserinnen und ‑leser bedeutet
Für jemanden, der sich in einer lauten Informationslandschaft zurechtfinden möchte, deutet diese Arbeit auf Werkzeuge hin, die mehr leisten als Beiträge einfach als wahr oder falsch zu stempeln. Indem sie Belege aus mehreren Quellen ziehen und deren Übereinstimmung und Vertrauen auf prinzipielle Weise gewichten, kann das MAFC‑Framework abschätzen, wie vertrauenswürdig ein Text insgesamt ist, und hervorheben, wann er nur teilweise zuverlässig ist. Zwar ist es noch ein Forschungsprototyp, doch eine solche Lösung könnte langfristig Leserinnen und Lesern, Moderatorinnen und Moderatoren sowie Diskussionsplattformen besser helfen zu verstehen, wo Informationen auf dem Spektrum von gesichertem Fakt bis hin zu fragwürdigem Gerücht stehen.
Zitation: Dong, Y., Ito, T. Multi-agent systems and credibility-based advanced scoring mechanism in fact-checking. Sci Rep 16, 11814 (2026). https://doi.org/10.1038/s41598-026-41862-z
Schlüsselwörter: Fehlinformationen, Fact‑Checking, große Sprachmodelle, Multi‑Agenten‑Systeme, Glaubwürdigkeitsbewertung