Clear Sky Science · ru
Совместный подход предсказания интервалов-сущностей с генеративным и кросс-языковым мета-обучением для NER японского языка при малом объёме данных
Обучая компьютеры находить имена в японском тексте
Онлайн-информация заполнена именами людей, мест, компаний и дат, и программное обеспечение, способное автоматически находить эти «кто, где и когда» подсказки, жизненно важно для поисковых систем, финансов, медицины и других областей. Но если для английского доступно много данных для обучения таких систем, то японский представляет собой особую проблему: в нём отсутствуют пробелы между словами и существуют сложные шаблоны письма. В этом исследовании представлен новый метод под названием MAML‑ProtoNet++, который помогает компьютерам распознавать именованные сущности в японском языке даже при наличии лишь нескольких размеченных примеров.
Почему японский особенно сложен
Во многих европейских языках слова разделяются пробелами, поэтому алгоритмам проще угадать, где одно слово заканчивается и начинается другое. Японские предложения же записаны как непрерывный поток символов. Имена могут быть длинными, состоять из нескольких частей и менять форму в зависимости от контекста. Традиционные нейронные сети, даже мощные многоязычные модели, с трудом решают, где начинаются и заканчиваются сущности и какого они типа. Они также сильно зависят от больших размеченных наборов данных, которых для японского немного. В результате существующие системы часто разделяют одну организацию на две части, пропускают дальние связи в предложении или плохо переносятся с обучения на английском на японский текст.
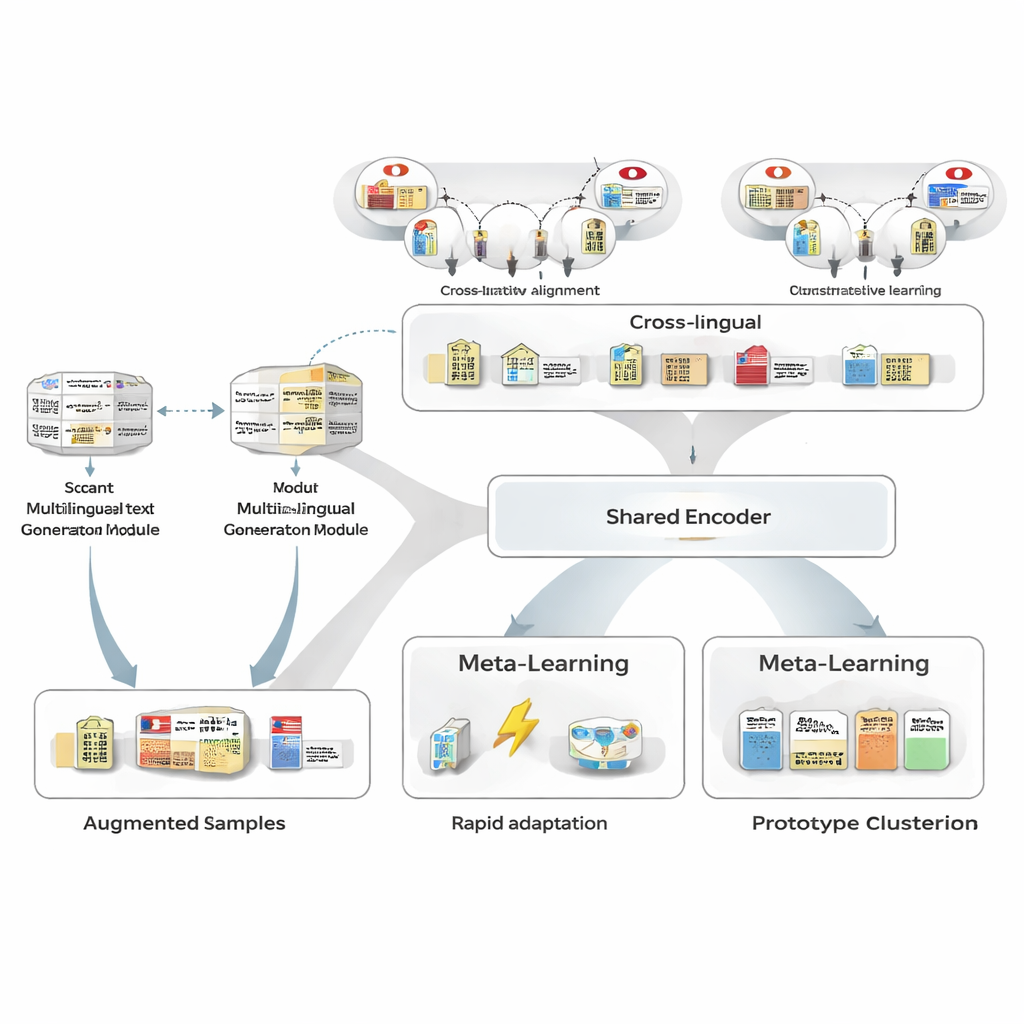
Создание дополнительных примеров без новых ручных разметок
Чтобы преодолеть недостаток обучающих данных, авторы сначала используют многоязычный генератор текста для перефразирования имеющихся нескольких аннотированных японских предложений. Генератор производит новые варианты, сохраняя те же сущности и их типы, но варьируя формулировки: перефразируя предложения, заменяя упоминания сущностей на похожие или меняя окружающий контекст. Тщательная фильтрующая конвейерная проверка затем отсеивает плохие перефразирования с помощью трёх тестов: проверка уверенности отдельного теггера, проверка того, что границы сущностей и их типы соответствуют оригиналу, и тест семантического сходства, который избегает почти идентичных дублей. Оставшиеся синтетические предложения расширяют набор увиденных моделью шаблонов, повышая её устойчивость при очень низком уровне шума в разметке.
Заимствование силы между языками
Далее фреймворк учится выравнивать японские сущности с их аналогами в других языках, используя большую базу знаний. Пары вроде «Токийское столичное правительство» на японском и на китайском отображаются в общее математическое пространство так, чтобы совпадающие сущности располагались близко, а не связанные — отталкивались. Это контрастивное предварительное обучение не пытается закодировать все доменные знание; вместо этого оно даёт модели независимый от языка каркас, чтобы похожие концепты выглядели похожими независимо от языка. Позже, при задачно-специфичном обучении, японская супервизия может перестроить это пространство, но кросс-языковой приоритет облегчает обобщение от небольшого числа примеров и значительно повышает сходство японско-английских пар сущностей.
Обучение тому, как учиться по нескольким примерам
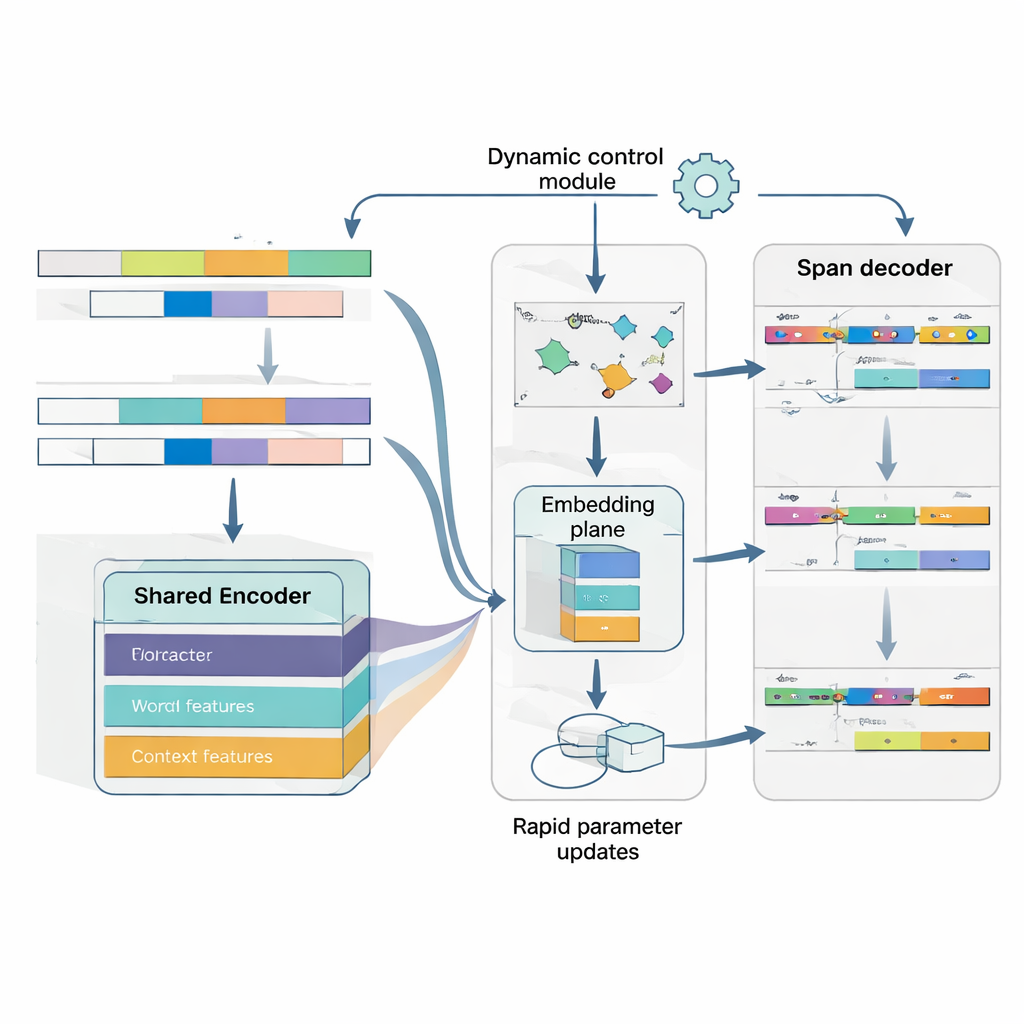
Сердцем MAML‑ProtoNet++ является стратегия «обучения учиться». Вместо одиночного обучения на огромном наборе данных модель тренируется на многих небольших задачах, имитирующих реальные сценарии с малым числом примеров: имея несколько размеченных предложений и небольшой тестовый набор, быстро адаптироваться. Комбинируются две известные идеи. Первая — компонент быстрой адаптации, который настраивает параметры модели за несколько шагов градиента, чтобы она могла подстроиться под новую задачу. Вторая — прототипный компонент, который строит репрезентативный вектор для каждого типа сущности и классифицирует новые интервалы по расстоянию до этих прототипов. Отдельная управляющая сеть оценивает, насколько сложна задача — на основе имеющихся нескольких примеров — и автоматически регулирует скорости обучения, масштабы расстояний и степень доверия к разным уровням признаков (символы, слова или полный контекст). Такая динамическая регуляция помогает системе оставаться устойчивой и эффективной даже при большой вариативности задач.
Понимание и где сущность, и что она собой представляет
Наконец, модель рассматривает определение границ и присвоение типов как единое, скоординированное задание, а не как два отдельных шага. Сначала она предсказывает вероятные позиции начала сущностей в предложении, затем, будучи условленной на этих началах, предсказывает правдоподобные позиции окончаний, а затем классифицирует полученные интервалы по типам сущностей. Можно рассматривать несколько перекрывающихся интервалов, но правила оценки отдают предпочтение наиболее согласованным. Явно моделируя зависимость между началом, концом и категорией, система лучше справляется с вложенными или неоднозначными сущностями — частой проблемой в японском. Совместная функция потерь обучает все три решения вместе, улучшая как точность границ, так и окончательные метки.
Что означают результаты на практике
При тестировании на нескольких японских бенчмарках, имитирующих ситуацию с пятью размеченными примерами на тип сущности, MAML‑ProtoNet++ превосходит сильные базовые методы, включая стандартную донастройку, ранние методы мета-обучения и только контрастивное обучение. В наиболее сложной настройке он достигает макро F1 примерно 0,77 и показывает заметно высокую точность в определении точных позиций начала и конца сущностей. Подход также хорошо переносится на новые домены, такие как биомедицина и новостные тексты, без существенной повторной тренировки. Для неподготовленного читателя вывод таков: авторы создали компактную, эффективную систему, которая умеет выделять имена и другие ключевые термины в японском тексте, имея очень мало примеров, — за счёт разумной генерации дополнительных примеров, заимствования кросс-языковых подсказок и динамической настройки процесса обучения.
Цитирование: Shao, X., Zhu, D., Liu, Q. et al. A joint span-entity prediction approach with generative and cross-lingual meta-learning for low-resource Japanese NER. Sci Rep 16, 10281 (2026). https://doi.org/10.1038/s41598-026-41621-0
Ключевые слова: распознавание именованных сущностей на японском, обучение с малым числом примеров, кросс-языковая обработка естественного языка, мета-обучение, увеличение данных