Clear Sky Science · sv
En gemensam span- och entity-prediktionsmetod med generativ och tvärspråkig meta-inlärning för japansk NER med få resurser
Lära datorer att hitta namn i japansk text
Onlineinformation är full av namn på personer, platser, företag och datum, och programvara som automatiskt kan hitta dessa ”vem, var och när”-ledtrådar är avgörande för sökmotorer, finans, medicin med mera. Men medan engelska har gott om data för att träna sådana system, utgör japanska en särskild utmaning: språket saknar blanksteg mellan ord och har komplexa skriftsystem. Denna studie presenterar en ny metod, kallad MAML‑ProtoNet++, som hjälper datorer att lära sig känna igen named entities i japanska även när endast ett fåtal märkta exempel finns tillgängliga.
Varför japanska är särskilt knepigt
I många europeiska språk skiljer blanksteg åt orden, så algoritmer lättare kan gissa var ett uttryck slutar och ett annat börjar. Japanska meningar skrivs däremot som kontinuerliga strömmar av tecken. Namn kan vara långa, byggda av flera delar, och förändras beroende på sammanhang. Traditionella neurala nätverk, även kraftfulla flerspråkiga modeller, har svårt att avgöra var en entity börjar och slutar och vilken typ det är. De är också starkt beroende av stora märkta dataset, som är sällsynta för japanska. Som ett resultat delar befintliga system ofta upp en organisation i två delar, missar långdistansrelationer i en mening eller överför dåligt från engelskbased träning till japansk text.
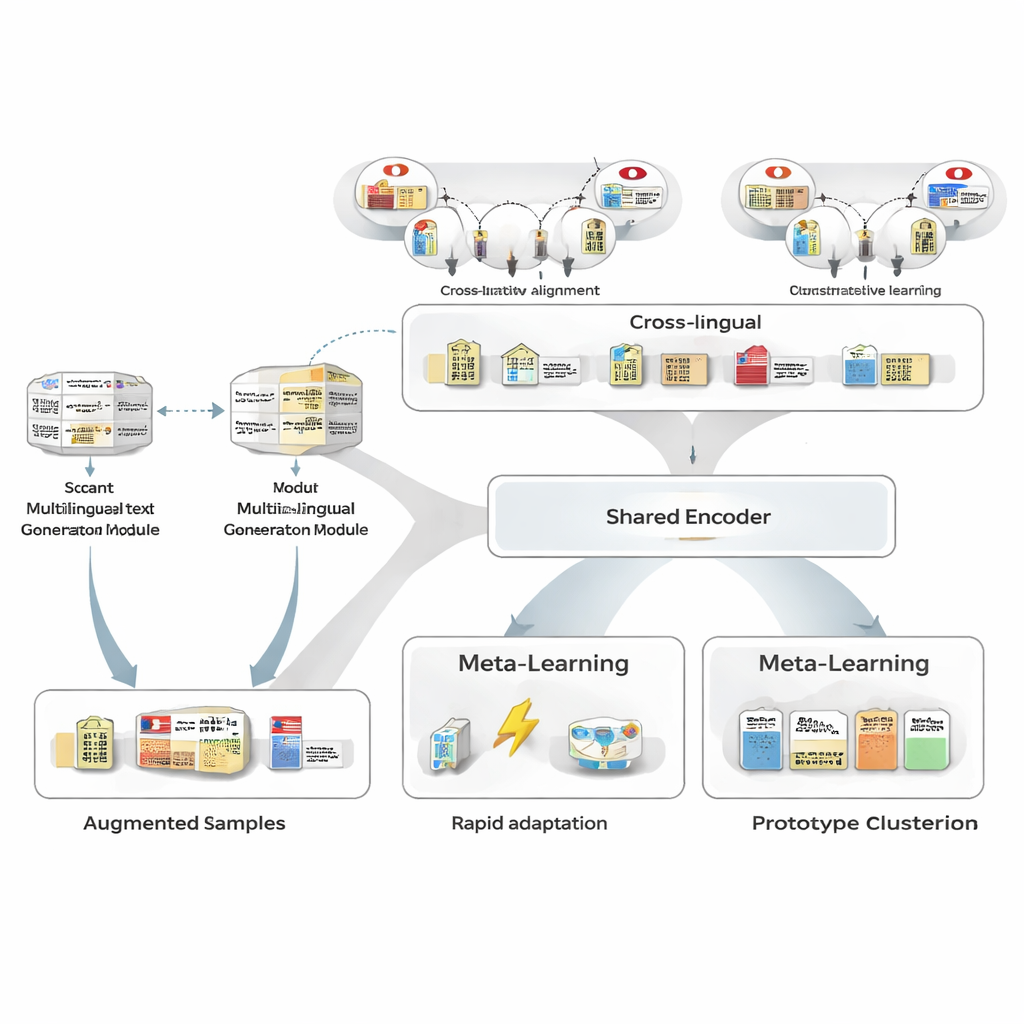
Skapa fler exempel utan fler mänskliga etiketter
För att övervinna bristen på träningsdata använder författarna först en flerspråkig textgenerator för att omskriva de få annoterade japanska meningarna de har. Generatorn producerar nya versioner som behåller samma entiteter och typer men varierar formuleringen: omformulera meningar, byta ut entity-omnämnanden mot liknande eller ändra den omgivande kontexten. En noggrann filtreringspipeline sorterar sedan bort dåliga omskrivningar med tre tester: en förtroendekontroll från en separat taggare, en kontroll att entity-gränser och typer fortfarande matchar originalet, och ett semantiskt likhetsprov som undviker närapå-dupliceringar. De överlevande syntetiska meningarna vidgar de mönster modellen får se, förbättrar robustheten samtidigt som etikettbullret hålls mycket lågt.
Låna styrka över språkgränser
Nästa steg är att ramverket lär sig att alignera japanska entiteter med deras motsvarigheter i andra språk med hjälp av en stor kunskapsbas. Par som ”Tokyo Metropolitan Government” på japanska och kinesiska kartläggs in i ett delat matematisk rum så att matchande entiteter hamnar nära varandra medan orelaterade skjuts isär. Denna kontrastiva förträning försöker inte koda all domänkunskap; istället ger den modellen en språkoberoende ryggrad så att liknande begrepp ser lika ut oavsett språk. Senare, under uppgiftsspecifik träning, kan japansk övervakning omforma detta rum, men det tvärspråkiga prioritetet gör det enklare att generalisera från få exempel och förbättrar likheten mellan japanska–engelska entity-par från måttliga till mycket höga nivåer.
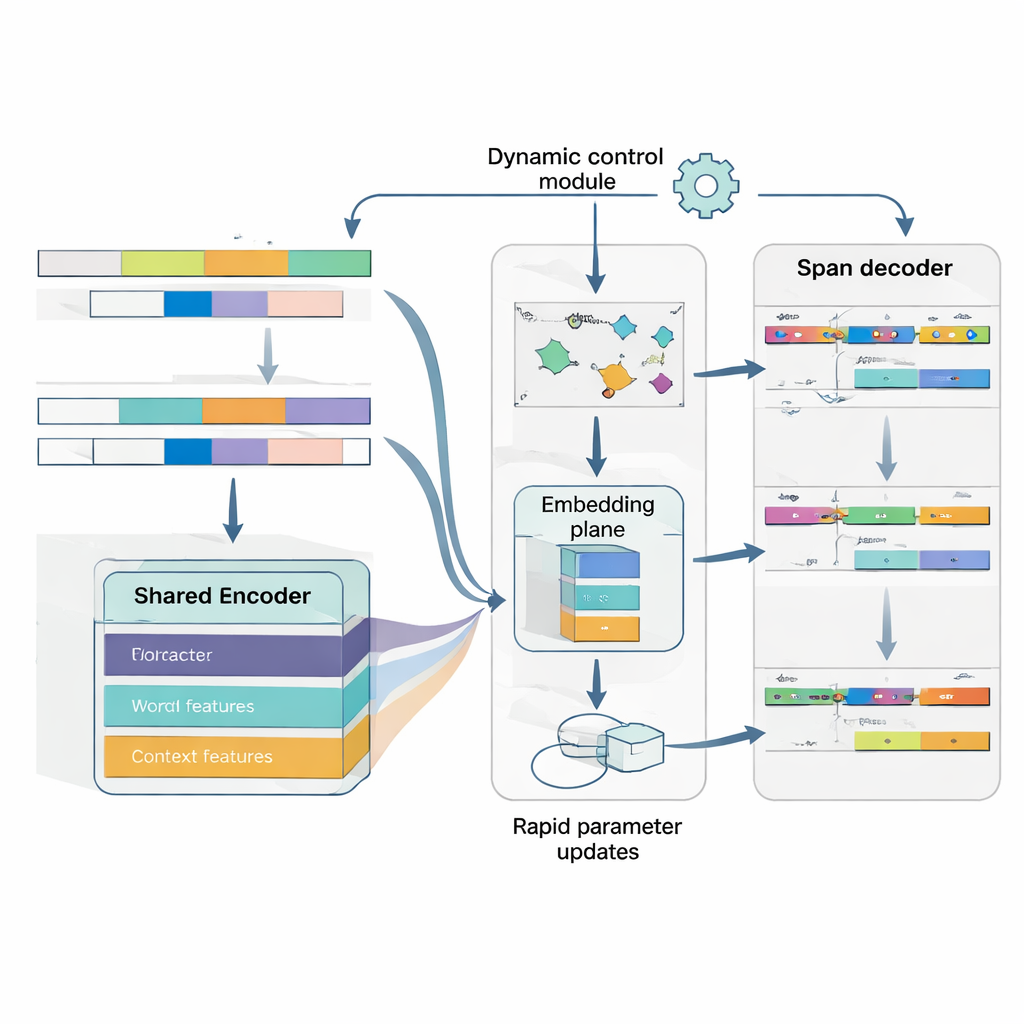
Lära sig att lära från bara några få exempel
Kärnan i MAML‑ProtoNet++ är en ”lära sig att lära”-strategi. Istället för att träna en gång på ett stort dataset övar modellen på många små uppgifter som efterliknar verkliga few-shot-scenarier: givet ett fåtal märkta meningar och en liten testuppsättning, anpassa snabbt. Två välkända idéer kombineras. Dels en snabb anpassningskomponent som justerar modellparametrar med några gradientsteg så att den kan ställa in sig på varje ny uppgift. Dels en prototypbaserad komponent som bygger en representativ vektor för varje entity-typ och klassificerar nya spans utifrån avstånd till dessa prototyper. Ett separat styrnätverk bedömer hur svårt en uppgift verkar—baserat på dess få märkta exempel—och justerar automatiskt inlärningshastor, avståndsskalor och hur mycket olika funktionsnivåer (tecken, ord eller full kontext) ska litas på. Denna dynamiska kontroll hjälper systemet att förbli stabilt och effektivt även när uppgifterna varierar mycket.
Förstå både var en entity är och vad den är
Slutligen behandlar modellen gränsdetektion och typ-tilldelning som ett enda koordinerat problem snarare än två separata steg. Den förutsäger först sannolika startpositioner för entiteter i en mening, sedan, betingat på dessa starter, förutsäger sannolika slutpositioner och klassificerar därefter de resulterande spans till entity-typer. Flera överlappande spans kan beaktas, men poängsättningsregler favoriserar de mest koherenta. Genom att explicit modellera beroendet mellan start, slut och kategori blir systemet bättre på att hantera nästlade eller tvetydiga entiteter—en vanlig svårighet i japanska. En gemensam förlustfunktion tränar alla tre beslut samtidigt, vilket förbättrar både gränsnoggrannhet och slutgiltiga etiketter.
Vad resultaten betyder i praktiken
När modellen testades på flera japanska riktmärken som simulerar att endast fem märkta exempel per entity-typ finns, överträffar MAML‑ProtoNet++ starka baseline-metoder, inklusive standard finjustering, tidigare meta-inlärningsmetoder och endast kontrastiv träning. Den når ett makro F1-värde på ungefär 0,77 i den mest utmanande inställningen och uppnår anmärkningsvärt hög noggrannhet på exakt start och slut av entiteter. Metoden överför sig också väl till nya domäner, såsom biomedicinsk och nyhetstext, utan omfattande omträning. För en lekmannaläsare är slutsatsen att författarna byggt ett kompakt, effektivt system som kan lära sig plocka ut namn och andra nyckeltermer i japansk text från mycket liten vägledning, genom att smart generera extra exempel, låna tvärspråkiga signaler och justera hur det lär sig i farten.
Citering: Shao, X., Zhu, D., Liu, Q. et al. A joint span-entity prediction approach with generative and cross-lingual meta-learning for low-resource Japanese NER. Sci Rep 16, 10281 (2026). https://doi.org/10.1038/s41598-026-41621-0
Nyckelord: Japansk named entity recognition, few-shot learning, cross-lingual NLP, meta-learning, data augmentation