Clear Sky Science · tr
Az kaynaklı Japonca NER için üretken ve çapraz-dilli meta-öğrenmeyle birleşik span-varlık tahmin yaklaşımı
Bilgisayarlara Japonca metinde isimleri öğretmek
Çevrimiçi bilgiler kişi, yer, şirket ve tarihler gibi isimlerle doludur; bu “kim, nerede ve ne zaman” ipuçlarını otomatik olarak bulabilen yazılımlar arama motorları, finans, tıp ve daha fazlası için hayati öneme sahiptir. Ancak İngilizce gibi dillerde bu sistemleri eğitmek için bol miktarda veri varken, Japonca özel zorluklar taşır: kelimeler arasında boşluk yoktur ve karmaşık yazım örüntüleri vardır. Bu çalışma, yalnızca birkaç etiketli örnek mevcut olduğunda bile bilgisayarların Japonca adlandırılmış varlıkları tanımayı öğrenmesine yardımcı olan MAML‑ProtoNet++ adlı yeni bir yöntem sunar.
Neden Japonca Özellikle Zordur
Birçok Avrupa dilinde kelimeler boşluklarla ayrılır; bu yüzden algoritmalar bir terimin nerede bittiğini ve diğerinin nerede başladığını tahmin etmekte daha kolaydır. Japonca cümleler ise karakterlerin kesintisiz akışı şeklinde yazılır. İsimler uzun olabilir, birden çok parçadan oluşabilir ve bağlama göre biçim değiştirebilir. Geleneksel sinir ağları, güçlü çokdilli modeller bile, bir varlığın nerede başlayıp bittiğini ve hangi tür olduğunu belirlemekte zorlanır. Ayrıca büyük etiketli veri kümelerine güçlü biçimde bağlıdırlar; bu tür veriler Japonca için nadirdir. Sonuç olarak mevcut sistemler sıklıkla tek bir kuruluşu iki parçaya böler, cümledeki uzun menzilli ilişkileri kaçırır veya İngilizce merkezli eğitimden Japoncaya kötü aktarım yapar.
Daha Fazla İnsan Etiketi Olmadan Daha Fazla Örnek Üretmek
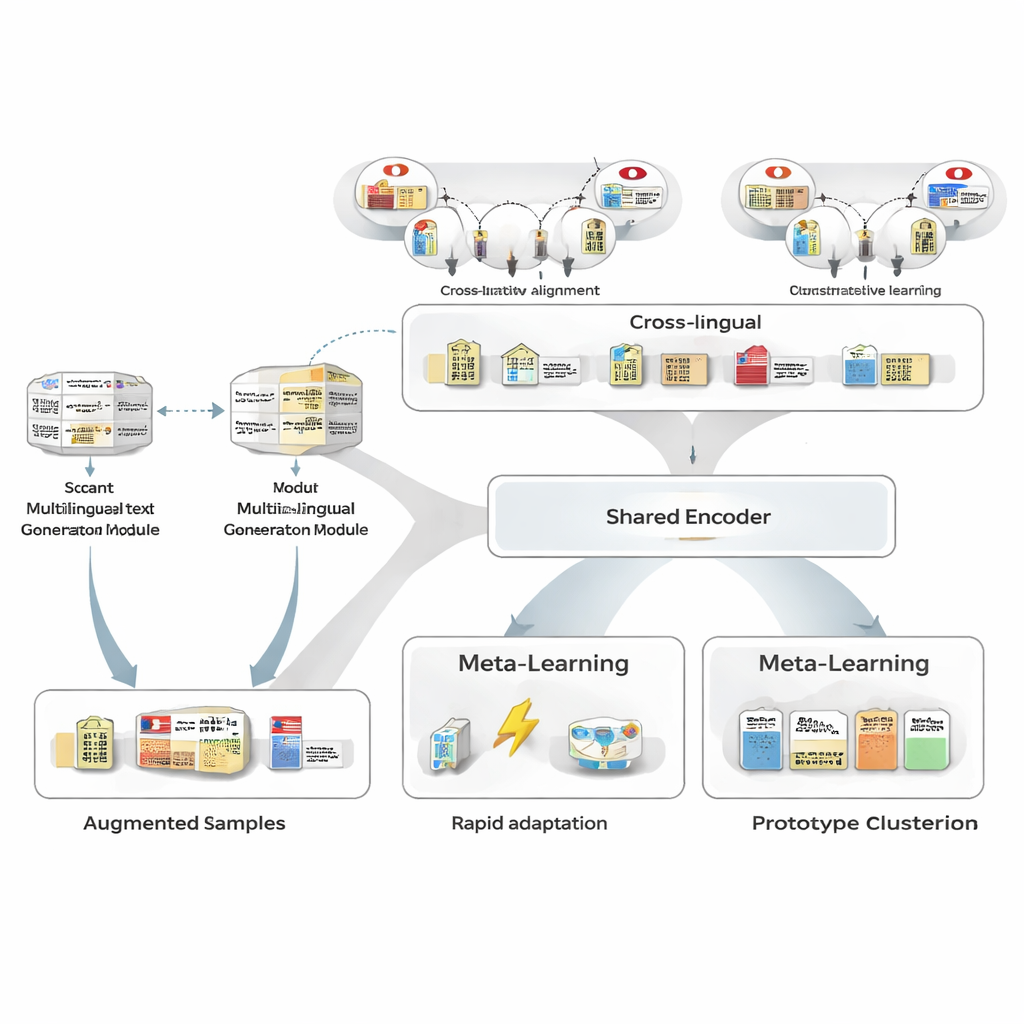
Eğitim verisi eksikliğini aşmak için yazarlar önce sahip oldukları az sayıda etiketli Japonca cümleyi yeniden yazmak üzere çokdilli bir metin üreteci kullanır. Üreteç, aynı varlıkları ve türleri korurken ifade çeşitliliği sağlayan yeni versiyonlar üretir: cümleleri farklı biçimlendirme, varlık adlarını benzerleriyle değiştirme veya çevresel bağlamı değiştirme gibi. Ardından titiz bir filtreleme boru hattı, üç testle kötü yeniden yazımları eler: ayrı bir etiketleyiciden alınan güven kontrolü, varlık sınırları ve türlerin orijinal ile hâlâ eşleştiğini doğrulama ve neredeyse kopyaları önleyen anlamsal benzerlik testi. Kalan sentetik cümleler, modelin gördüğü desen çeşitliliğini genişleterek sağlamlığı arttırır ve etiket gürültüsünü çok düşük tutar.
Diller Arası Güçten Yararlanma
Sonraki adımda çerçeve, Japonca varlıkları büyük bir bilgi tabanındaki diğer dillerdeki karşılıklarıyla hizalamayı öğrenir. "Tokyo Metropolitan Government" gibi Japonca ve Çince örnekler paylaşılan bir matematiksel uzaya eşlenir; böylece eşleşen varlıklar birbirine yakın düşerken ilgisiz olanlar uzaklaşır. Bu kontrastif ön eğitim tüm alan bilgisini kodlamaya çalışmaz; bunun yerine benzer kavramların dilden bağımsız olarak benzer görünmesini sağlayan bir omurga sağlar. Daha sonra görev-özgü eğitim sırasında Japonca denetimi bu uzayı yeniden şekillendirebilir, ama çapraz-dilli ön bilgi az sayıda örnekten genelleme yapmayı kolaylaştırır ve Japonca–İngilizce varlık çiftleri arasındaki benzerliği ortalamadan çok yüksek seviyelere çıkarır.
Sadece Birkaç Örnekle Nasıl Öğrenileceğini Öğrenmek
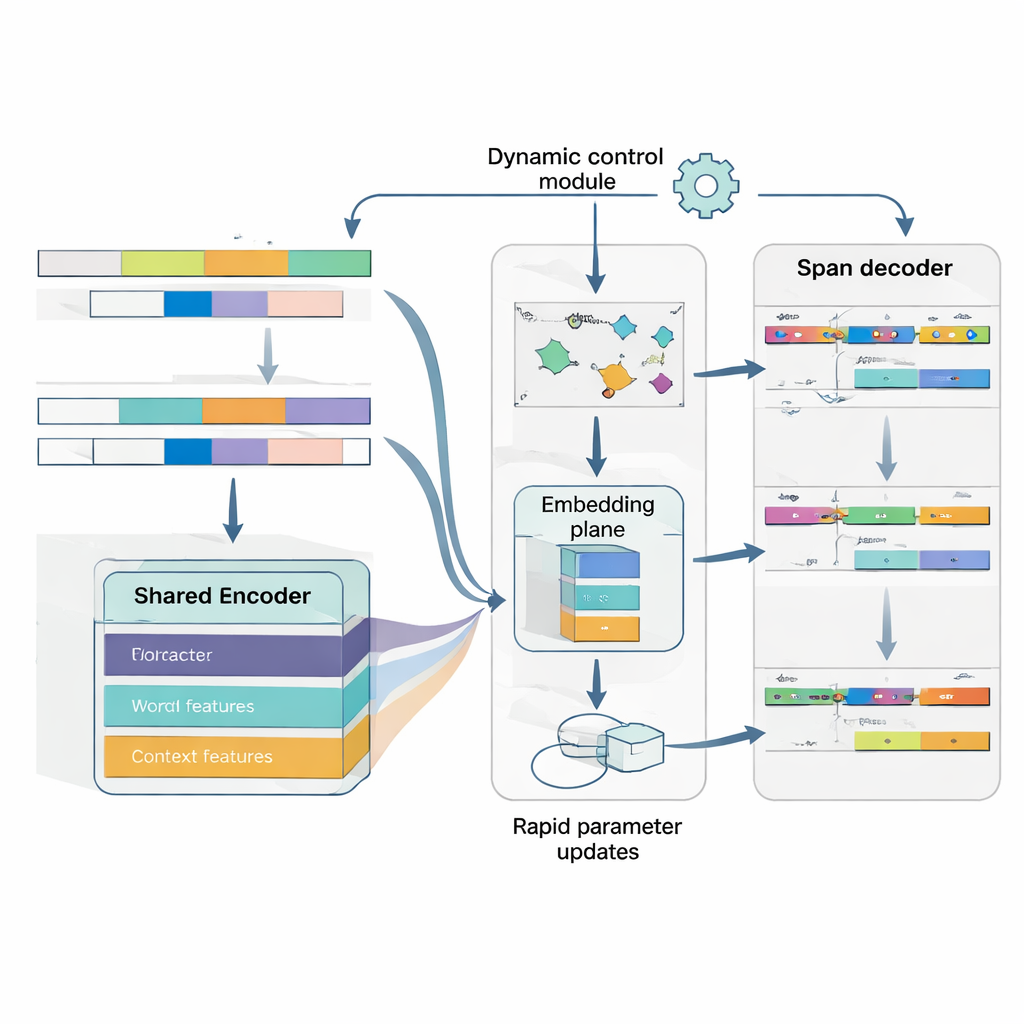
MAML‑ProtoNet++'un kalbinde "öğrenmeyi öğrenme" stratejisi vardır. Modeli bir kez büyük bir veri kümesi üzerinde eğitmek yerine, model gerçek az-örnek senaryolarını taklit eden birçok küçük görev üzerinde pratik yapar: birkaç etiketli cümle ve küçük bir test seti verildiğinde hızla uyum sağlar. İki iyi bilinen fikir birleştirilir. Birincisi, hızlı uyum bileşeni, birkaç gradyan adımıyla model parametrelerini ayarlayarak her yeni göreve kendini hızla uydurmasını sağlar. İkincisi, prototip tabanlı bileşen her varlık türü için temsil edici bir vektör oluşturur ve yeni span’leri bu prototiplere uzaklığa göre sınıflandırır. Ayrı bir kontrol ağı, görevin zorluğunu—az sayıda etiketli örneğe dayanarak—değerlendirir ve ardından otomatik olarak öğrenme oranlarını, mesafe ölçeklerini ve farklı özellik düzeylerine (karakterler, kelimeler veya tam bağlam) ne kadar güvenileceğini ayarlar. Bu dinamik kontrol, görevler geniş ölçüde değişse bile sistemi istikrarlı ve etkili kılar.
Bir Varlığın Nerede Olduğunu ve Ne Olduğunu Aynı Anda Anlamak
Son olarak model, sınır tespiti ile tür atamasını iki ayrı adım yerine tek, koordine bir problem olarak ele alır. İlk önce bir cümledeki varlıklar için muhtemel başlangıç pozisyonlarını tahmin eder; daha sonra bu başlangıçlara koşullandırılarak muhtemel bitiş pozisyonlarını tahmin eder ve ortaya çıkan span’leri varlık türlerine sınıflandırır. Birden çok örtüşen span dikkate alınabilir, ancak puanlama kuralları en tutarlı olanları tercih eder. Başlangıç, bitiş ve kategori arasındaki bağı açıkça modelleyerek sistem, Japonca’da yaygın olan iç içe geçmiş veya belirsiz varlıkların üstesinden gelmede daha başarılı olur. Ortak bir kayıp fonksiyonu bu üç kararı birlikte eğitir ve hem sınır doğruluğunu hem de nihai etiketleri iyileştirir.
Sonuçların Uygulamadaki Anlamı
Her varlık türü için sadece beş etiketli örnek bulunan senaryoları simüle eden birkaç Japonca benchmark üzerinde test edildiğinde, MAML‑ProtoNet++ standart ince ayar, önceki meta-öğrenme yöntemleri ve yalnızca kontrastif eğitim de dahil olmak üzere güçlü karşıtlarını geride bırakır. En zorlu ayarda yaklaşık 0,77 makro F1 puanına ulaşır ve varlıkların tam başlangıç ve bitiş konumlarında kayda değer derecede yüksek doğruluk sağlar. Yöntem ayrıca biyomedikal ve haber metni gibi yeni alanlara büyük yeniden eğitim gerektirmeden iyi aktarılır. Genel okuyucu için çıkarım şudur: Yazarlar, çok az rehberlikle Japonca metinde isimleri ve diğer anahtar terimleri seçmeyi öğrenebilen, kompakt ve verimli bir sistem geliştirmiştir; bunu akıllıca ek örnekler üreterek, diller arası ipuçlarından ödünç alarak ve öğrenme şeklini dinamik olarak ayarlayarak başarır.
Atıf: Shao, X., Zhu, D., Liu, Q. et al. A joint span-entity prediction approach with generative and cross-lingual meta-learning for low-resource Japanese NER. Sci Rep 16, 10281 (2026). https://doi.org/10.1038/s41598-026-41621-0
Anahtar kelimeler: Japonca adlandırılmış varlık tanıma, az örnekli öğrenme, çapraz-dilli NLP, meta-öğrenme, veri artırma