Clear Sky Science · de
Ein gemeinsamer Span‑Entity‑Vorhersageansatz mit generativem und rundsprachenübergreifendem Meta‑Learning für japanisches NER mit geringem Ressourcenaufwand
Computern beibringen, Namen in japanischem Text zu erkennen
Im Internet finden sich zahlreiche Namen von Personen, Orten, Firmen und Daten, und Software, die diese „wer, wo und wann“-Hinweise automatisch erkennt, ist für Suchmaschinen, Finanzwesen, Medizin und mehr unverzichtbar. Während für Englisch reichlich Trainingsdaten verfügbar sind, stellt Japanisch eine besondere Herausforderung dar: Es fehlen Wortzwischenräume und die Schriftmuster sind komplex. Diese Studie stellt eine neue Methode vor, MAML‑ProtoNet++, die Computern hilft, benannte Entitäten im Japanischen zu erkennen, selbst wenn nur sehr wenige gelabelte Beispiele vorliegen.
Warum Japanisch besonders knifflig ist
In vielen europäischen Sprachen trennen Leerzeichen Wörter, sodass Algorithmen leichter abschätzen können, wo ein Begriff endet und ein anderer beginnt. Japanische Sätze dagegen sind als ununterbrochene Zeichenketten geschrieben. Namen können lang sein, aus mehreren Teilen bestehen und sich je nach Kontext verändern. Traditionelle neuronale Netze, selbst leistungsfähige multilinguale Modelle, tun sich schwer damit, wo eine Entität beginnt und endet und welche Klasse sie hat. Sie sind zudem stark auf große gelabelte Datensätze angewiesen, die für Japanisch selten sind. Folglich zerteilen bestehende Systeme oft eine Organisation in zwei Teile, übersehen langreichweitige Beziehungen im Satz oder übertragen aus dem auf Englisch basierenden Training schlecht auf japanische Texte.
Mehr Beispiele erzeugen, ohne mehr menschliche Labels
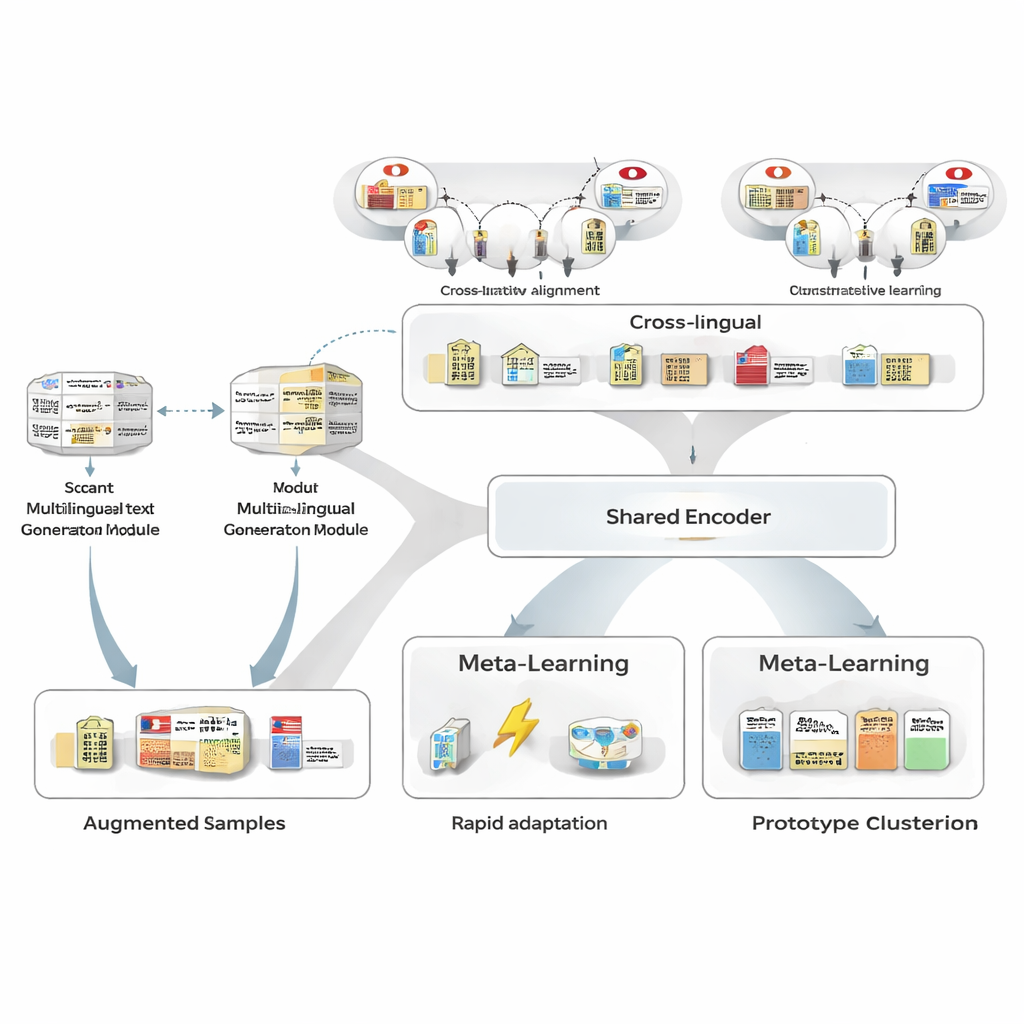
Um dem Mangel an Trainingsdaten zu begegnen, nutzen die Autoren zunächst einen multilingualen Textgenerator, um die wenigen annotierten japanischen Sätze umzuschreiben. Der Generator erstellt neue Varianten, die dieselben Entitäten und Typen beibehalten, aber die Formulierungen variieren: Umformulierungen, Austausch von Entitätsnennungen durch ähnliche Beispiele oder Änderungen des umgebenden Kontexts. Eine sorgfältige Filterpipeline sortiert fehlerhafte Umschreibungen anhand dreier Tests aus: eine Vertrauensprüfung durch einen separaten Tagger, eine Prüfung, ob Entitätsgrenzen und Typen noch mit dem Original übereinstimmen, und ein semantischer Ähnlichkeitstest, der nahezu identische Duplikate vermeidet. Die verbleibenden synthetischen Sätze erweitern die Muster, die das Modell sieht, erhöhen die Robustheit und halten das Label‑Rauschen sehr gering.
Stärke über Sprachen hinweg ausleihen
Als Nächstes lernt das Framework, japanische Entitäten mit ihren Gegenstücken in anderen Sprachen mithilfe einer großen Wissensdatenbank auszurichten. Paare wie „Tokyo Metropolitan Government“ auf Japanisch und Chinesisch werden in einen gemeinsamen mathematischen Raum abgebildet, sodass passende Entitäten nahe beieinander liegen und nicht verwandte auseinander gedrängt werden. Dieses kontrastive Pretraining versucht nicht, sämtliches Domänenwissen zu kodieren; es gibt dem Modell vielmehr ein sprachagnostisches Rückgrat, sodass ähnliche Konzepte unabhängig von der Sprache ähnlich erscheinen. Später, während des aufgabenspezifischen Trainings, kann japanische Aufsicht diesen Raum anpassen, aber die sprachenübergreifende Vorinformation erleichtert die Generalisierung von wenigen Beispielen und erhöht die Ähnlichkeit zwischen japanisch‑englischen Entitäten von moderaten zu sehr hohen Werten.
Wie man aus nur wenigen Beispielen lernt
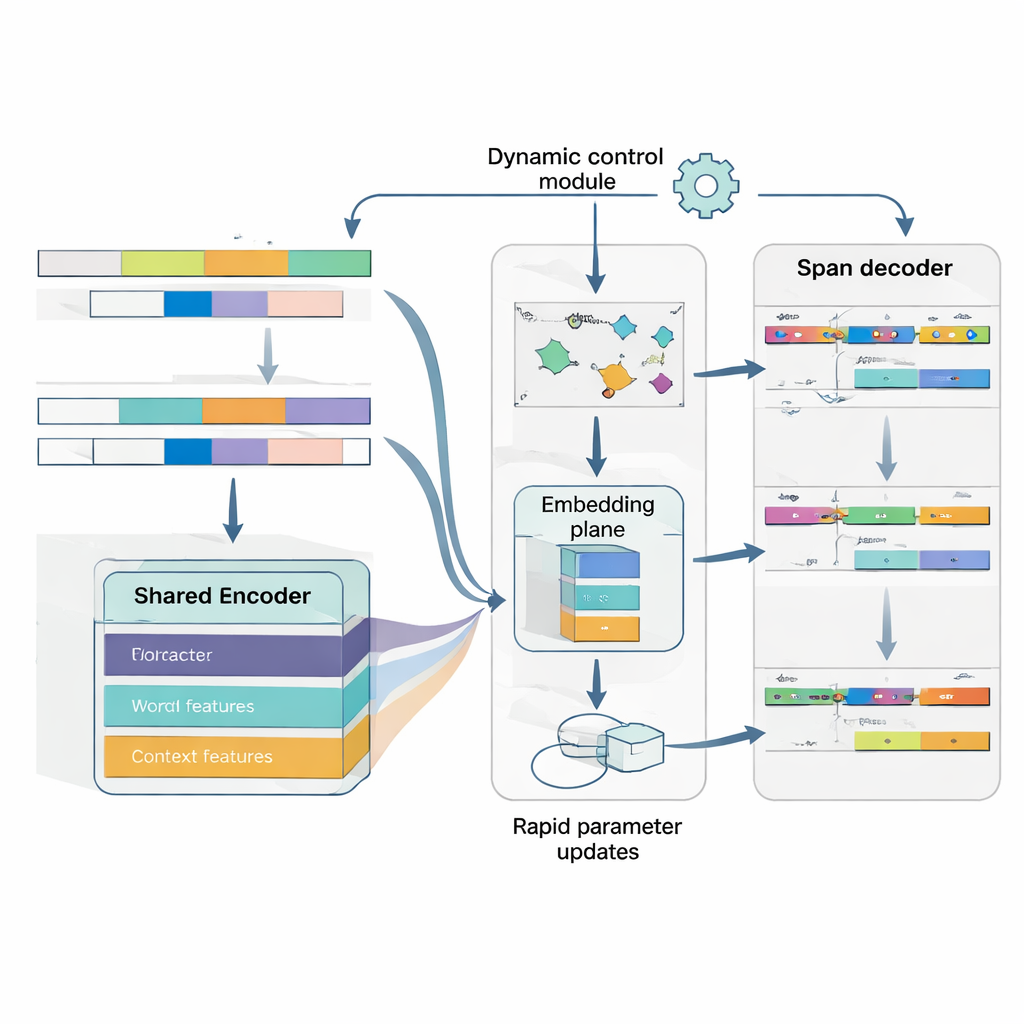
Der Kern von MAML‑ProtoNet++ ist eine „lernen zu lernen“-Strategie. Anstatt einmal auf einem riesigen Datensatz zu trainieren, übt das Modell an vielen winzigen Aufgaben, die echte Few‑Shot‑Szenarien nachahmen: Gegeben sind einige gelabelte Sätze und ein kleiner Testsatz, und das Modell soll sich schnell anpassen. Zwei bekannte Ideen werden kombiniert. Erstens ein Schnell‑Adaptions‑Mechanismus, der Modellparameter mit wenigen Gradienten‑Schritten anpasst, sodass es sich auf jede neue Aufgabe feinjustieren kann. Zweitens ein prototypbasierter Anteil, der für jeden Entitätstyp einen repräsentativen Vektor bildet und neue Spans anhand ihrer Distanz zu diesen Prototypen klassifiziert. Ein separates Steuerungsnetzwerk bewertet, wie schwierig eine Aufgabe wirkt — basierend auf ihren wenigen gelabelten Beispielen — und passt dann automatisch Lernraten, Distanzskalen und die Gewichtung verschiedener Merkmalebenen (Zeichen, Wörter oder voller Kontext) an. Diese dynamische Kontrolle hält das System stabil und effektiv, auch wenn die Aufgaben stark variieren.
Sowohl wo eine Entität ist als auch was sie ist, verstehen
Schließlich behandelt das Modell Grenzenerkennung und Typzuweisung als ein einziges, koordiniertes Problem statt als zwei getrennte Schritte. Zuerst sagt es wahrscheinliche Startpositionen für Entitäten in einem Satz voraus, dann, bedingt auf diesen Starts, mögliche Endpositionen und klassifiziert anschließend die resultierenden Spans in Entitätstypen. Mehrere überlappende Spans können in Betracht gezogen werden, doch Bewertungsregeln bevorzugen die kohärentesten. Indem die Abhängigkeit zwischen Start, Ende und Kategorie explizit modelliert wird, wird das System besser im Umgang mit verschachtelten oder mehrdeutigen Entitäten — ein häufiges Hindernis im Japanischen. Eine gemeinsame Verlustfunktion trainiert alle drei Entscheidungen zusammen und verbessert sowohl die Grenzgenauigkeit als auch die endgültigen Labels.
Was die Ergebnisse in der Praxis bedeuten
Getestet auf mehreren japanischen Benchmarks, die Szenarien mit nur fünf gelabelten Beispielen pro Entitätstyp simulieren, übertrifft MAML‑ProtoNet++ starke Baselines, einschließlich Standard‑Fine‑Tuning, früherer Meta‑Learning‑Methoden und rein kontrastiven Trainings. Es erreicht eine makro F1‑Punktzahl von etwa 0,77 in der herausforderndsten Einstellung und zeigt besonders hohe Genauigkeit bei den exakten Start‑ und Endpunkten von Entitäten. Der Ansatz überträgt sich zudem gut auf neue Domänen wie Biomedizin und Nachrichtentexte, ohne umfangreiches Nachtrainieren. Für eine interessierte Laienleserschaft lautet die Schlussfolgerung: Die Autoren haben ein kompaktes, effizientes System entwickelt, das aus sehr wenig Anleitung lernen kann, Namen und andere Schlüsselbegriffe in japanischem Text zu erkennen — durch kluge Erzeugung zusätzlicher Beispiele, sprachenübergreifende Hinweise und dynamische Anpassung des Lernens unterwegs.
Zitation: Shao, X., Zhu, D., Liu, Q. et al. A joint span-entity prediction approach with generative and cross-lingual meta-learning for low-resource Japanese NER. Sci Rep 16, 10281 (2026). https://doi.org/10.1038/s41598-026-41621-0
Schlüsselwörter: Japanische Named‑Entity‑Recognition, Few‑Shot‑Lernen, sprachenübergreifende NLP, Meta‑Learning, Datenerweiterung