Clear Sky Science · nl
Een gezamenlijke span-entiteit-voorspellingsaanpak met generatieve en cross-linguale meta-learning voor Japanse NER met weinig data
Computers leren namen herkennen in Japanse tekst
Online informatie staat vol met namen van mensen, plaatsen, bedrijven en datums, en software die deze „wie, waar en wanneer”-signalementen automatisch kan vinden is essentieel voor zoekmachines, financiën, geneeskunde en meer. Terwijl er voor het Engels veel data beschikbaar is om zulke systemen te trainen, vormt het Japans een bijzondere uitdaging: er zijn geen spaties tussen woorden en het schrift is complex. Deze studie introduceert een nieuwe methode, genaamd MAML‑ProtoNet++, die computers helpt om named entities in het Japans te herkennen, zelfs als er slechts een handvol gelabelde voorbeelden beschikbaar is.
Waarom Japans vooral lastig is
In veel Europese talen scheiden spaties woorden, waardoor algoritmen makkelijker kunnen inschatten waar een term eindigt en de volgende begint. Japanse zinnen worden echter geschreven als aaneengesloten reeksen karakters. Namen kunnen lang zijn, uit meerdere delen bestaan en van vorm veranderen afhankelijk van de context. Traditionele neurale netwerken, zelfs krachtige meertalige modellen, hebben moeite te bepalen waar een entiteit begint en eindigt en welk type het is. Ze zijn ook sterk afhankelijk van grote gelabelde datasets, die schaars zijn voor het Japans. Daardoor splitsen bestaande systemen vaak één organisatie in twee delen, missen ze langeafstandrelaties in een zin of generaliseren ze slecht van op Engels gebaseerde training naar Japanse tekst.
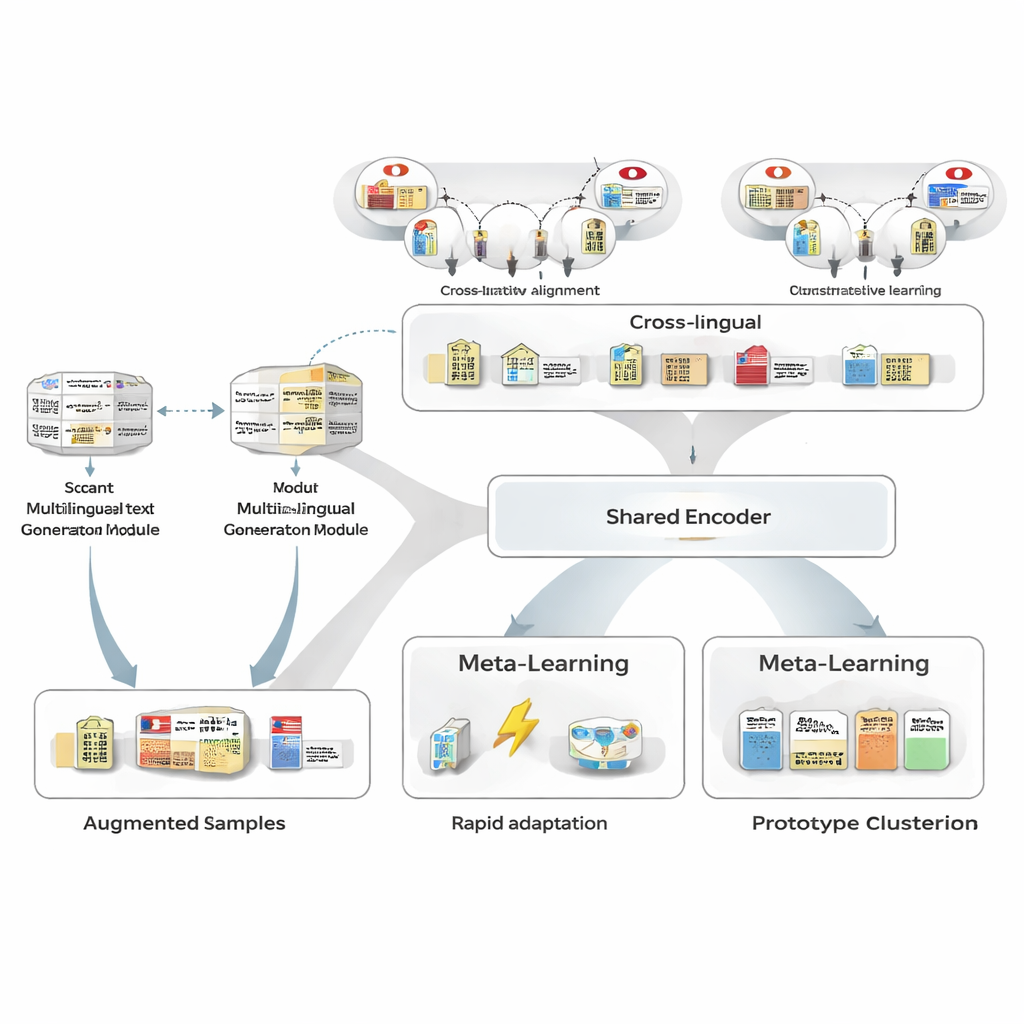
Meer voorbeelden maken zonder extra menselijke labels
Om het gebrek aan trainingsdata te ondervangen gebruiken de auteurs eerst een meertalig tekstgenerator om de weinige geannoteerde Japanse zinnen die ze hebben herschrijven. De generator produceert nieuwe versies die dezelfde entiteiten en types behouden maar de bewoording variëren: zinnen anders formuleren, entiteitsvermeldingen vervangen door soortgelijke exemplaren of de omliggende context veranderen. Een zorgvuldig filtratieproces verwijdert slechte herschrijvingen met drie tests: een betrouwbaarheidscontrole van een aparte tagger, een controle dat entiteitsgrenzen en types nog steeds overeenkomen met het origineel, en een semantische gelijkheidstest die near-duplicates vermijdt. De overgebleven synthetische zinnen verbreden het patroonbereik dat het model ziet, wat de robuustheid verbetert terwijl de labelruis zeer laag blijft.
Kracht lenen over talen heen
Vervolgens leert het raamwerk Japanse entiteiten af te stemmen op hun tegenhangers in andere talen met behulp van een grote kennisbank. Paarvormen zoals „Tokyo Metropolitan Government” in het Japans en in het Chinees worden in een gedeelde wiskundige ruimte gemapt, zodat overeenkomende entiteiten dicht bij elkaar komen te liggen en niet-gerelateerde entiteiten uit elkaar worden gedrukt. Deze contrastieve pretraining probeert niet alle domeinkennis vast te leggen; in plaats daarvan geeft het het model een taal-agnostische ruggengraat zodat vergelijkbare concepten er vergelijkbaar uitzien ongeacht de taal. Later, tijdens taakspecifieke training, kan Japanse supervisie deze ruimte bijsturen, maar de cross-linguale prior maakt het makkelijker te generaliseren van weinig voorbeelden en verhoogt de gelijkenis tussen Japanse–Engelse entiteitspaaren van matig naar zeer hoog.
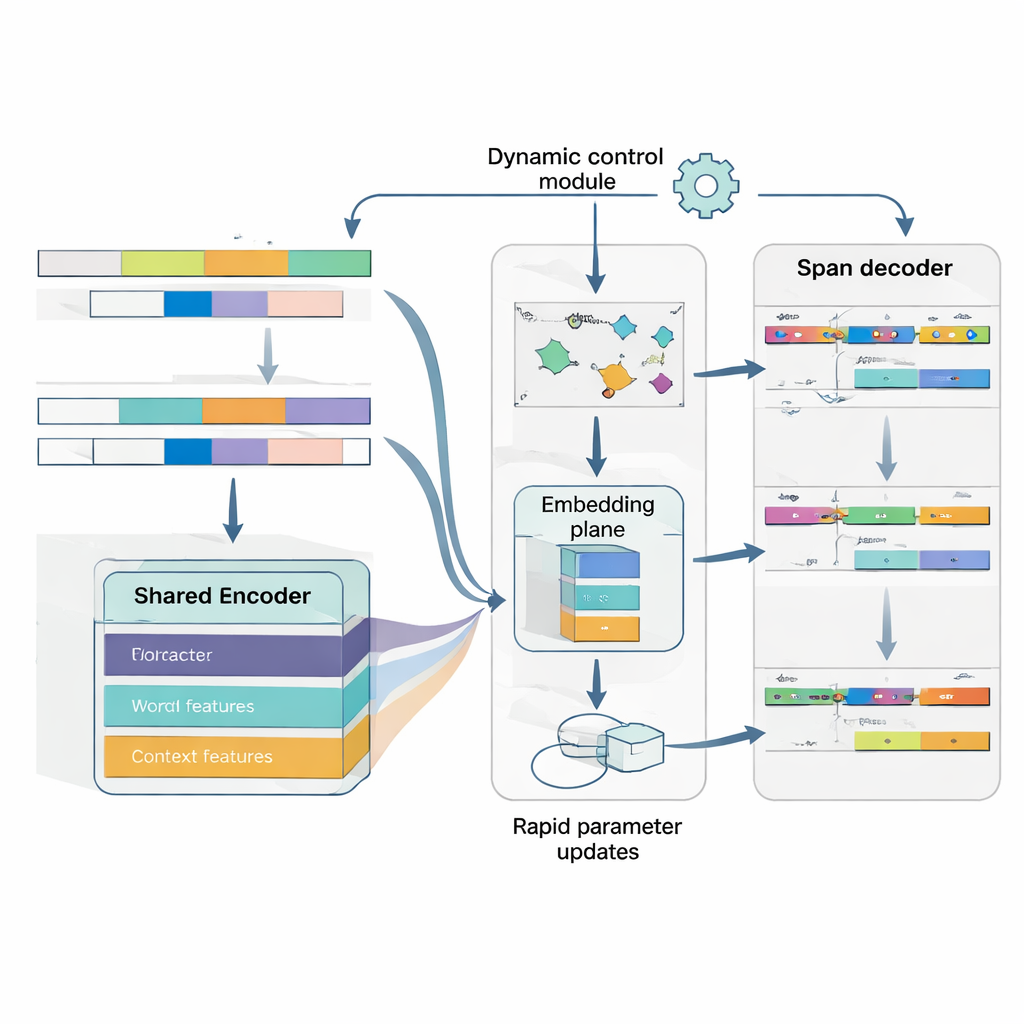
Leren hoe te leren van slechts enkele voorbeelden
De kern van MAML‑ProtoNet++ is een „leren leren”-strategie. In plaats van één keer te trainen op een enorm dataset, oefent het model op veel kleine taken die echte few-shot scenario’s nabootsen: gegeven een handvol gelabelde zinnen en een kleine testset, pas je snel aan. Twee bekende ideeën worden gecombineerd. Ten eerste een snelle adaptatiecomponent die modelparameters met een paar gradientstappen aanpast zodat het zich kan afstemmen op elke nieuwe taak. Ten tweede een prototype-gebaseerde component die een representatieve vector voor elk entiteitstype bouwt en nieuwe spans classificeert op basis van afstand tot deze prototypes. Een aparte controle-netwerk kijkt hoe moeilijk een taak lijkt — gebaseerd op de weinige gelabelde voorbeelden — en past vervolgens automatisch leersnelheden, afstandsschalen en de mate van vertrouwen in verschillende feature-niveaus (tekens, woorden of volledige context) aan. Deze dynamische controle helpt het systeem stabiel en effectief te blijven, zelfs wanneer taken sterk variëren.
Begrijpen waar een entiteit is en wat het is
Ten slotte behandelt het model grensdetectie en type-toewijzing als één gecoördineerd probleem in plaats van twee afzonderlijke stappen. Het voorspelt eerst waarschijnlijke startposities voor entiteiten in een zin, daarna, geconditioneerd op die starts, voorspelt het plausibele eindposities, en classificeert vervolgens de resulterende spans in entiteitstypes. Meerdere overlappende spans kunnen worden overwogen, maar scorerules geven de voorkeur aan de meest coherente. Door expliciet de afhankelijkheid tussen start, eind en categorie te modelleren, wordt het systeem beter in het omgaan met geneste of ambigue entiteiten — een veelvoorkomend obstakel in het Japans. Een gezamenlijke verliesfunctie traint alle drie beslissingen samen, wat zowel de grensnauwkeurigheid als de uiteindelijke labels verbetert.
Wat de resultaten in de praktijk betekenen
Getest op meerdere Japanse benchmarks die simuleren dat er slechts vijf gelabelde voorbeelden per entiteitstype beschikbaar zijn, presteert MAML‑ProtoNet++ beter dan sterke baselines, waaronder standaard fine-tuning, eerdere meta-learningmethoden en alleen contrastieve training. Het bereikt een macro F1-score van ongeveer 0,77 in de meest uitdagende setting en behaalt opmerkelijk hoge nauwkeurigheid op de exacte start- en eindposities van entiteiten. De aanpak generaliseert ook goed naar nieuwe domeinen, zoals biomedische en nieuws-teksten, zonder ingrijpende retraining. Voor een niet-specialist is de conclusie dat de auteurs een compact, efficiënt systeem hebben gebouwd dat kan leren namen en andere sleuteltermen in Japanse tekst te herkennen met zeer weinig aanwijzingen, door slim extra voorbeelden te genereren, cross-linguale aanwijzingen te benutten en adaptief te bepalen hoe het leert.
Bronvermelding: Shao, X., Zhu, D., Liu, Q. et al. A joint span-entity prediction approach with generative and cross-lingual meta-learning for low-resource Japanese NER. Sci Rep 16, 10281 (2026). https://doi.org/10.1038/s41598-026-41621-0
Trefwoorden: Japanse named entity recognition, few-shot learning, cross-linguale NLP, meta-learning, data-augmentatie