Clear Sky Science · pt
Uma abordagem conjunta de predição de span-entidade com meta-aprendizagem generativa e cruzada para NER em japonês com poucos recursos
Ensinando computadores a identificar nomes em texto japonês
Informações online estão repletas de nomes de pessoas, lugares, empresas e datas, e softwares capazes de encontrar automaticamente essas pistas de “quem, onde e quando” são essenciais para mecanismos de busca, finanças, medicina e muito mais. Mas enquanto o inglês dispõe de muitos dados para treinar esses sistemas, o japonês apresenta um desafio especial: não possui espaços entre palavras e tem padrões de escrita complexos. Este estudo introduz um novo método, chamado MAML‑ProtoNet++, que ajuda computadores a reconhecer entidades nomeadas em japonês mesmo quando há apenas alguns exemplos rotulados disponíveis.
Por que o japonês é especialmente complicado
Em muitas línguas europeias, espaços separam as palavras, de modo que algoritmos conseguem mais facilmente inferir onde um termo termina e outro começa. Sentenças em japonês, no entanto, são escritas como fluxos contínuos de caracteres. Nomes podem ser longos, compostos por múltiplas partes, e variar de forma conforme o contexto. Redes neurais tradicionais, mesmo modelos multilíngues poderosos, têm dificuldade para decidir onde uma entidade começa e termina e qual é seu tipo. Elas também dependem fortemente de grandes conjuntos de dados rotulados, que são escassos para o japonês. Como resultado, sistemas existentes frequentemente dividem uma única organização em duas partes, deixam de capturar relações de longo alcance em uma frase ou transferem mal o aprendizado treinado em inglês para textos em japonês.
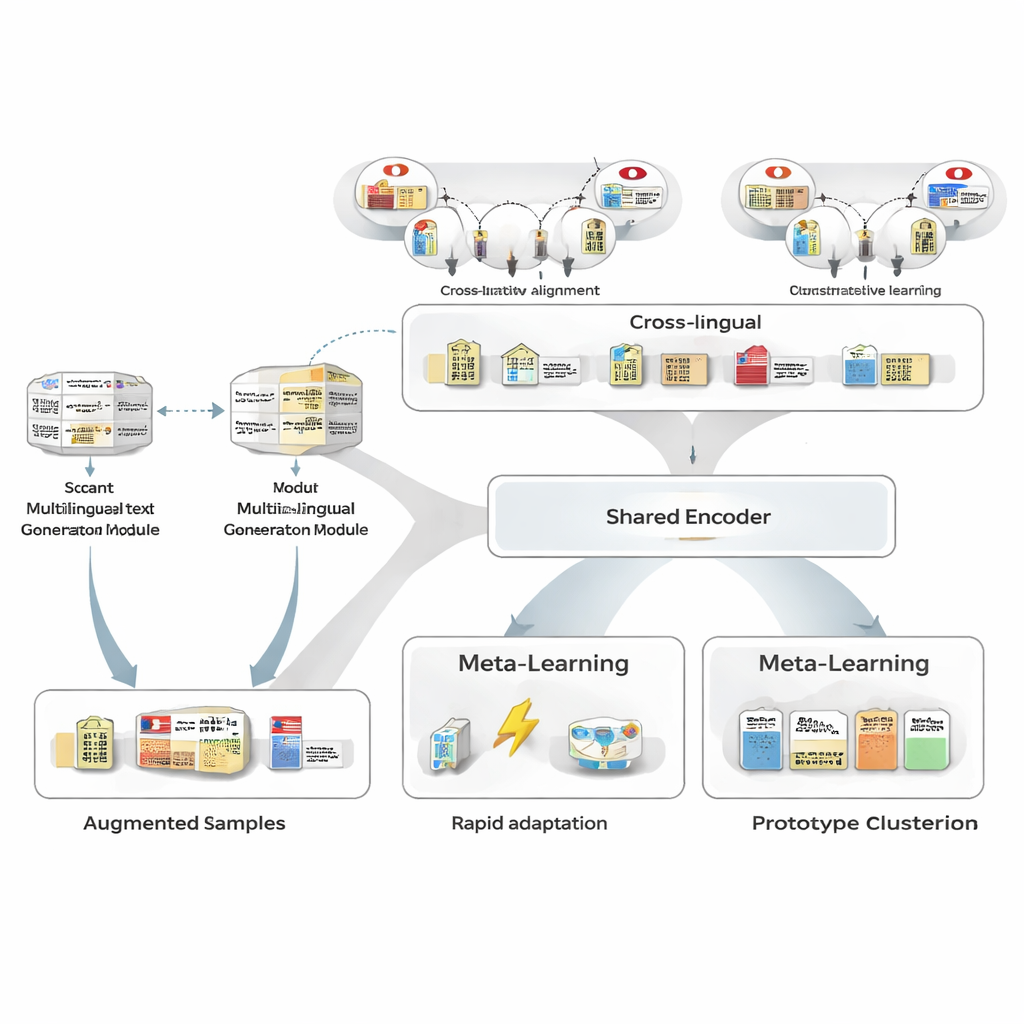
Gerando mais exemplos sem mais rotulagem humana
Para contornar a falta de dados de treinamento, os autores primeiro usam um gerador de texto multilíngue para reescrever as poucas sentenças japonesas anotadas que possuem. O gerador produz novas versões que preservam as mesmas entidades e tipos, mas variam a formulação: reformulando sentenças, substituindo menções de entidades por similares ou mudando o contexto circundante. Um pipeline de filtragem cuidadoso então elimina reescritas ruins usando três testes: uma verificação de confiança feita por um anotador separado, uma checagem de que os limites e tipos das entidades ainda correspondem ao original e um teste de similaridade semântica que evita quase-duplicatas. As sentenças sintéticas que sobrevivem ampliam a gama de padrões vistos pelo modelo, melhorando a robustez enquanto mantêm o ruído de rótulo muito baixo.
Tomando emprestado conhecimento entre línguas
Em seguida, a estrutura aprende a alinhar entidades japonesas com suas contrapartes em outras línguas usando uma grande base de conhecimento. Pares como “Tokyo Metropolitan Government” em japonês e em chinês são mapeados para um espaço matemático compartilhado para que entidades correspondentes fiquem próximas e as não relacionadas sejam empurradas para longe. Este pré-treinamento contrastivo não tenta codificar todo o conhecimento de domínio; em vez disso, dá ao modelo uma espinha dorsal independente de idioma para que conceitos similares pareçam similares independentemente da língua. Mais adiante, durante o treinamento específico da tarefa, a supervisão em japonês pode remodelar esse espaço, mas o prior cross-lingual facilita a generalização a partir de poucos exemplos e melhora a similaridade entre pares de entidades japonês–inglês de níveis moderados para muito altos.
Aprendendo a aprender com apenas alguns exemplos
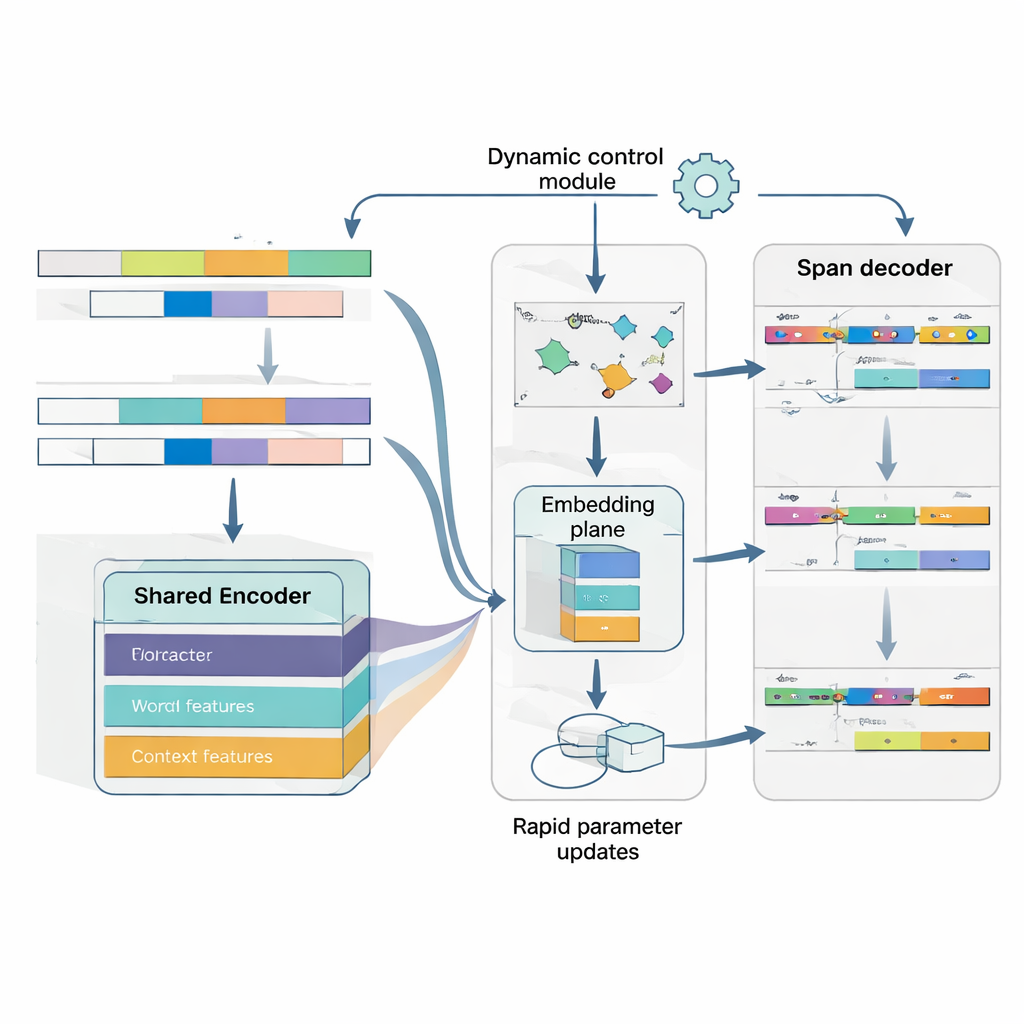
O cerne do MAML‑ProtoNet++ é uma estratégia de “aprender a aprender”. Em vez de treinar uma vez em um grande conjunto de dados, o modelo pratica em muitas tarefas pequenas que imitam cenários reais de few-shot: dadas algumas sentenças rotuladas e um pequeno conjunto de teste, adaptar-se rapidamente. Duas ideias bem conhecidas são combinadas. Uma, um componente de adaptação rápida, ajusta parâmetros do modelo com alguns passos de gradiente para que ele possa se adaptar a cada nova tarefa. Outra, um componente baseado em protótipos constrói um vetor representativo para cada tipo de entidade e classifica novos spans pela distância a esses protótipos. Uma rede de controle separada avalia a dificuldade aparente de uma tarefa—com base em seus poucos exemplos rotulados—e então ajusta automaticamente taxas de aprendizado, escalas de distância e quanto confiar em diferentes níveis de características (caracteres, palavras ou contexto completo). Esse controle dinâmico ajuda o sistema a permanecer estável e eficaz mesmo quando as tarefas variam bastante.
Entendendo tanto onde uma entidade está quanto o que ela é
Finalmente, o modelo trata a detecção de limites e a atribuição de tipo como um único problema coordenado em vez de dois passos separados. Primeiro prevê posições prováveis de início de entidades em uma frase, então, condicionado nesses inícios, prevê posições de fim plausíveis e, em seguida, classifica os spans resultantes em tipos de entidade. Vários spans sobrepostos podem ser considerados, mas regras de pontuação favorecem os mais coerentes. Ao modelar explicitamente a dependência entre início, fim e categoria, o sistema fica melhor em lidar com entidades aninhadas ou ambíguas—um obstáculo comum no japonês. Uma função de perda conjunta treina as três decisões ao mesmo tempo, melhorando tanto a precisão dos limites quanto os rótulos finais.
O que os resultados significam na prática
Quando testado em vários benchmarks japoneses que simulam ter apenas cinco exemplos rotulados por tipo de entidade, o MAML‑ProtoNet++ supera linhas de base fortes, incluindo fine-tuning padrão, métodos anteriores de meta-aprendizagem e apenas treinamento contrastivo. Ele alcança uma pontuação macro F1 de cerca de 0,77 no cenário mais desafiador e obtém precisão notavelmente alta no início e fim exatos das entidades. A abordagem também transfere bem para novos domínios, como textos biomédicos e notícias, sem grande retreinamento. Para um leitor leigo, a conclusão é que os autores construíram um sistema compacto e eficiente que pode aprender a identificar nomes e outros termos-chave em textos japoneses a partir de muito pouca orientação, gerando exemplos extras de forma inteligente, tomando dicas cross-lingual e ajustando dinamicamente seu processo de aprendizado.
Citação: Shao, X., Zhu, D., Liu, Q. et al. A joint span-entity prediction approach with generative and cross-lingual meta-learning for low-resource Japanese NER. Sci Rep 16, 10281 (2026). https://doi.org/10.1038/s41598-026-41621-0
Palavras-chave: reconhecimento de entidades nomeadas em japonês, aprendizado com poucos exemplos, PNL cross-lingual, meta-aprendizagem, aumento de dados