Clear Sky Science · it
Un approccio con previsione congiunta di span-entità usando meta-apprendimento generativo e cross-lingua per il NER giapponese a bassa risorsa
Insegnare ai computer a individuare nomi nel testo giapponese
Le informazioni online sono piene di nomi di persone, luoghi, aziende e date, e il software che è in grado di trovare automaticamente questi indizi di “chi, dove e quando” è fondamentale per i motori di ricerca, la finanza, la medicina e altro ancora. Mentre l’inglese dispone di abbondanti dati per addestrare tali sistemi, il giapponese presenta una sfida particolare: manca di spazi tra le parole e ha schemi di scrittura complessi. Questo studio presenta un nuovo metodo, chiamato MAML‑ProtoNet++, che aiuta i computer a riconoscere le entità denominate nel giapponese anche quando sono disponibili solo poche frasi annotate.
Perché il giapponese è particolarmente complesso
In molte lingue europee gli spazi separano le parole, quindi gli algoritmi possono più facilmente intuire dove termina un termine e dove ne inizia un altro. Le frasi giapponesi, invece, sono scritte come flussi continui di caratteri. I nomi possono essere lunghi, composti da più parti e variare forma a seconda del contesto. Le reti neurali tradizionali, perfino potenti modelli multilingue, faticano a decidere dove inizia e finisce un’entità e quale tipo rappresenti. Inoltre dipendono fortemente da grandi dataset etichettati, che sono scarsi per il giapponese. Di conseguenza, i sistemi esistenti spesso dividono un’unica organizzazione in due pezzi, trascurano relazioni a lungo raggio in una frase o trasferiscono male ciò che hanno imparato dall’inglese al giapponese.
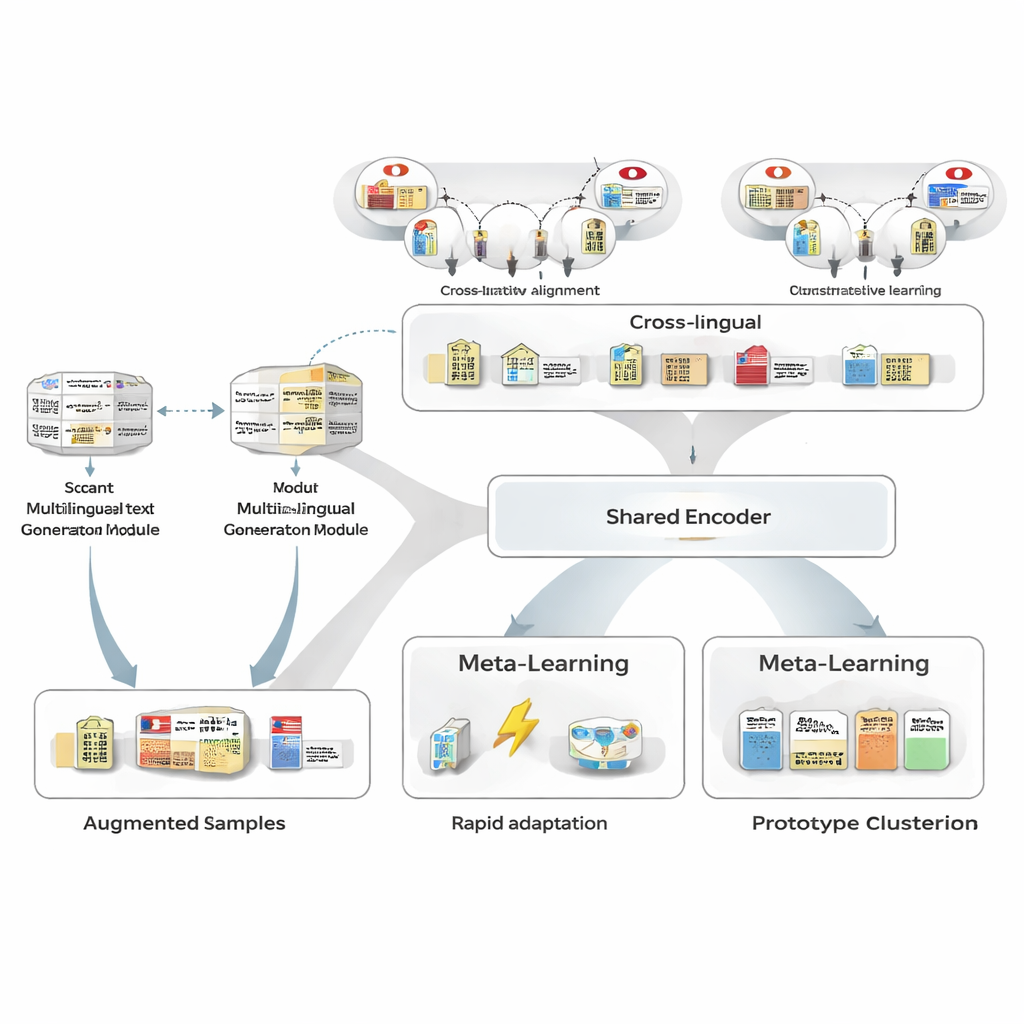
Creare più esempi senza più annotazioni umane
Per superare la scarsità di dati di addestramento, gli autori usano innanzitutto un generatore di testo multilingue per riscrivere le poche frasi giapponesi annotate a disposizione. Il generatore produce nuove versioni che mantengono le stesse entità e tipologie ma variano la formulazione: riformulando le frasi, sostituendo riferimenti a entità con altri simili o cambiando il contesto circostante. Una pipeline di filtraggio accurata elimina poi le riscritture scadenti usando tre test: un controllo di confidenza da un tagger separato, una verifica che i confini e i tipi delle entità coincidano ancora con l’originale e un test di similarità semantica che evita quasi-duplicati. Le frasi sintetiche che superano il filtro ampliano la gamma di schemi visti dal modello, migliorando la robustezza mantenendo molto bassa la rumorosità delle etichette.
Prendere forza in prestito attraverso le lingue
Successivamente, il framework impara ad allineare le entità giapponesi con le loro controparti in altre lingue usando una grande base di conoscenza. Coppie come “Tokyo Metropolitan Government” in giapponese e in cinese vengono mappate in uno spazio matematico condiviso in modo che entità corrispondenti risultino vicine e quelle non correlate siano spinte lontano. Questo pre-addestramento contrastivo non mira a codificare tutta la conoscenza del dominio; invece fornisce al modello una spina dorsale indipendente dalla lingua in modo che concetti simili appaiano simili a prescindere dalla lingua. Successivamente, durante l’addestramento specifico per il compito, la supervisione giapponese può rimodellare questo spazio, ma il priore cross-lingua rende più facile generalizzare da pochi esempi e aumenta la similarità tra coppie entità giapponese–inglese da livelli moderati a livelli molto alti.
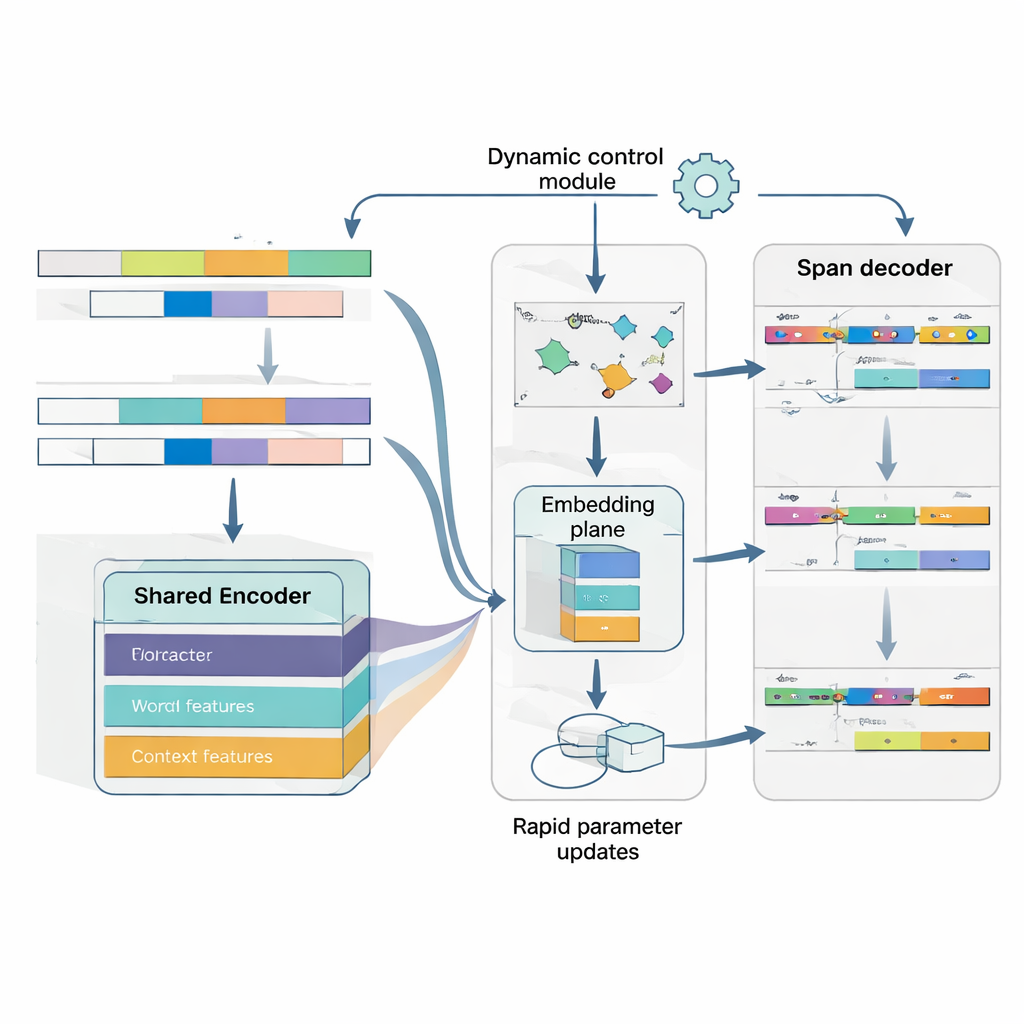
Imparare a imparare con solo pochi esempi
Il cuore di MAML‑ProtoNet++ è una strategia di “imparare a imparare”. Invece di addestrare una volta su un enorme dataset, il modello si esercita su molti piccoli compiti che simulano veri scenari few-shot: date poche frasi etichettate e un piccolo set di test, adattarsi rapidamente. Vengono combinate due idee note. La prima, una componente di rapida adattazione, aggiusta i parametri del modello con pochi passi di gradiente in modo da adattarsi a ciascun nuovo compito. La seconda, una componente basata su prototipi, costruisce un vettore rappresentativo per ogni tipo di entità e classifica nuovi span in base alla distanza da questi prototipi. Una rete di controllo separata valuta quanto sia difficile un compito—basandosi sui pochi esempi etichettati—e regola automaticamente i tassi di apprendimento, le scale di distanza e quanto fidarsi dei diversi livelli di caratteristiche (caratteri, parole o contesto completo). Questo controllo dinamico aiuta il sistema a rimanere stabile ed efficace anche quando i compiti variano molto.
Capire insieme dove è un’entità e cosa rappresenta
Infine, il modello tratta il rilevamento dei confini e l’assegnazione del tipo come un unico problema coordinato invece che come due passaggi separati. Predice prima le posizioni di inizio probabili per le entità in una frase, poi, condizionandosi su quegli inizi, prevede posizioni di fine plausibili e infine classifica gli span risultanti nei tipi di entità. Possono essere considerate più porzioni sovrapposte, ma le regole di punteggio favoriscono quelle più coerenti. Modellando esplicitamente la dipendenza tra inizio, fine e categoria, il sistema diventa migliore nel gestire entità annidate o ambigue—un ostacolo comune nel giapponese. Una funzione di perdita congiunta addestra tutte e tre le decisioni insieme, migliorando sia l’accuratezza dei confini sia le etichette finali.
Cosa significano i risultati nella pratica
Quando testato su diversi benchmark giapponesi che simulano la disponibilità di solo cinque esempi etichettati per tipo di entità, MAML‑ProtoNet++ supera forti baseline, includendo il fine-tuning standard, metodi meta-learning precedenti e l’addestramento contrastivo da solo. Raggiunge un punteggio macro F1 di circa 0,77 nell’impostazione più impegnativa e ottiene un’accuratezza notevole sugli esatti punti di inizio e fine delle entità. L’approccio si trasferisce anche bene a nuovi domini, come testi biomedici e di news, senza grandi re-addestramenti. Per un lettore non tecnico, la conclusione è che gli autori hanno costruito un sistema compatto ed efficiente in grado di imparare a riconoscere nomi e altri termini chiave nel testo giapponese con pochissima supervisione, generando in modo intelligente esempi aggiuntivi, prendendo indizi cross-lingua e adattando dinamicamente il modo in cui apprende.
Citazione: Shao, X., Zhu, D., Liu, Q. et al. A joint span-entity prediction approach with generative and cross-lingual meta-learning for low-resource Japanese NER. Sci Rep 16, 10281 (2026). https://doi.org/10.1038/s41598-026-41621-0
Parole chiave: riconoscimento delle entità denominate giapponese, few-shot learning, NLP cross-lingua, meta-apprendimento, aumento dei dati