Clear Sky Science · pl
Wspólne podejście do przewidywania przedziałów i encji z generatywnym i międzyjęzykowym meta-uczeniem dla japońskiego NER o niskich zasobach
Nauczanie komputerów wykrywania nazw w tekście japońskim
Informacje dostępne online obfitują w nazwy osób, miejsc, firm oraz dat, a oprogramowanie potrafiące automatycznie odnajdywać te „kto, gdzie i kiedy” jest kluczowe dla wyszukiwarek, finansów, medycyny i innych zastosowań. Podczas gdy angielski dysponuje obfitymi danymi do trenowania takich systemów, japoński stawia szczególne wyzwania: brak spacji między wyrazami i złożone systemy zapisu. W tym badaniu przedstawiono nową metodę nazwaną MAML‑ProtoNet++, która pomaga komputerom rozpoznawać nazwy własne w języku japońskim nawet przy zaledwie kilku oznaczonych przykładach.
Dlaczego japoński jest szczególnie trudny
W wielu językach europejskich spacje oddzielają wyrazy, więc algorytmy łatwiej określają granice terminów. Zdania japońskie są jednak zapisywane jako ciąg znaków. Nazwy mogą być długie, złożone z kilku części i zmieniać formę w zależności od kontekstu. Tradycyjne sieci neuronowe, nawet silne modele wielojęzyczne, mają problem z ustaleniem, gdzie encja się zaczyna i kończy oraz jakiego jest typu. Polegają też w dużym stopniu na dużych, oznaczonych zbiorach danych, których brakuje dla japońskiego. W efekcie istniejące systemy często dzielą jedną organizację na dwa fragmenty, pomijają długodystansowe zależności w zdaniu lub słabo transferują wiedzę z treningu opartego na angielskim na tekst japoński.
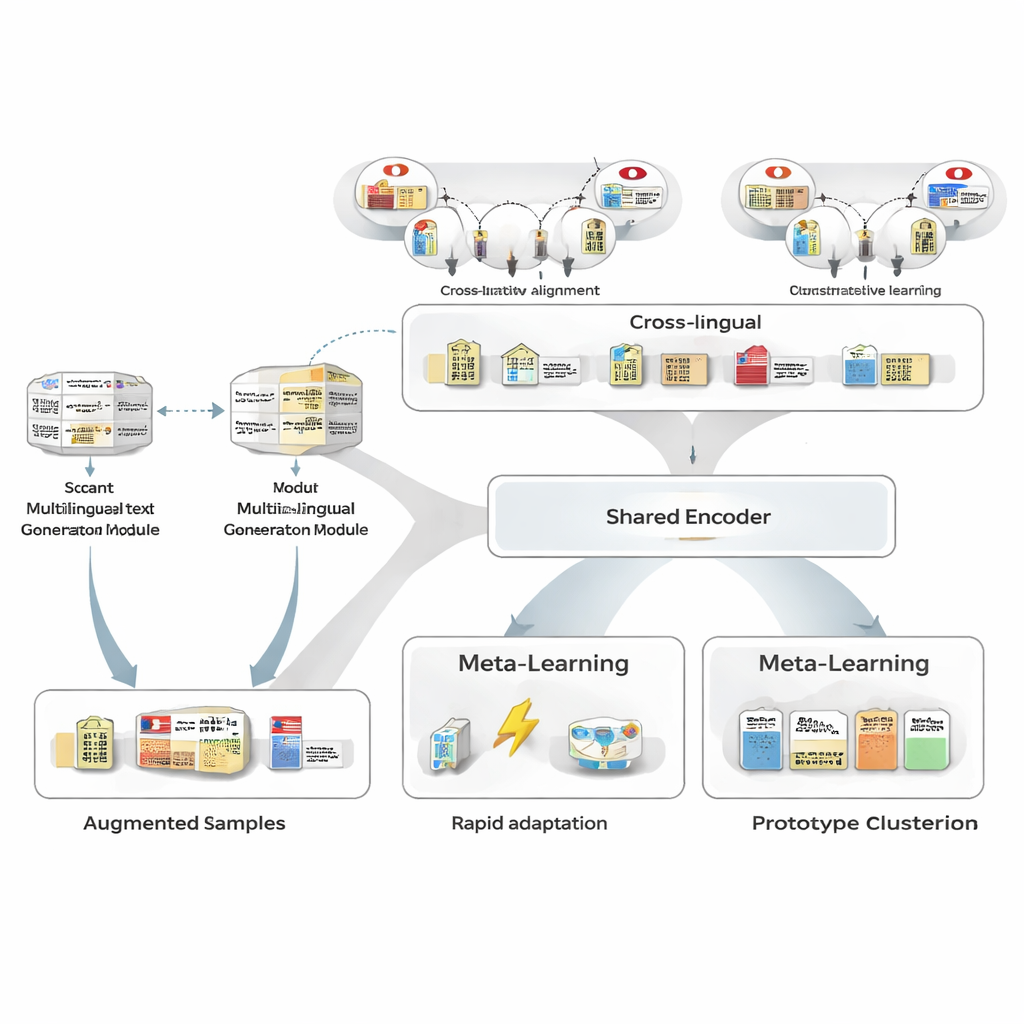
Tworzenie większej liczby przykładów bez nowych etykiet od ludzi
Aby przezwyciężyć brak danych treningowych, autorzy najpierw używają wielojęzycznego generatora tekstu do przepisania kilku oznaczonych zdań japońskich, które mają. Generator tworzy nowe wersje zachowujące te same encje i typy, ale różniące się sformułowaniem: parafrazując zdania, zamieniając wzmianki encji na podobne lub zmieniając otaczający kontekst. Staranny proces filtrowania usuwa złe przepisy za pomocą trzech testów: sprawdzenia pewności innego taggera, kontrolowania, czy granice encji i typy nadal zgadzają się z oryginałem, oraz testu podobieństwa semantycznego, który unika niemalże duplikatów. Pozostałe syntetyczne zdania poszerzają zakres wzorców widzianych przez model, poprawiając odporność przy jednoczesnym utrzymaniu bardzo niskiego poziomu szumu etykiet.
Wzmacnianie siły poprzez języki
Następnie ramy uczą wyrównywać encje japońskie z odpowiednikami w innych językach, wykorzystując dużą bazę wiedzy. Pary takie jak „Tokyo Metropolitan Government” w japońskim i chińskim są mapowane do wspólnej przestrzeni matematycznej tak, aby dopasowane encje znalazły się blisko siebie, a niepowiązane zostały od siebie oddalone. To pretrenowanie kontrastowe nie próbuje zakodować całej wiedzy dziedzinowej; zamiast tego daje modelowi niezależny od języka rdzeń, dzięki czemu podobne pojęcia wyglądają podobnie niezależnie od języka. Później, podczas treningu specyficznego dla zadania, nadzór japoński może przeorganizować tę przestrzeń, ale międzyjęzykowy priorytet ułatwia generalizację z kilku przykładów i podnosi podobieństwo par encji japońsko‑angielskich z umiarkowanego do bardzo wysokiego.
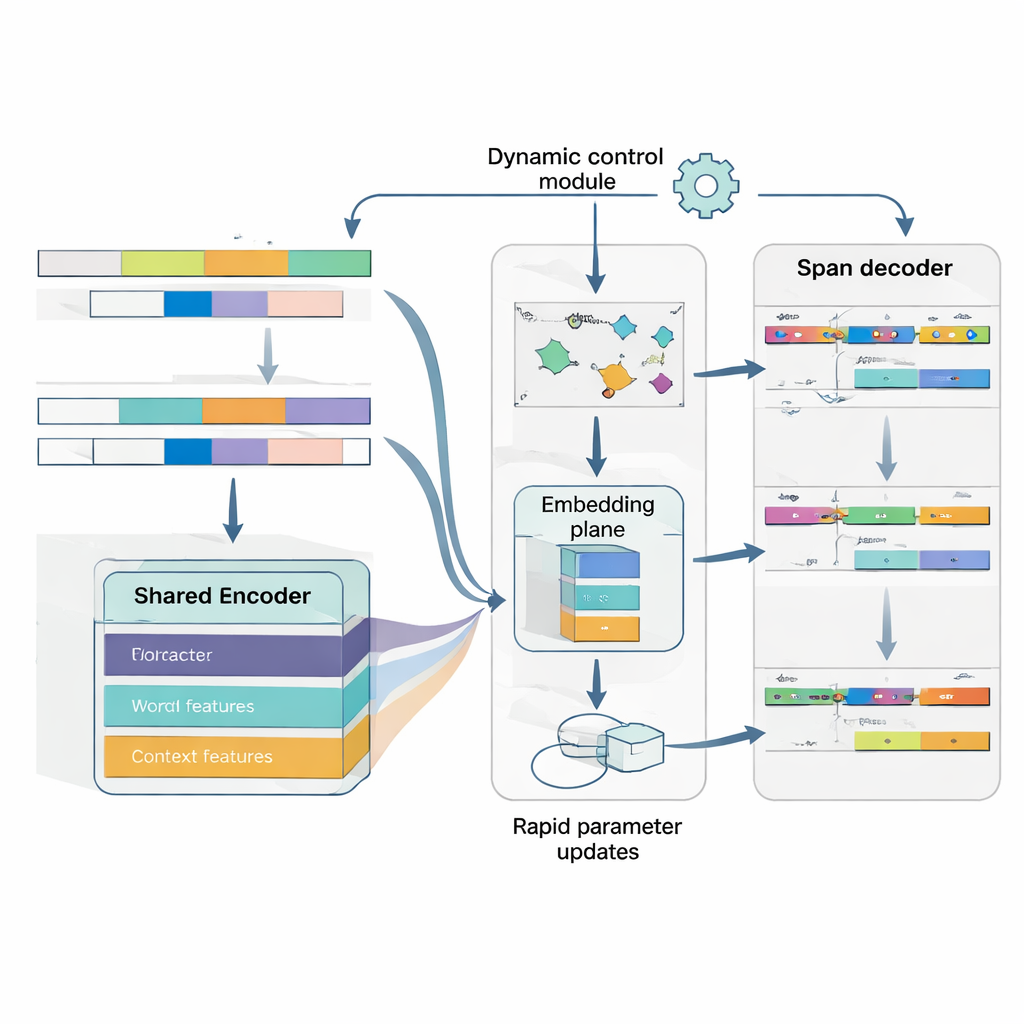
Nauka jak uczyć się z zaledwie kilku przykładów
Rdzeń MAML‑ProtoNet++ to strategia „uczenia się, jak się uczyć”. Zamiast trenować raz na ogromnym zbiorze, model ćwiczy się na wielu maleńkich zadaniach, które naśladują rzeczywiste scenariusze few‑shot: mając kilka oznaczonych zdań i niewielki zestaw testowy, adaptuje się szybko. Połączono tu dwie znane koncepcje. Po pierwsze, składnik szybkiej adaptacji dostosowuje parametry modelu kilkoma krokami gradientowymi, aby potrafił dopasować się do nowego zadania. Po drugie, składnik oparty na prototypach buduje reprezentatywny wektor dla każdego typu encji i klasyfikuje nowe przedziały na podstawie odległości od tych prototypów. Osobna sieć kontrolna ocenia, jak trudne wydaje się zadanie — na podstawie kilku oznaczonych przykładów — i automatycznie dostraja tempo uczenia, skale odległości oraz to, na ile ufać różnym poziomom cech (znakom, słowom czy pełnemu kontekstowi). Ta dynamiczna kontrola pomaga systemowi pozostać stabilnym i skutecznym, nawet jeśli zadania znacznie się różnią.
Rozumienie zarówno gdzie encja jest, jak i czym jest
Wreszcie model traktuje wykrywanie granic i przypisywanie typów jako jeden, skoordynowany problem, a nie dwa oddzielne kroki. Najpierw przewiduje prawdopodobne pozycje początkowe encji w zdaniu, następnie, warunkowo na tych startach, przewiduje możliwe pozycje końcowe, a potem klasyfikuje otrzymane przedziały do typów encji. Można rozważać wiele nakładających się przedziałów, ale reguły punktacji preferują najbardziej spójne. Dzięki jawnemu modelowaniu zależności między początkiem, końcem i kategorią system lepiej radzi sobie z zagnieżdżonymi lub dwuznacznymi encjami — częstą przeszkodą w języku japońskim. Wspólna funkcja straty trenuje wszystkie trzy decyzje razem, poprawiając zarówno dokładność granic, jak i końcowe etykiety.
Co te wyniki oznaczają w praktyce
Testowany na kilku japońskich benchmarkach symulujących sytuację zaledwie pięciu oznaczonych przykładów na typ encji, MAML‑ProtoNet++ przewyższa mocne bazowe metody, w tym standardowe dostrajanie, wcześniejsze metody meta‑uczenia i samo pretrenowanie kontrastowe. Osiąga makro F1 około 0,77 w najtrudniejszym ustawieniu i uzyskuje wyraźnie wysoką dokładność dla dokładnych pozycji początku i końca encji. Podejście dobrze transferuje także do nowych domen, takich jak teksty biomedyczne i prasowe, bez konieczności dużego retreningu. Dla czytelnika niemającego specjalistycznej wiedzy najważniejsze jest to, że autorzy zbudowali zwarty, wydajny system, który potrafi nauczyć się wyodrębniać nazwy i inne kluczowe terminy w tekście japońskim z bardzo niewielu wskazówek — dzięki sprytnemu generowaniu dodatkowych przykładów, czerpaniu międzyjęzykowych podpowiedzi i dynamicznemu dostosowywaniu sposobu uczenia się.
Cytowanie: Shao, X., Zhu, D., Liu, Q. et al. A joint span-entity prediction approach with generative and cross-lingual meta-learning for low-resource Japanese NER. Sci Rep 16, 10281 (2026). https://doi.org/10.1038/s41598-026-41621-0
Słowa kluczowe: rozpoznawanie nazw własnych w języku japońskim, uczenie na kilku przykładach, międzyjęzykowe NLP, meta-uczenie, augmentacja danych