Clear Sky Science · zh
一种结合生成式与跨语元学习的联合跨度实体预测方法,用于低资源日语命名实体识别
教计算机识别日语文本中的名字
在线信息充斥着人名、地名、公司名和日期等实体,能够自动找出这些“谁、哪里、何时”线索的软件对于搜索引擎、金融、医学等领域至关重要。但与英文拥有大量训练数据不同,日语带来特殊挑战:文本中没有单词间的空格且书写形式复杂。本研究提出了一种新方法,称为 MAML‑ProtoNet++,可以在只有少量标注样本时仍帮助计算机学习识别日语中的命名实体。
为什么日语尤其棘手
在许多欧洲语言中,空格将单词分开,因此算法更容易判断词的边界。而日语句子通常以连续字符流书写。实体可能很长、由多个部分组成,并且会根据上下文变化形式。传统神经网络,即便是强大的多语模型,也难以确定实体的起止位置和类别,而且高度依赖大规模标注数据,而日语的此类数据稀缺。因此现有系统常常将一个组织名拆成两部分、忽略句子中的长程关系,或是从以英语为主的训练中迁移到日语时效果不佳。
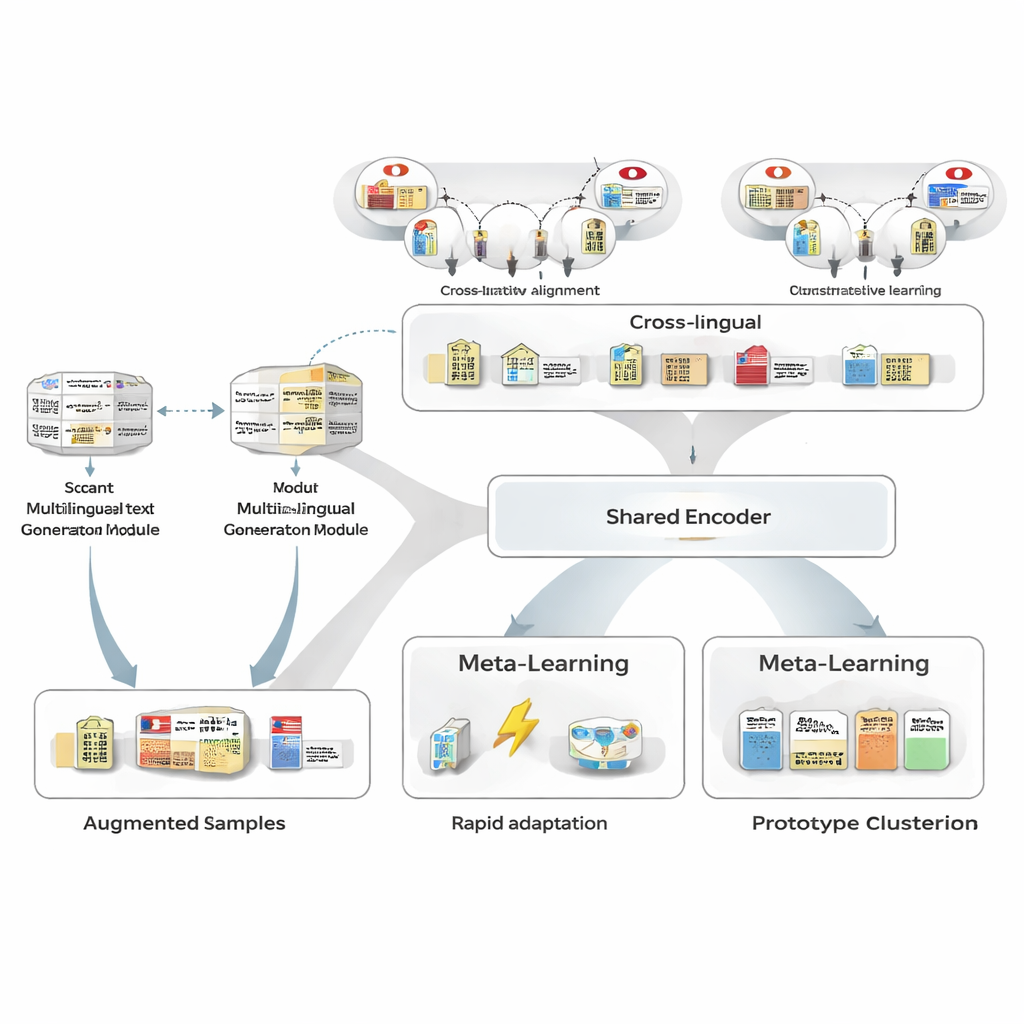
在不增加人工标注的情况下生成更多示例
为克服训练数据不足,作者首先使用多语文本生成器改写少量已标注的日语句子。生成器产生保留相同实体与类别但措辞不同的新版本:改写句子、用相似实体替换实体提及或改变上下文。之后一个精心设计的过滤管道用三项测试去除不良重写:来自独立标注器的置信度检查、实体边界与类别是否仍与原句匹配的检查,以及避免近似重复的语义相似性测试。存活下来的合成句子拓宽了模型看到的模式范围,在保持标签噪声极低的同时提升了鲁棒性。
跨语言借力
接着,该框架借助大型知识库学习将日语实体与其他语言的对应项对齐。诸如日语和中文的“东京都政府”之类的实体对被映射到共享的数学空间,使得匹配实体靠得更近、无关实体相互远离。这种对比式预训练并不旨在编码全部领域知识;它为模型提供了一个语言无关的骨干,使得相似概念在不同语言中表现相似。在后续的任务特定训练中,日语的监督可以重塑该空间,但跨语先验使得从少量示例泛化更容易,并将日英实体对的相似度从中等提升到很高的水平。
学会从极少样本中学习
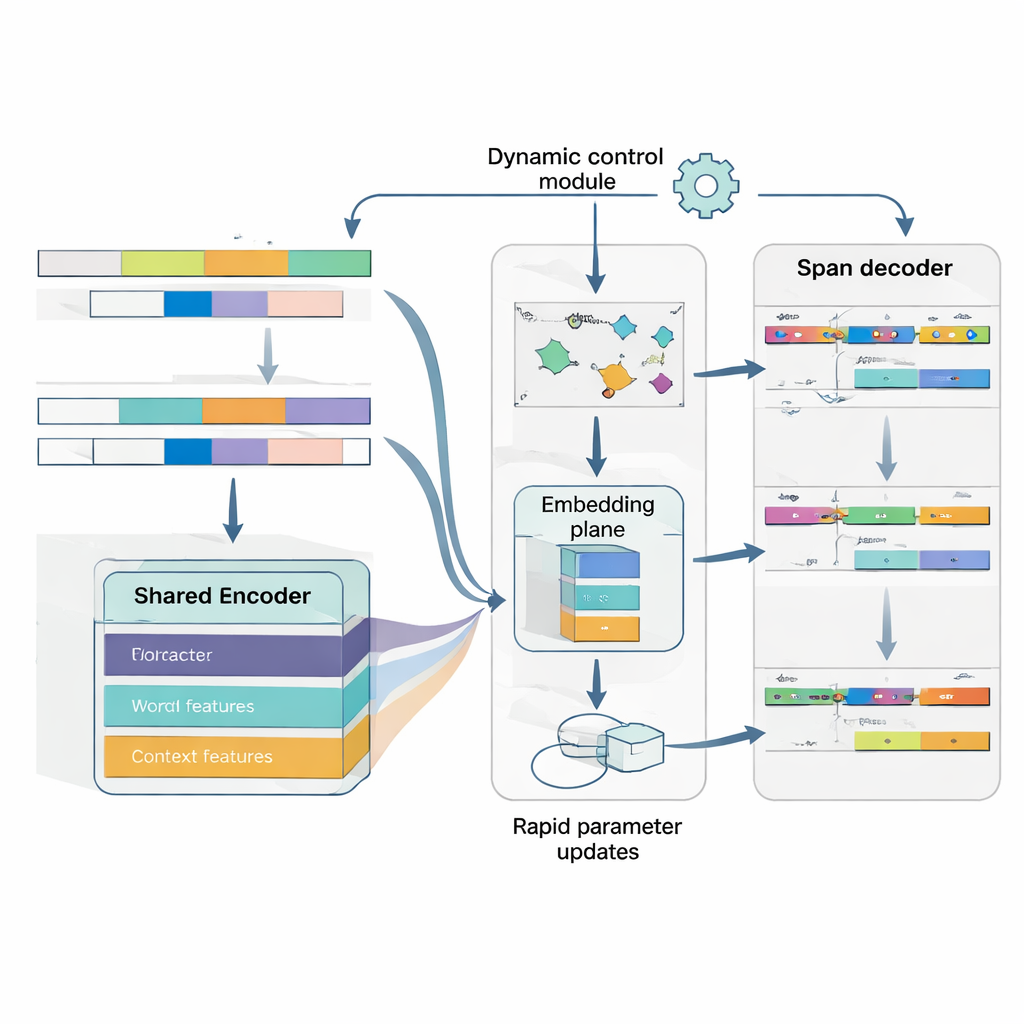
MAML‑ProtoNet++ 的核心是一种“学会学习”的策略。模型不是在一个巨大的数据集上训练一次,而是在许多小任务上反复练习,这些任务模拟真实的少样本场景:在给定少量标注句子和一个小测试集的情况下快速适应。该方法结合了两种著名思想。一是快速适应组件,通过少量梯度步更新模型参数,使其能针对每个新任务进行微调;二是基于原型(prototype)的组件,为每个实体类型构建代表性向量,并根据与这些原型的距离对新跨度进行分类。一个独立的控制网络根据任务看起来有多难(基于其少量标注样本)自动调整学习率、距离尺度以及在不同特征层次(字符、词或全文上下文)上应当信任多少。这种动态控制有助于系统在任务变化很大时仍然稳定且高效。
同时理解实体在哪儿以及它是什么
最后,模型将边界检测与类别分配视为一个统一的、协调的问题,而非两个独立步骤。它首先预测句子中实体可能的起始位置,然后在这些起始位置的条件下预测合理的结束位置,之后将所得跨度分类为实体类型。可以考虑多个重叠跨度,但评分规则偏好最连贯的那些。通过显式建模起始、结束与类别之间的依赖关系,系统能够更好地处理嵌套或模糊实体——这是日语中的常见难题。一个联合损失函数同时训练这三项决策,既提高了边界准确性也改善了最终标签质量。
结果在实践中意味着什么
在多个模拟每类仅有五个标注样本的日语基准测试上,MAML‑ProtoNet++ 优于强基线方法,包括标准微调、早期元学习方法和单独的对比训练。在最具挑战性的设置下,它在宏 F1 分数上约为 0.77,并在实体起止的精确定位上取得显著高的准确率。该方法还能够较好地迁移到新的领域,如生物医学和新闻文本,并不需要大量重新训练。对非专业读者而言,结论是:作者构建了一个紧凑且高效的系统,能够通过智能生成额外示例、借用跨语种提示并动态调整学习方式,从极少监督数据中学习识别日语文本中的人名和其他关键术语。
引用: Shao, X., Zhu, D., Liu, Q. et al. A joint span-entity prediction approach with generative and cross-lingual meta-learning for low-resource Japanese NER. Sci Rep 16, 10281 (2026). https://doi.org/10.1038/s41598-026-41621-0
关键词: 日语命名实体识别, 少样本学习, 跨语种自然语言处理, 元学习, 数据增强