Clear Sky Science · ar
نهج مشترك لتنبؤ النطاق-الكيان مع تعلم ميتا توليدي وعبر لغوي للتعرّف على الكيانات المسماة اليابانية منخفضة الموارد
تعليم الحواسيب على التعرف على الأسماء في النص الياباني
المعلومات المتاحة على الإنترنت مليئة بأسماء أشخاص وأماكن وشركات وتواريخ، والبرمجيات القادرة على العثور تلقائياً على هذه المؤشرات من «من وأين ومتى» ضرورية لمحركات البحث والمال والطب والمجالات الأخرى. لكن بينما تملك الإنجليزية بيانات وفيرة لتدريب مثل هذه الأنظمة، تواجه اليابانية تحديات خاصة: فهي تفتقر إلى الفواصل بين الكلمات وتستخدم أنماط كتابة معقدة. تقدم هذه الدراسة طريقة جديدة تُسمى MAML‑ProtoNet++ تساعد الحواسيب على تعلم التعرف على الكيانات المسماة في اليابانية حتى عندما تتوفر أمثلة معنونة قليلة جداً.
لماذا اليابانية أكثر تعقيداً
في كثير من اللغات الأوروبية تفصل المسافات بين الكلمات، لذلك يمكن للخوارزميات أن تخمّن بسهولة أين ينتهي مصطلح ويبدأ آخر. تُكتب الجمل اليابانية، مع ذلك، كسلاسل مستمرة من الأحرف. قد تكون الأسماء طويلة، مركبة من أجزاء متعددة، وتتغير شكلها بحسب السياق. الشبكات العصبية التقليدية، وحتى النماذج المتعددة اللغات القوية، تجد صعوبة في تحديد مكان بدء وانتهاء الكيان ونوعه. كما أنها تعتمد بشدة على مجموعات بيانات معنونة كبيرة، وهي نادرة لليابانية. ونتيجة لذلك، كثيراً ما تقسم الأنظمة الحالية مؤسسة واحدة إلى قطعتين، أو تفوّت علاقات بعيدة المدى في الجملة، أو تفشل في الانتقال من التدريب المبني على الإنجليزية إلى النص الياباني.
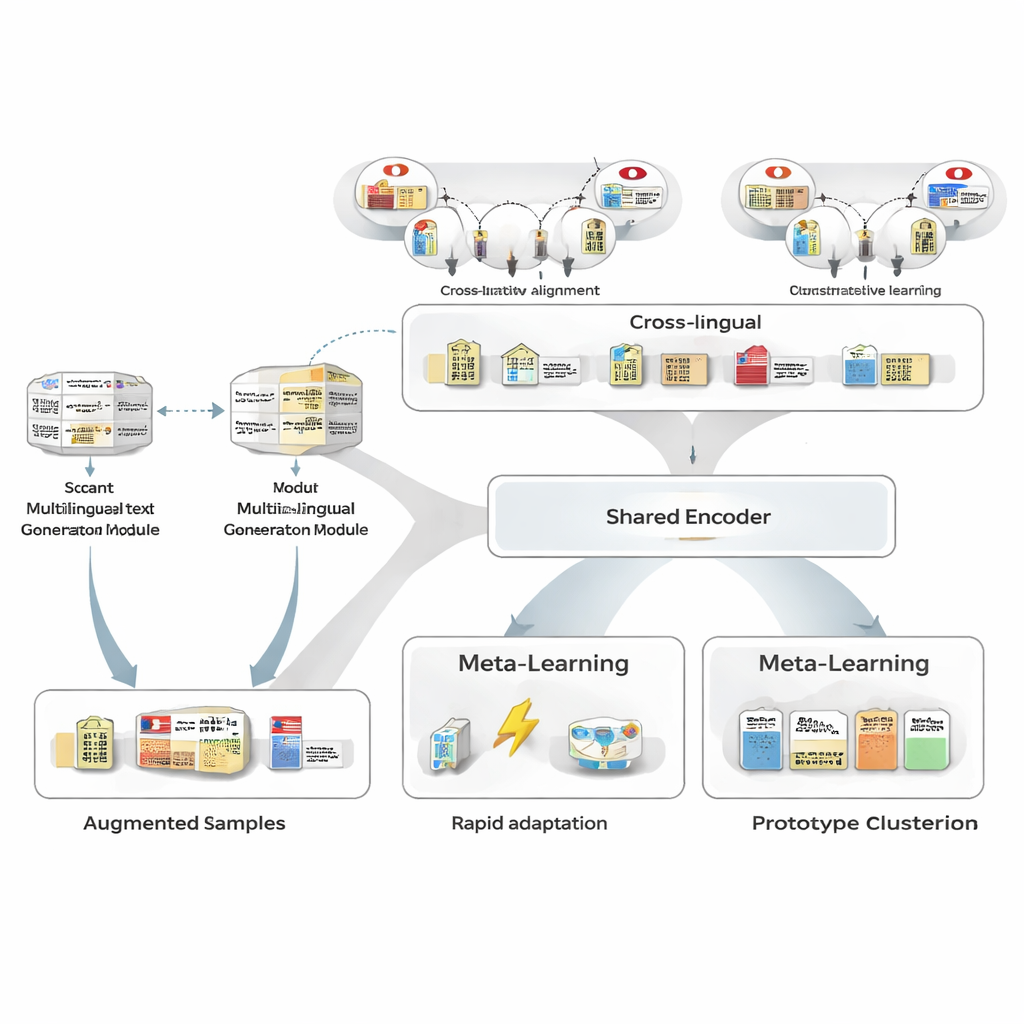
إنتاج المزيد من الأمثلة دون مزيد من الوسومات البشرية
لمواجهة نقص بيانات التدريب، يستخدم المؤلفون أولاً مولد نص متعدد اللغات لإعادة صياغة جمل يابانية معنونة قليلة متاحة لديهم. يولّد المولد نسخاً جديدة تحافظ على نفس الكيانات والأنواع لكن تغير الصياغة: إعادة صياغة الجمل، استبدال مرات ذكر الكيانات بأخرى مشابهة، أو تغيير السياق المحيط. ثم يفرز أنبوب تصفية دقيق الصياغات الضعيفة عبر ثلاثة اختبارات: فحص ثقة من وسم منفصل، فحص أن حدود الكيانات وأنواعها ما تزال مطابقة للأصل، واختبار تشابه دلالي لتجنب النسخ القريبة المكررة. الجمل الصناعية المتبقّية توسّع نطاق الأنماط التي يرىها النموذج، محسنّة المتانة مع الحفاظ على ضجيج الوسوم منخفضاً جداً.
الاستفادة من القوة عبر اللغات
بعدها، يتعلّم الإطار محاذاة الكيانات اليابانية مع نظيراتها في لغات أخرى باستخدام قاعدة معرفة كبيرة. تُطابق أزواج مثل «حكومة طوكيو الكبرى» باليابانية والصينية إلى فضاء رياضي مشترك بحيث تقع الكيانات المطابقة بالقرب من بعضها ويُبعد غير ذات الصلة. لا يهدف هذا التدريب التبايني إلى تشفير كل المعرفة المقطعية؛ بل يمنح النموذج قاعدة عامة خالية من اللغة بحيث تبدو المفاهيم المماثلة متقاربة بغض النظر عن اللغة. لاحقاً، أثناء التدريب الخاص بالمهمة، يمكن للإشراف الياباني إعادة تشكيل هذا الفضاء، لكن الأولية عبر اللغات تسهّل التعميم من أمثلة قليلة وتحسّن تشابه أزواج الكيانات اليابانية–الإنجليزية من مستوى متوسط إلى مستوى عالٍ جداً.
تعلم كيف يتعلم من عدد قليل من الأمثلة
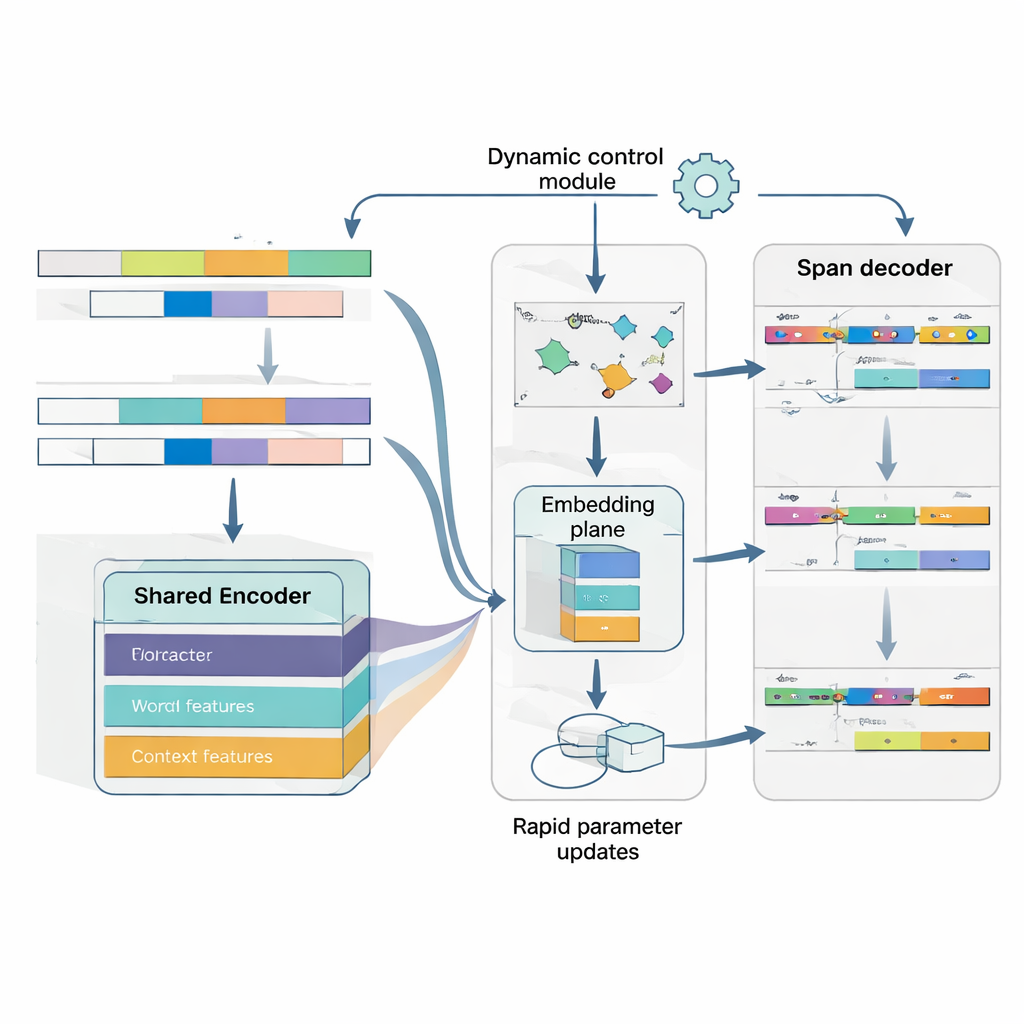
جوهر MAML‑ProtoNet++ هو استراتيجية «التعلم من أجل التعلم». بدلاً من التدريب مرة واحدة على مجموعة بيانات هائلة، يتدرّب النموذج على العديد من المهام الصغيرة التي تحاكي سيناريوهات التعلّم بعدد قليل من الأمثلة: مع عدد محدود من الجمل المعنونة ومجموعة اختبار صغيرة، يتكيّف بسرعة. يجمع النهج بين فكرتين معروفتين. الأولى، مكوّن التكيّف السريع، يعدّل معلمات النموذج بعد بضع خطوات تدرج بحيث يمكنه ضبط نفسه لكل مهمة جديدة. الثانية، مكوّن قائم على النماذج (prototypes) يبني متجهاً تمثيلياً لكل نوع كيان ويصنّف النطاقات الجديدة حسب المسافة إلى هذه النماذج. تنظر شبكة تحكم منفصلة في مدى صعوبة المهمة—استناداً إلى أمثلة التدريب القليلة—ثم تضبط تلقائياً معدلات التعلم ومقاييس المسافة وكمية الاعتماد على مستويات ميزات مختلفة (أحرف، كلمات، أو السياق الكامل). يساعد هذا التحكم الديناميكي النظام على البقاء مستقراً وفعّالاً حتى عندما تختلف المهام على نطاق واسع.
فهم كل من مكان وجود الكيان وماهيةه
أخيراً، يعامل النموذج اكتشاف الحدود وتعيين النوع كمشكلة واحدة منسقة بدلاً من خطوتين منفصلتين. يتنبأ أولاً بالمواقع المحتملة لبدايات الكيانات في الجملة، ثم، مشروطاً على تلك البدايات، يتنبأ بنهايات محتملة، ثم يصنّف النطاقات الناتجة إلى أنواع كيان. يمكن اعتبار نطاقات متداخلة متعددة، لكن قواعد التقييم تُفضّل الأنسب منها. من خلال نمذجة الاعتماد بين البدء والنهاية والفئة صراحةً، يصبح النظام أفضل في التعامل مع الكيانات المتداخلة أو الغامضة—وهو عقبة شائعة في اليابانية. وظيفة خسارة مشتركة تدرب القرارات الثلاثة معاً، محققة تحسناً في كل من دقة الحدود والوسوم النهائية.
ماذا تعني النتائج عملياً
عند الاختبار على عدة معايير يابانية تحاكي توفر خمسة أمثلة معنونة فقط لكل نوع كيان، يتفوق MAML‑ProtoNet++ على قواعد مقارنة قوية، بما في ذلك الضبط الدقيق القياسي، وطرق التعلم الميتا السابقة، والتدريب التبايني وحده. يصل إلى درجة F1 ماكرو تقارب 0.77 في أقسى الإعدادات ويحقق دقة عالية ملحوظة في تحديد بدايات ونهايات الكيانات بالضبط. كما ينتقل النهج جيداً إلى مجالات جديدة، مثل النصوص الطبية والأخبار، دون إعادة تدريب كبيرة. للقراء العامين، الخلاصة أن المؤلفين بنوا نظاماً مدمجاً وفعالاً يمكنه تعلم انتقاء الأسماء والمصطلحات الرئيسية في النص الياباني من إرشاد ضئيل جداً، عبر توليد أمثلة إضافية بذكاء، واقتراض تلميحات عبر اللغات، وتعديل طريقة التعلم أثناء التنفيذ.
الاستشهاد: Shao, X., Zhu, D., Liu, Q. et al. A joint span-entity prediction approach with generative and cross-lingual meta-learning for low-resource Japanese NER. Sci Rep 16, 10281 (2026). https://doi.org/10.1038/s41598-026-41621-0
الكلمات المفتاحية: التعرّف على الكيانات المسماة اليابانية, التعلّم بعدد قليل من الأمثلة, المعالجة اللغوية عبر اللغات, التعلّم الميتا, توسيع البيانات