Clear Sky Science · he
שיטת חיזוי משותפת טווח-ישות עם למידת-מטא גנרטיבית ורב-לשונית לזיהוי ישויות בשפה היפנית במשאבים דלים
ללמד מחשבים לזהות שמות בטקסט יפני
מידע מקוון מלא בשמות של אנשים, מקומות, חברות ותאריכים, ותוכנה שמאתרת באופן אוטומטי את הרמזים של “מי, היכן ומתי” חשובה למנועי חיפוש, פיננסים, רפואה ועוד. בעוד שבאנגלית קיימים מאגרי נתונים רבים לאימון מערכות כאלה, היפנית יוצרת אתגר מיוחד: היא חסרת רווחים בין מילים ובעלת דפוסי כתיבה מורכבים. המחקר הזה מציג שיטה חדשה, בשם MAML‑ProtoNet++, שעוזרת למחשבים ללמוד לזהות ישויות שמיות ביפנית גם כאשר זמינים רק מספר מועט של דוגמאות מתויגות.
למה יפנית מסובכת במיוחד
בשפות אירופיות רבות רווחים מפרידים בין מילים, ולכן האלגוריתמים יכולים ביתר קלות לשער היכן מונח מסתיים ואחר מתחיל. משפטים ביפנית, לעומת זאת, נכתבים כזרם רציף של תווים. שמות יכולים להיות ארוכים, מורכבים מרכיבים מרובים ומשתנים בהתאם להקשר. רשתות נוירוניות מסורתיות, גם מודלים רב-לשוניים חזקים, מתקשות להחליט היכן מתחילה ומסתיימת ישות ומה סוגה. הן גם תלויות במידה רבה במערכי נתונים מתויגים גדולים, שאינם זמינים בקלות עבור יפנית. כתוצאה מכך, מערכות קיימות לעתים קרובות מפצלות ארגון לקטעים, מפספסות קשרים לטווח ארוך במשפט או מתקשות להעביר יכולת מאימון באנגלית לטקסט יפני.
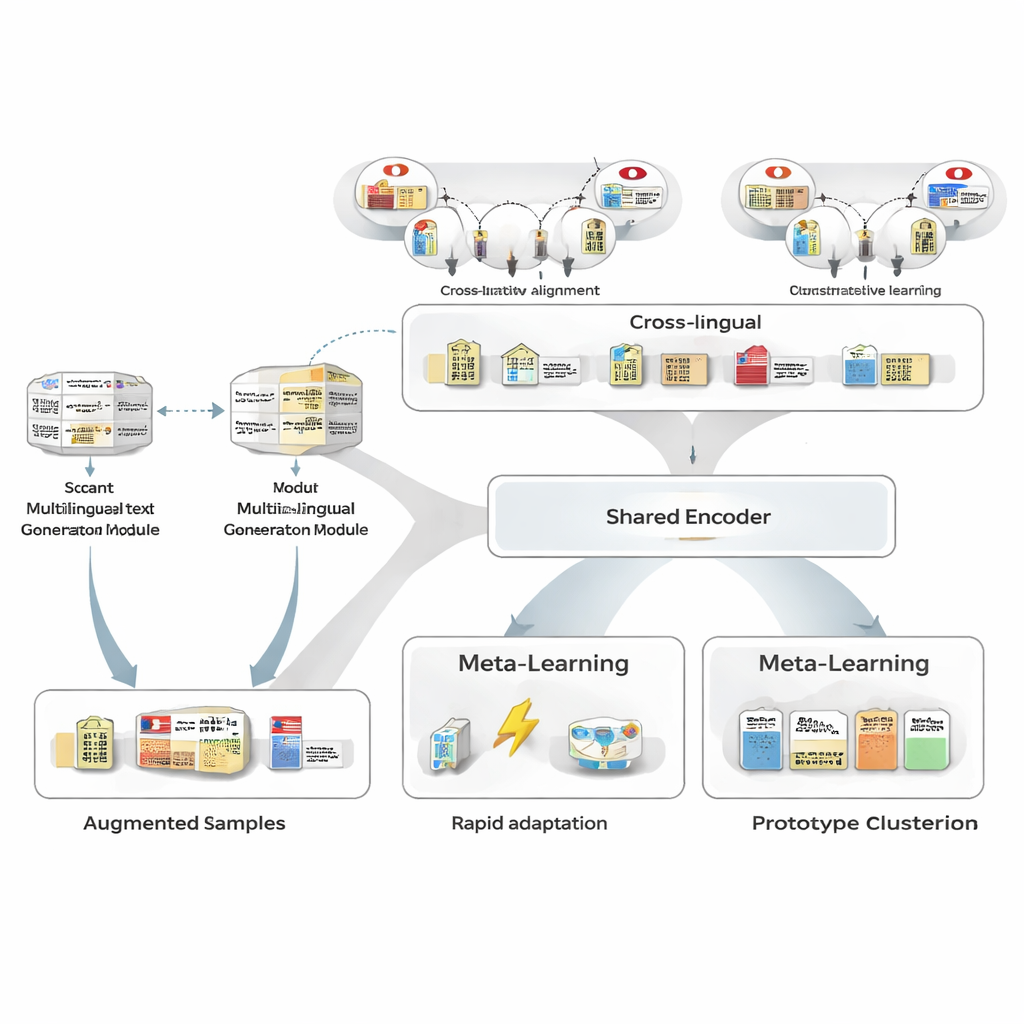
להפיק דוגמאות נוספות בלי תוויות אנושיות רבות
כדי להתגבר על חוסר הנתונים, המחברים תחילה משתמשים בגנרטור טקסט רב-לשוני כדי לשכתב את משפטי היפנית המתויגים המועטים שישנם. הגנרטור מייצר גרסאות חדשות ששומרות על אותן ישויות וסוגים אך משנות את הניסוח: ניסוח מחדש של משפטים, החלפת אזכורי ישויות באחרות דומות או שינוי ההקשר הסובב. צינור סינון זהיר מסנן אחר שכתובי-לוואי רעים באמצעות שלושה מבחנים: בדיקת ביטחון מטאגר (tagger) נפרד, בדיקה שהגבולות והסוגים של הישויות עדיין תואמים למקור ובחינת דמיון סמנטי שמונעת כפילויות כמעט זהות. המשפטים הסינתטיים ששרדו מרחיבים את גיוון הדפוסים שהמודל רואה, משפרים את העמידות תוך שמירה על רעש תיוג נמוך מאוד.
להשאיל כוח בין שפות
בהמשך, המסגרת לומדת ליישר בין ישויות יפניות לבין מקבילותיהן בשפות אחרות באמצעות בסיס ידע גדול. זוגות כגון “ממשלת מטרופולין טוקיו” ביפנית ובסינית ממופים למרחב מתמטי משותף כך שנקודות של ישויות תואמות יקרבו זו לזו ואילו לא תואמות ידחפו זו מרחוק. אימון קונטרסטיבי זה לא מנסה לקודד את כל הידע הדומייני; במקום זאת, הוא נותן למודל שלד שאינו תלוּי שפה כך שמושגים דומים ייראו דומים ללא תלות בשפה. בהמשך, במהלך אימון משימה-ספציפי, הסופרויז'ן היפני יכול לעצב מחדש מרחב זה, אך האבחנה הרב-לשונית מקלה על הכללה ממעט דוגמאות ומשפרת את הדמיון בין זוגות ישויות יפנית–אנגלית מרמות בינוניות לרמות גבוהות מאוד.
ללמוד איך ללמוד ממעט דוגמאות
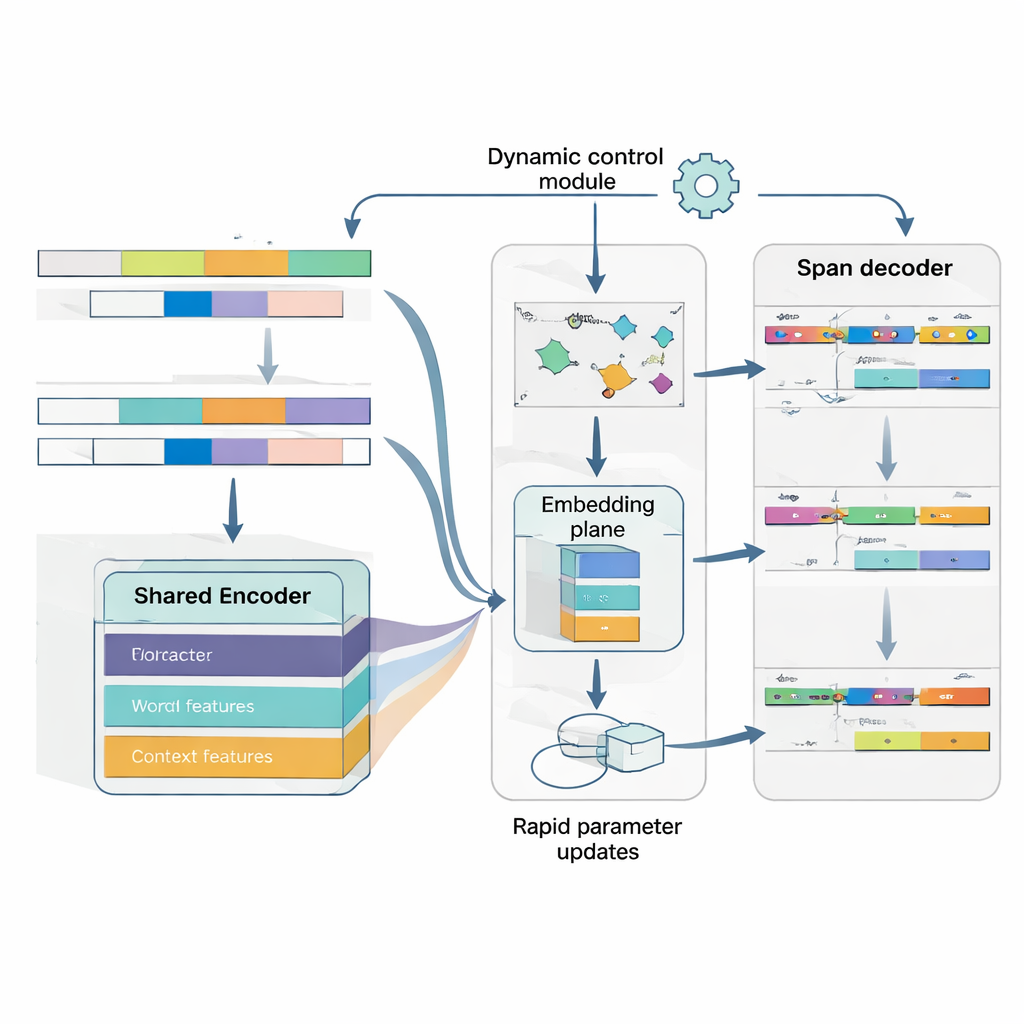
ליבת MAML‑ProtoNet++ היא אסטרטגיית “למידה ללמוד”. במקום להתאמן פעם אחת על מאגר עצום, המודל מתרגל על הרבה משימות קטנות שמדמות תרחישי few-shot אמיתיים: בהתחשב בכמה משפטים מתויגים וקבוצת מבחן קטנה, להתאים במהירות. משולבות שתי רעיונות ידועים. האחד, רכיב התאמה מהירה, מתאים פרמטרים של המודל בכמה צעדי גרדיאנט כדי להתמקד במהירות במשימה חדשה. השני, רכיב מבוסס-פרוטוטיפ בונה וקטור מייצג לכל סוג ישות וממיין קטעים חדשים לפי מרחק לפרוטוטיפים אלה. רשת בקרה נפרדת בוחנת כמה קשה המשימה—בהסתמך על הדוגמאות המעטות—ואז מתאימה אוטומטית שיעורי למידה, קני מידה של מרחק וכמה לסמוך על רמות תכונה שונות (תווים, מילים או הקשר מלא). בקרה דינמית זו עוזרת למערכת להישאר יציבה ויעילה גם כאשר המשימות שונות מאוד אחת מהשנייה.
להבין גם היכן יש ישות וגם מה היא
לבסוף, המודל מתייחס לזיהוי גבולות והקצאת סוג כבעיה משותפת ומתואמת במקום כשני שלבים נפרדים. הוא מנבא תחילה מיקומי התחלה סבירים לישויות במשפט, לאחר מכן, בהתניות על התחלה אלה, מנבא מיקומי סיום אפשריים, ואז מסווג את הקטעים המתקבלים לסוגי ישויות. ניתן לשקול כמה קטעים החופפים, אך כללי ניקוד מעדיפים את הקוהרנטיים ביותר. על ידי מודלפורמה מפורשת של התלות בין התחלה, סוף וקטגוריה, המערכת משתפרת בטיפול בישויות מקוננות או עמומות—מכשול נפוץ ביפנית. פונקציית אובדן משותפת מאמנת את שלוש ההחלטות יחד, ומשפרת הן את הדיוק בגבולות והן את התוויות הסופיות.
מה המשמעות של התוצאות בפועל
במבחנים על מספר מאגרי יפנית המדמים מצב בו יש רק חמש דוגמאות מתויגות לכל סוג ישות, MAML‑ProtoNet++ עולה על בסיסים חזקים, כולל כוונון-עד סטנדרטי, שיטות למידת-מטא מוקדמות ואימון קונטרסטיבי בלבד. הוא מגיע לציון macro F1 של כ־0.77 בהגדרה המאתגרת ביותר ומשיג דיוק גבוה במיוחד בזיהוי תחילת וסיום מדויקים של ישויות. הגישה גם עוברת היטב לתחומים חדשים, כגון ביו-רפואה וטקסט חדשותי, ללא אימון מחדש נרחב. לקורא כללי, המסקנה היא שהמחברים בנו מערכת קומפקטית ויעילה שיכולה ללמוד לזהות שמות ומונחים מרכזיים בטקסט יפני מתוך מעט מאד הדרכה, על ידי יצירת דוגמאות נוספות באופן חכם, השאלת רמזים רב-לשוניים והתאמת אופן הלמידה בזמן אמת.
ציטוט: Shao, X., Zhu, D., Liu, Q. et al. A joint span-entity prediction approach with generative and cross-lingual meta-learning for low-resource Japanese NER. Sci Rep 16, 10281 (2026). https://doi.org/10.1038/s41598-026-41621-0
מילות מפתח: זיהוי ישויות שמיות ביפנית, למידה ממעט דוגמאות, עיבוד שפה טבעית רב-לשוני, למידת-מטא, העשיית נתונים