Clear Sky Science · ja
低リソース日本語固有表現抽出のための生成的かつクロスリンガルなメタ学習を組み合わせた共同スパン実体予測手法
コンピュータに日本語テキスト中の固有名を見つけさせる
オンライン上の情報には人物名、地名、企業名、日付などの名前があふれており、こうした「誰が、どこで、いつ」の手がかりを自動で検出するソフトは検索、金融、医療などで不可欠です。しかし英語では学習用データが豊富にあるのに対し、日本語は語間にスペースがなく筆記体系も複雑で、特有の困難があります。本研究は MAML‑ProtoNet++ と呼ばれる新しい手法を提案し、ラベル付き例がごくわずかしかない状況でも日本語の固有表現を認識できるようにします。
日本語が特に扱いにくい理由
多くのヨーロッパ言語では語の区切りにスペースがあるため、アルゴリズムは語の境界を推定しやすいです。しかし日本語の文は文字が連続して書かれ、名前は複数の要素から成り長くなることがあり、文脈によって形が変わります。従来のニューラルネットワークや強力な多言語モデルでさえ、実体の開始・終了位置やタイプを判定するのに苦労します。さらに大量のラベル付きデータに依存しがちで、日本語向けのデータは不足しています。その結果、既存のシステムは組織名を二つに分割してしまったり、文中の長距離依存を見落としたり、英語中心の学習から日本語へうまく転移できなかったりします。
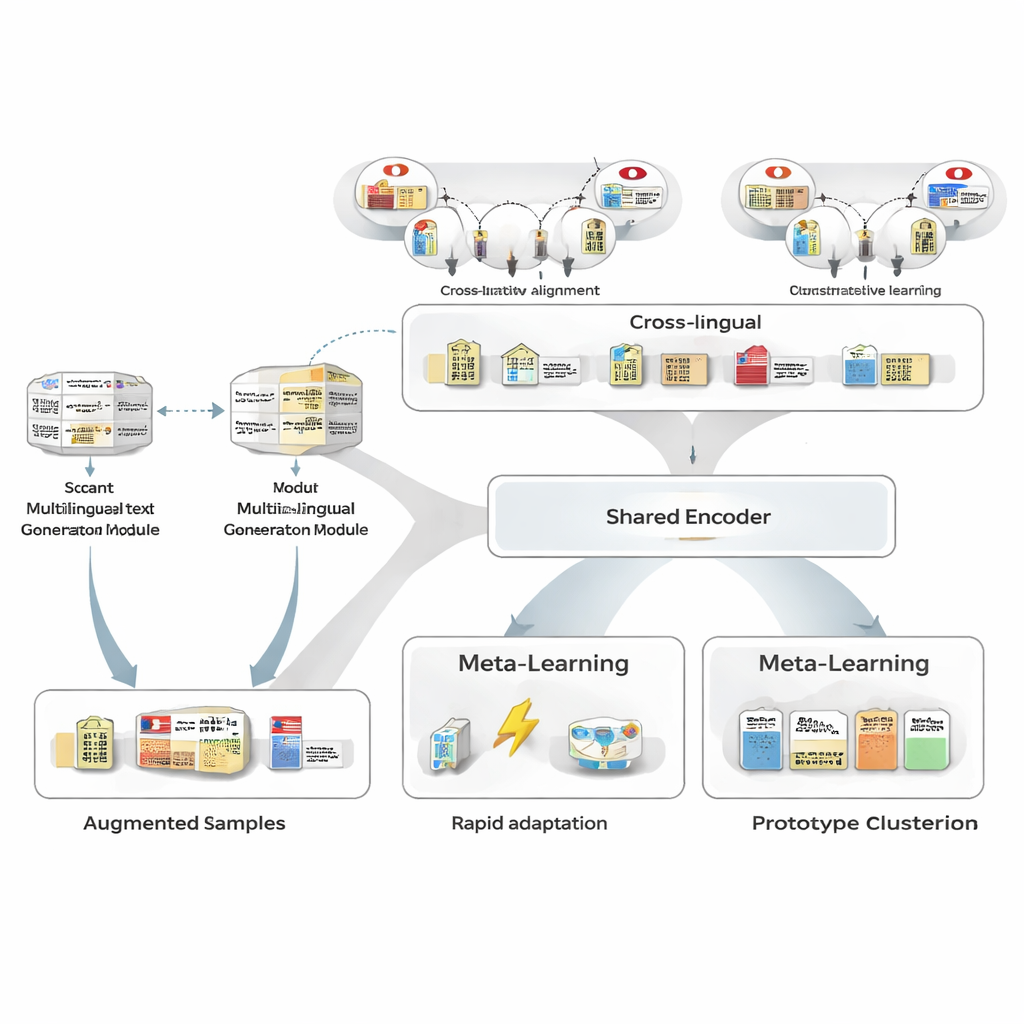
追加の人手ラベルなしに例を増やす
学習データ不足を克服するために、著者らはまず多言語テキスト生成器を使って、手元にある少数の注釈付き日本語文を言い換えます。生成器は実体とその種類を保ちながら文言を変え、文の言い換えや類似の実体表現との入れ替え、周囲の文脈の変更などを行います。続いて慎重なフィルタリングパイプラインで不適切な書き換えを除去します。フィルタは(1)別のタグ付け器による信頼度チェック、(2)実体境界とラベルが元と一致するかの確認、(3)近似重複を避ける意味的類似度テスト、の三つを行います。残った合成文はモデルが見るパターンの幅を広げ、堅牢性を向上させつつラベルノイズを非常に低く抑えます。
言語間で強みを借りる
次にフレームワークは大規模なナレッジベースを用いて日本語の実体と他言語の対応物を整合させることを学びます。たとえば「東京都庁」に相当する日本語と中国語の表現を共通のベクトル空間に写し、対応する実体が近く、無関係なものが遠くなるように学習します。このコントラスト的事前学習は全てのドメイン知識を符号化しようとするのではなく、言語に依存しないバックボーンを与えることで、似た概念が言語を越えて似た表現になるようにします。後のタスク固有学習で日本語の監督がこの空間を調整できますが、クロスリンガルな事前知識により少数例からの一般化が容易になり、日本語–英語の実体対の類似性が中程度から非常に高いレベルへと改善されます。
少数の例から学ぶ方法を学ぶ
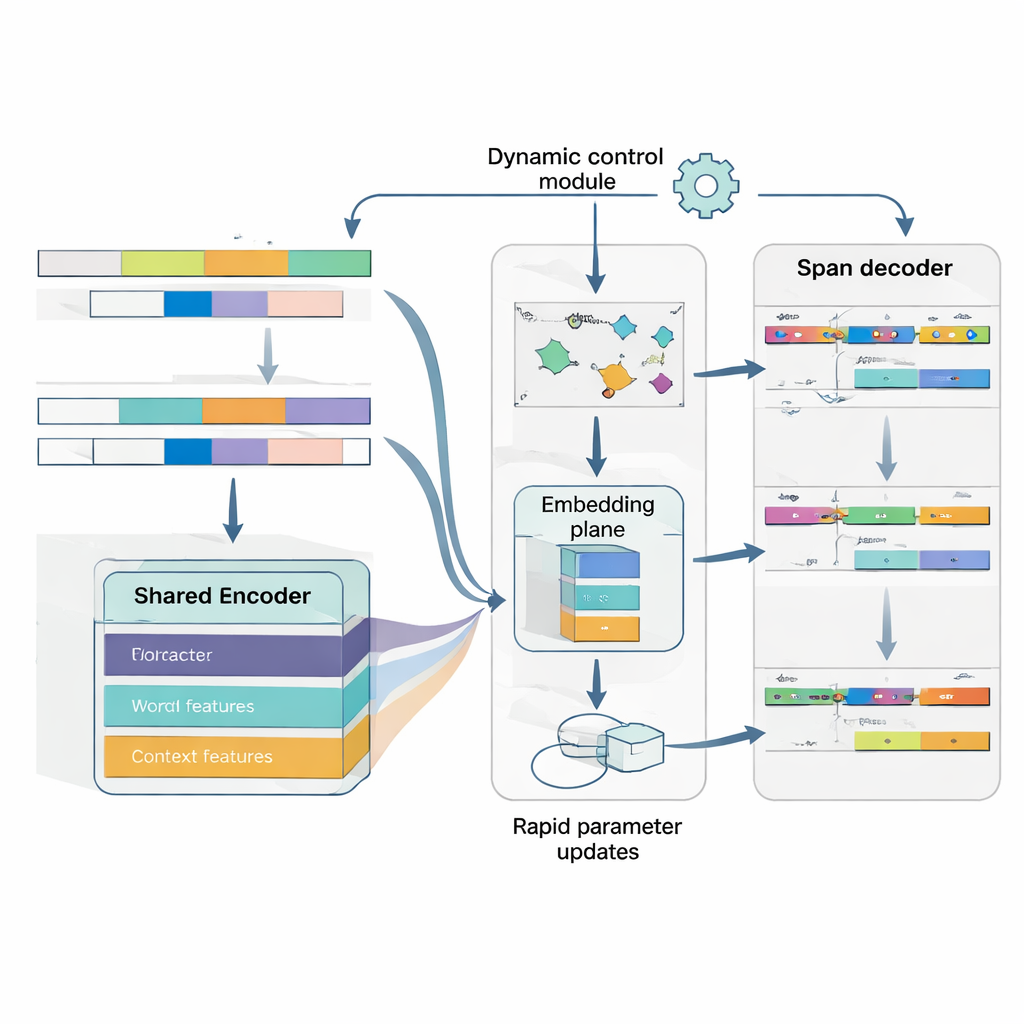
MAML‑ProtoNet++ の中核は「学び方を学ぶ」戦略です。巨大なデータセットで一度だけ訓練するのではなく、少ショット状況を模した多数の小さなタスクで練習し、少数のラベル付き文と小さなテストセットから素早く適応できるようにします。二つの既知の考え方を組み合わせます。一つは急速適応成分で、数ステップの勾配更新でパラメータを調整し各タスクに合わせられるようにします。もう一つはプロトタイプベースの成分で、各実体タイプの代表ベクトルを構築し、新しいスパンをそのプロトタイプとの距離で分類します。別の制御ネットワークは、与えられた少数のラベル例からタスクの難易度を評価し、学習率、距離スケール、文字・語・文脈といった異なる特徴レベルの信頼度を自動で調整します。この動的制御により、タスクのばらつきが大きくても安定して効果的に学習できます。
実体の位置と種類の両方を同時に理解する
最後に、モデルは境界検出とタイプ割当を別々の二段階として扱うのではなく、単一で協調的な問題として扱います。まず文中の実体の開始位置を予測し、その開始位置に条件付けて妥当な終了位置を予測し、得られたスパンを実体タイプへ分類します。重なり得る複数のスパンを考慮できますが、スコアリング規則は最も一貫したスパンを優先します。開始・終了・カテゴリの依存関係を明示的にモデル化することで、入れ子になったり曖昧な実体—日本語でよくある障害—にも対応しやすくなります。共同の損失関数で三つの判断を同時に学習するため、境界精度と最終ラベルの両方が改善されます。
実用上の意味
各実体タイプ当たり5例のみのシミュレーションを行う複数の日本語ベンチマークで評価した結果、MAML‑ProtoNet++ は標準的なファインチューニング、従来のメタ学習法、単独のコントラスト学習を含む強力なベースラインを上回りました。最も厳しい設定でマクロF1は約0.77に達し、実体の開始・終了位置を正確に当てる性能も特に高くなっています。また、主要な再訓練を行わずにバイオメディカルやニュースなど新しいドメインへもうまく転移します。一般読者への要点は、著者らがわずかな指導からでも日本語テキスト中の名前や重要語を見つけられる、小型で効率的なシステムを構築したということです。追加の合成例の賢い生成、言語間のヒントの活用、学習過程の動的調整によりそれが可能になっています。
引用: Shao, X., Zhu, D., Liu, Q. et al. A joint span-entity prediction approach with generative and cross-lingual meta-learning for low-resource Japanese NER. Sci Rep 16, 10281 (2026). https://doi.org/10.1038/s41598-026-41621-0
キーワード: 日本語固有表現認識, 少ショット学習, クロスリンガルNLP, メタ学習, データ拡張