Clear Sky Science · es
Un enfoque conjunto de predicción de span-entidad con meta-aprendizaje generativo y cross-lingüístico para NER de japonés con pocos recursos
Enseñar a las máquinas a detectar nombres en texto japonés
La información en línea está llena de nombres de personas, lugares, empresas y fechas, y el software capaz de encontrar automáticamente estas pistas de “quién, dónde y cuándo” es vital para motores de búsqueda, finanzas, medicina y más. Pero, mientras que el inglés dispone de abundantes datos para entrenar estos sistemas, el japonés plantea un desafío especial: carece de espacios entre palabras y presenta patrones de escritura complejos. Este estudio presenta un nuevo método, llamado MAML‑ProtoNet++, que ayuda a las máquinas a aprender a reconocer entidades nombradas en japonés incluso cuando solo hay disponibles unos pocos ejemplos etiquetados.
Por qué el japonés es especialmente complicado
En muchas lenguas europeas, los espacios separan las palabras, por lo que los algoritmos pueden adivinar con más facilidad dónde termina un término y comienza otro. Sin embargo, las oraciones en japonés se escriben como flujos continuos de caracteres. Los nombres pueden ser largos, formados por múltiples partes, y cambiar de forma según el contexto. Las redes neuronales tradicionales, incluso los potentes modelos multilingües, tienen problemas para decidir dónde empieza y termina una entidad y de qué tipo es. Además, dependen en gran medida de grandes conjuntos de datos etiquetados, que son escasos para el japonés. Como resultado, los sistemas existentes a menudo dividen una única organización en dos partes, pasan por alto relaciones de largo alcance en una frase o transfieren mal el entrenamiento desde el inglés al japonés.
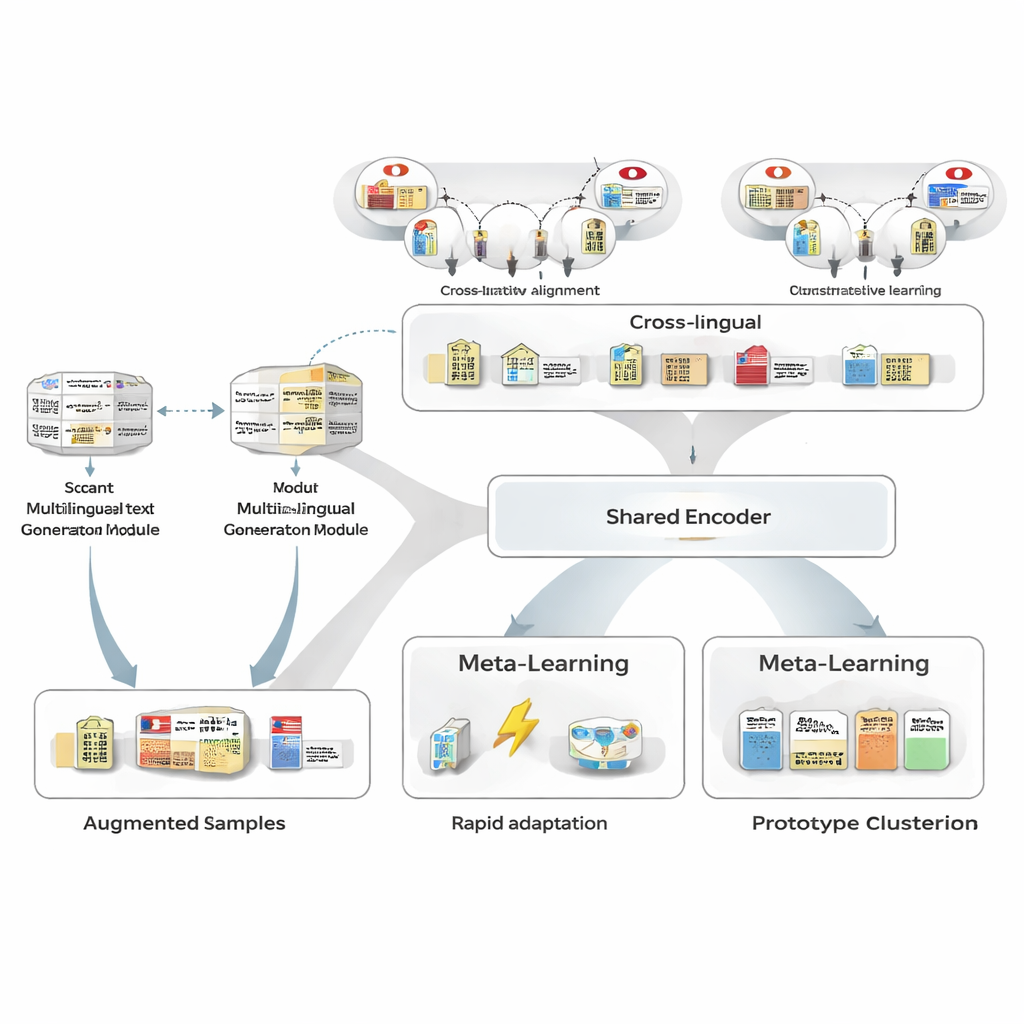
Generar más ejemplos sin más etiquetas humanas
Para superar la escasez de datos de entrenamiento, los autores primero usan un generador de texto multilingüe para reescribir las pocas frases japonesas anotadas que tienen. El generador produce versiones nuevas que mantienen las mismas entidades y tipos pero varían la redacción: reformulando oraciones, sustituyendo menciones de entidades por otras similares o cambiando el contexto circundante. A continuación, una canalización de filtrado cuidadosa elimina las reescrituras pobres mediante tres pruebas: una comprobación de confianza de un etiquetador independiente, una verificación de que los límites y tipos de entidad siguen coincidiendo con el original y una prueba de similitud semántica que evita casi duplicados. Las frases sintéticas que sobreviven amplían la gama de patrones que ve el modelo, mejorando la robustez y manteniendo el ruido en las etiquetas muy bajo.
Tomar prestada fuerza entre idiomas
A continuación, el marco aprende a alinear las entidades japonesas con sus contrapartes en otros idiomas usando una gran base de conocimiento. Parejas como “Tokyo Metropolitan Government” en japonés y en chino se mapean en un espacio matemático compartido de modo que las entidades coincidentes queden cerca unas de otras y las no relacionadas se aparten. Este preentrenamiento contrastivo no pretende codificar todo el conocimiento del dominio; en su lugar, proporciona al modelo una columna vertebral agnóstica al idioma para que conceptos similares se perciban parecidos independientemente del idioma. Más tarde, durante el entrenamiento específico de la tarea, la supervisión en japonés puede remodelar este espacio, pero el prior cross-lingüístico facilita la generalización a partir de pocos ejemplos y mejora la similitud entre pares de entidades japonés–inglés de niveles moderados a muy altos.
Aprender a aprender con solo unos pocos ejemplos
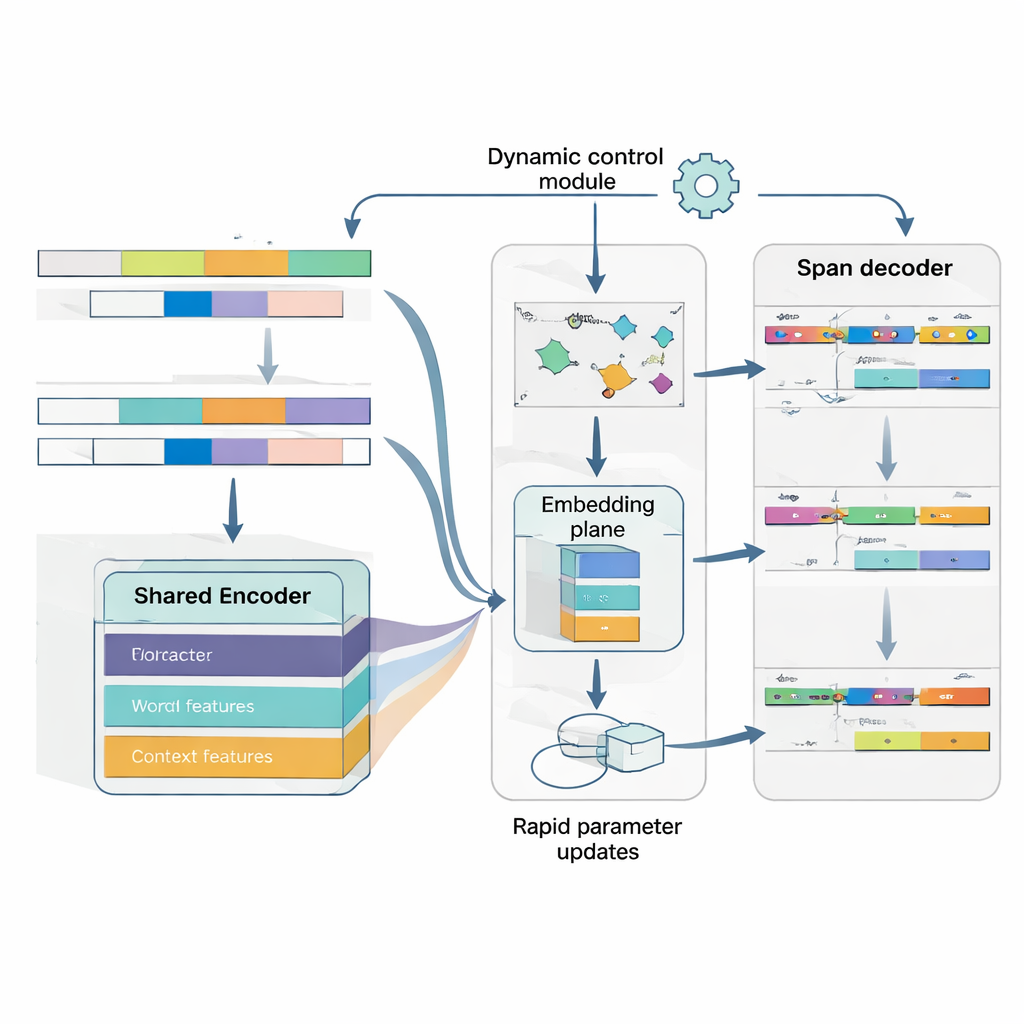
El núcleo de MAML‑ProtoNet++ es una estrategia de “aprender a aprender”. En lugar de entrenar una vez con un conjunto de datos enorme, el modelo practica con muchas tareas diminutas que imitan escenarios reales de pocos disparos: dadas unas pocas oraciones etiquetadas y un pequeño conjunto de prueba, adaptarse rápidamente. Se combinan dos ideas bien conocidas. Una, un componente de adaptación rápida, ajusta los parámetros del modelo con unos pocos pasos de gradiente para que pueda sintonizarse a cada nueva tarea. Dos, un componente basado en prototipos construye un vector representativo para cada tipo de entidad y clasifica nuevos spans por la distancia a estos prototipos. Una red de control separada observa lo difícil que parece una tarea —basándose en sus pocos ejemplos etiquetados— y luego ajusta automáticamente las tasas de aprendizaje, las escalas de distancia y cuánto confiar en diferentes niveles de características (caracteres, palabras o contexto completo). Este control dinámico ayuda al sistema a mantenerse estable y eficaz incluso cuando las tareas varían ampliamente.
Entender tanto dónde está una entidad como qué es
Finalmente, el modelo trata la detección de límites y la asignación de tipos como un único problema coordinado en lugar de dos pasos separados. Primero predice posiciones probables de inicio para las entidades en una oración; luego, condicionada en esos inicios, predice posiciones de fin plausibles y después clasifica los spans resultantes en tipos de entidad. Se pueden considerar múltiples spans solapados, pero las reglas de puntuación favorecen los más coherentes. Al modelar explícitamente la dependencia entre inicio, fin y categoría, el sistema mejora en el manejo de entidades anidadas o ambiguas, un obstáculo común en japonés. Una función de pérdida conjunta entrena las tres decisiones a la vez, mejorando tanto la precisión de los límites como las etiquetas finales.
Qué significan los resultados en la práctica
Cuando se probó en varios puntos de referencia japoneses que simulan tener solo cinco ejemplos etiquetados por tipo de entidad, MAML‑ProtoNet++ supera a sólidos baselines, incluyendo ajuste fino estándar, métodos de meta-aprendizaje anteriores y solo entrenamiento contrastivo. Alcanza una puntuación macro F1 de alrededor de 0,77 en el escenario más desafiante y logra una precisión notablemente alta en el inicio y el fin exactos de las entidades. El enfoque también se transfiere bien a nuevos dominios, como textos biomédicos y noticias, sin un reentrenamiento mayor. Para un lector general, la conclusión es que los autores han construido un sistema compacto y eficiente que puede aprender a identificar nombres y otros términos clave en texto japonés con muy poca orientación, generando inteligentemente ejemplos adicionales, tomando pistas cross-lingüísticas y ajustando cómo aprende sobre la marcha.
Cita: Shao, X., Zhu, D., Liu, Q. et al. A joint span-entity prediction approach with generative and cross-lingual meta-learning for low-resource Japanese NER. Sci Rep 16, 10281 (2026). https://doi.org/10.1038/s41598-026-41621-0
Palabras clave: Reconocimiento de entidades nombradas en japonés, aprendizaje con pocos ejemplos, PNL cross-lingüística, meta-aprendizaje, aumento de datos