Clear Sky Science · en
A joint span-entity prediction approach with generative and cross-lingual meta-learning for low-resource Japanese NER
Teaching Computers to Spot Names in Japanese Text
Online information is full of names of people, places, companies, and dates, and software that can automatically find these “who, where, and when” clues is vital for search engines, finance, medicine, and more. But while English has abundant data to train such systems, Japanese poses a special challenge: it lacks spaces between words and has complex writing patterns. This study introduces a new method, called MAML‑ProtoNet++, that helps computers learn to recognize named entities in Japanese even when only a handful of labeled examples are available.
Why Japanese Is Especially Tricky
In many European languages, spaces separate words, so algorithms can more easily guess where one term ends and another begins. Japanese sentences, however, are written as continuous streams of characters. Names can be long, built from multiple parts, and change form depending on context. Traditional neural networks, even powerful multilingual models, struggle to decide where an entity starts and ends and what type it is. They also rely heavily on large labeled datasets, which are scarce for Japanese. As a result, existing systems often split a single organization into two pieces, miss long-range relationships in a sentence, or transfer poorly from English-based training to Japanese text.
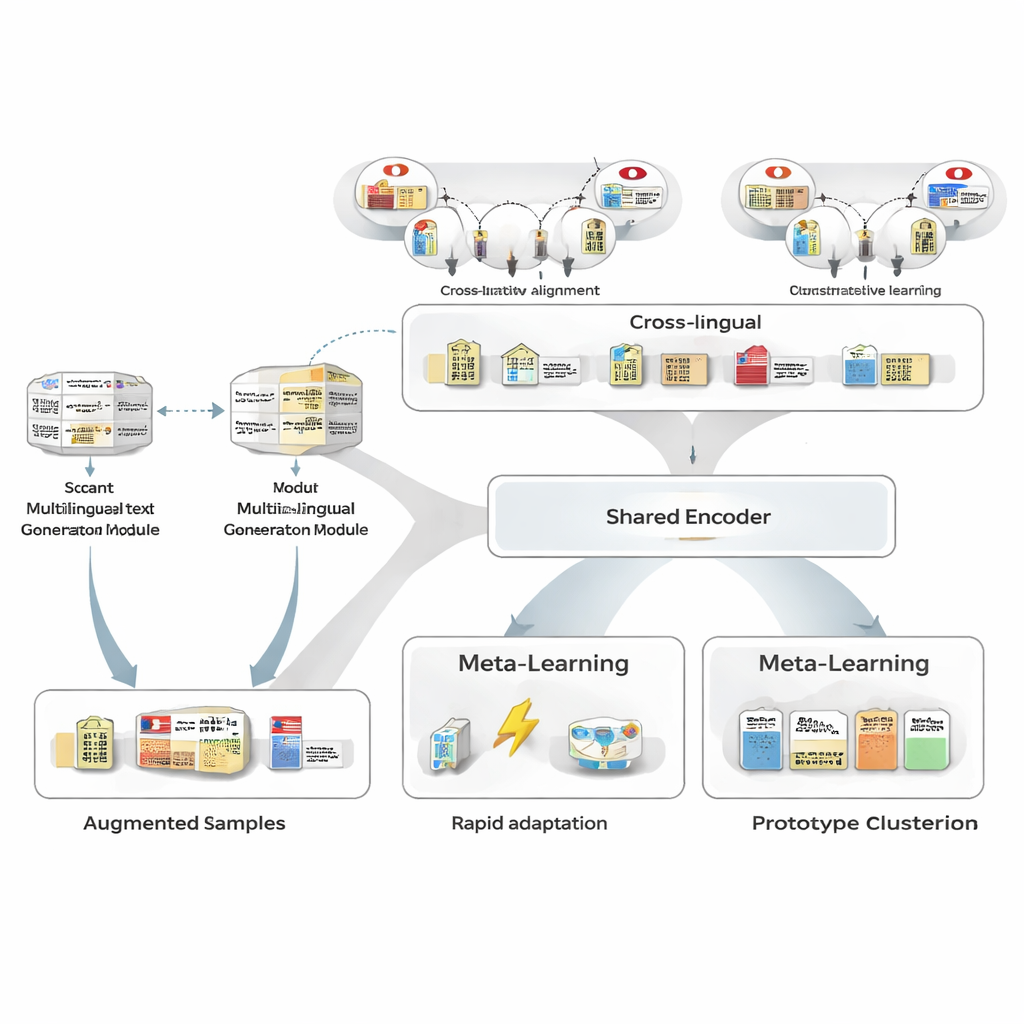
Making More Examples Without More Human Labels
To overcome the lack of training data, the authors first use a multilingual text generator to rewrite the few annotated Japanese sentences they do have. The generator produces new versions that keep the same entities and types but vary the wording: rephrasing sentences, swapping entity mentions with similar ones, or changing surrounding context. A careful filtering pipeline then weeds out bad rewrites using three tests: a confidence check from a separate tagger, a check that entity boundaries and types still match the original, and a semantic similarity test that avoids near-duplicates. The surviving synthetic sentences widen the range of patterns the model sees, improving robustness while keeping label noise very low.
Borrowing Strength Across Languages
Next, the framework learns to align Japanese entities with their counterparts in other languages using a large knowledge base. Pairs such as “Tokyo Metropolitan Government” in Japanese and in Chinese are mapped into a shared mathematical space so that matching entities land close together and unrelated ones are pushed apart. This contrastive pretraining does not try to encode all domain knowledge; instead, it gives the model a language-agnostic backbone so that similar concepts look similar regardless of language. Later, during task-specific training, Japanese supervision can reshape this space, but the cross-lingual prior makes it easier to generalize from few examples and improves the similarity between Japanese–English entity pairs from moderate to very high levels.
Learning How to Learn From Only a Few Examples
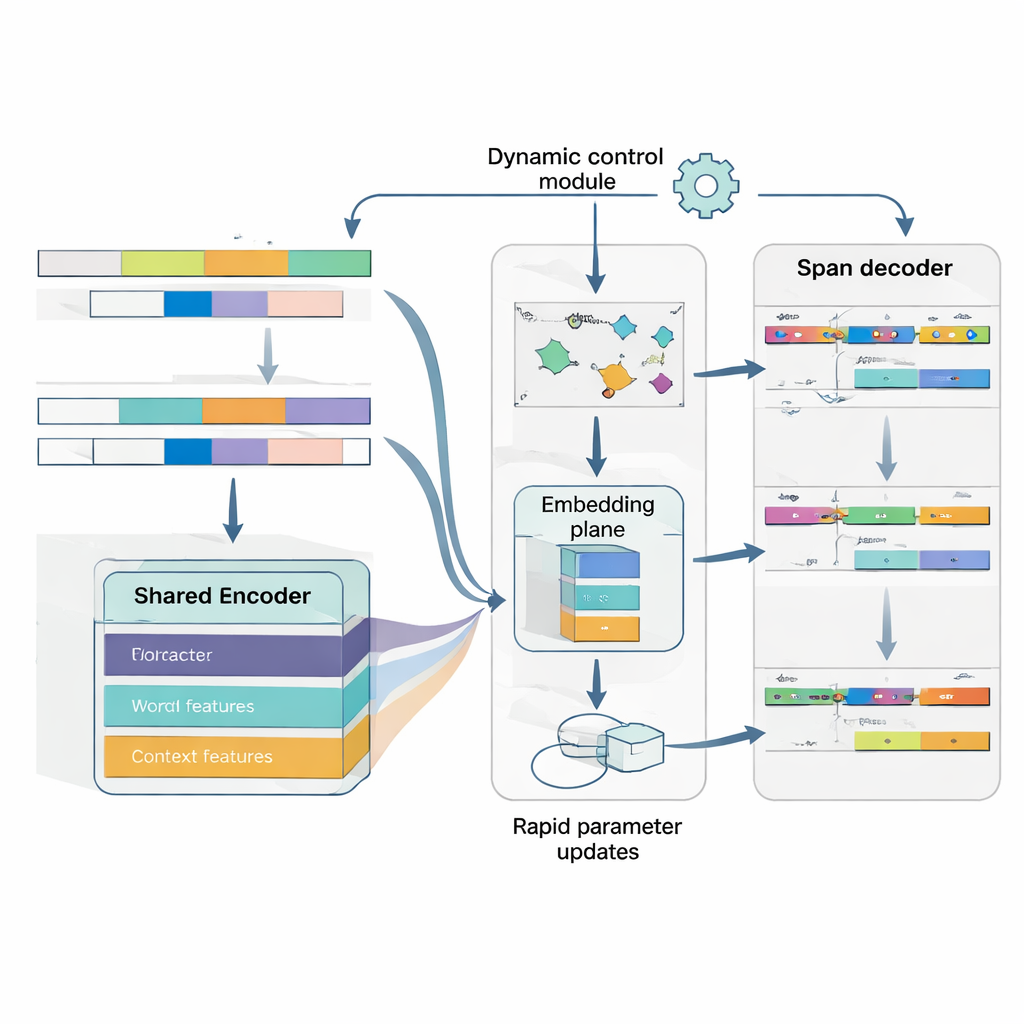
The heart of MAML‑ProtoNet++ is a “learning to learn” strategy. Rather than train once on a huge dataset, the model practices on many tiny tasks that mimic real few-shot scenarios: given a handful of labeled sentences and a small test set, adapt quickly. Two well-known ideas are combined. One, a rapid adaptation component, adjusts model parameters with a few gradient steps so it can tune itself to each new task. Two, a prototype-based component builds a representative vector for each entity type and classifies new spans by distance to these prototypes. A separate control network looks at how hard a task appears—based on its few labeled examples—and then automatically tweaks learning rates, distance scales, and how much to trust different feature levels (characters, words, or full context). This dynamic control helps the system remain stable and effective even when tasks vary widely.
Understanding Both Where an Entity Is and What It Is
Finally, the model treats boundary detection and type assignment as a single, coordinated problem rather than two separate steps. It first predicts likely start positions for entities in a sentence, then, conditioned on those starts, predicts plausible end positions, and then classifies the resulting spans into entity types. Multiple overlapping spans can be considered, but scoring rules favor the most coherent ones. By explicitly modeling the dependency between start, end, and category, the system becomes better at handling nested or ambiguous entities—a common obstacle in Japanese. A joint loss function trains all three decisions together, improving both boundary accuracy and final labels.
What the Results Mean in Practice
When tested on several Japanese benchmarks that simulate having only five labeled examples per entity type, MAML‑ProtoNet++ outperforms strong baselines, including standard fine-tuning, earlier meta-learning methods, and contrastive training alone. It reaches a macro F1 score of about 0.77 in the most challenging setting and achieves notably high accuracy on the exact start and end of entities. The approach also transfers well to new domains, such as biomedical and news text, without major retraining. For a lay reader, the takeaway is that the authors have built a compact, efficient system that can learn to pick out names and other key terms in Japanese text from very little guidance, by smartly generating extra examples, borrowing cross-language hints, and adjusting how it learns on the fly.
Citation: Shao, X., Zhu, D., Liu, Q. et al. A joint span-entity prediction approach with generative and cross-lingual meta-learning for low-resource Japanese NER. Sci Rep 16, 10281 (2026). https://doi.org/10.1038/s41598-026-41621-0
Keywords: Japanese named entity recognition, few-shot learning, cross-lingual NLP, meta-learning, data augmentation